04
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
3.x版本系列:基于JDK1.8开发的,较其他两个版本而言,在功能和优化方面发生了很大的变化,其中包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化等。
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog,FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据,操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
名称节点类似于数据目录。其主要有两大构件构成,FsImage和Editlog,FsImage用于存储元数据(长时间不更新、Editlog用于更新数据,但是随着时间推移,Editlog内存储的数据越来越多,导致运行速度越来越慢。所以引入第二名称节点,当第一节点中Editlog到一个临界值时,HDFS会暂停服务,由第二节点将拷贝出Editlog,复制、添加到Fslmage后方并清空原Editlog的内容。这里有一点要注意这种备份是冷备份的形式,即没有实时性,需要停止服务,等数据恢复正常后继续使用。
1.数据类型:Hbase只有简单的数据类型,只保留字符串;传统数据库有丰富的数据类型。
2.数据操作:Hbase只有简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系;传统数据库通常有各式各样的函数和连接操作。
3.存储模式:Hbase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的,这样的好处是数据即是索引,访问查询涉及的列大量降低系统的I/O,并且每一列由一个线索来处理,可以实现查询的并发处理;传统数据库是基于表格结构和行存储,其没有建立索引将耗费大量的I/O并且建立索引和物化试图需要耗费大量的时间和资源。
4.数据维护:Hbase的更新实际上是插入了新的数据;传统数据库只是替换和修改。
5.可伸缩性:Hbase可以轻松的增加或减少硬件的数目,并且对错误的兼容性比较高;传统数据库需要增加中间层才能实现这样的功能。
6.事务:Hbase只可以实现单行的事务性,意味着行与行之间、表与表之前不必满足事务性;传统数据库是可以实现跨行的事务性。
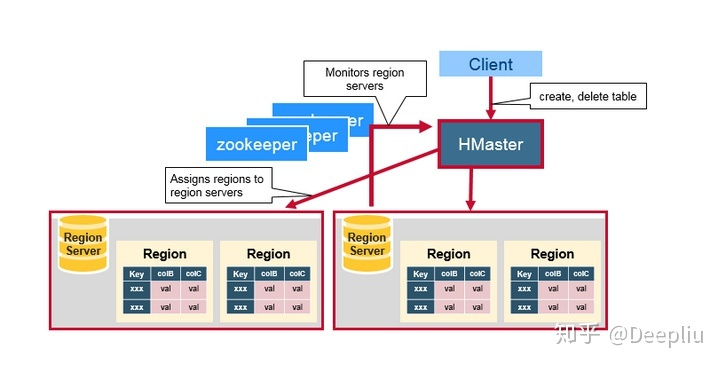
HBase由三种类型的服务器以主从模式构成:
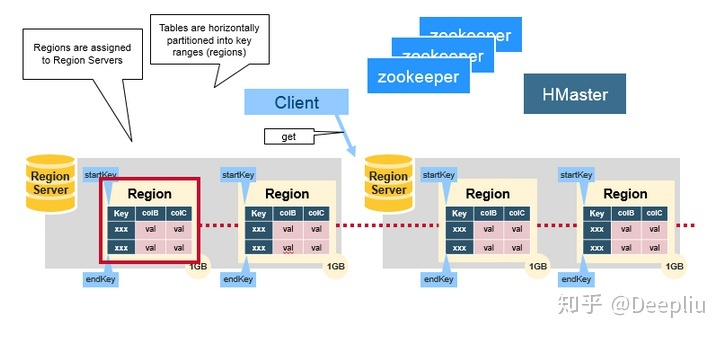
- Region Server:负责数据的读写服务,用户通过与Region server交互来实现对数据的访问。
- HBase HMaster:负责Region的分配及数据库的创建和删除等操作。
- ZooKeeper:负责维护集群的状态(某台服务器是否在线,服务器之间数据的同步操作及master的选举等)。
HDFS的DataNode负责存储所有Region Server所管理的数据,即HBase中的所有数据都是以HDFS文件的形式存储的。出于使Region server所管理的数据更加本地化的考虑,Region server是根据DataNode分布的。HBase的数据在写入的时候都存储在本地。但当某一个region被移除或被重新分配的时候,就可能产生数据不在本地的情况。这种情况只有在所谓的compaction之后才能解决。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号