
9、DolphinScheduler工作流调度引擎_1
一、DS概述
1、DS是什么

官网:https://dolphinscheduler.apache.org/en-us/index.html
logo:

跟Azkaban等流⾏的⼯工作流调度引擎⽐比较如下:
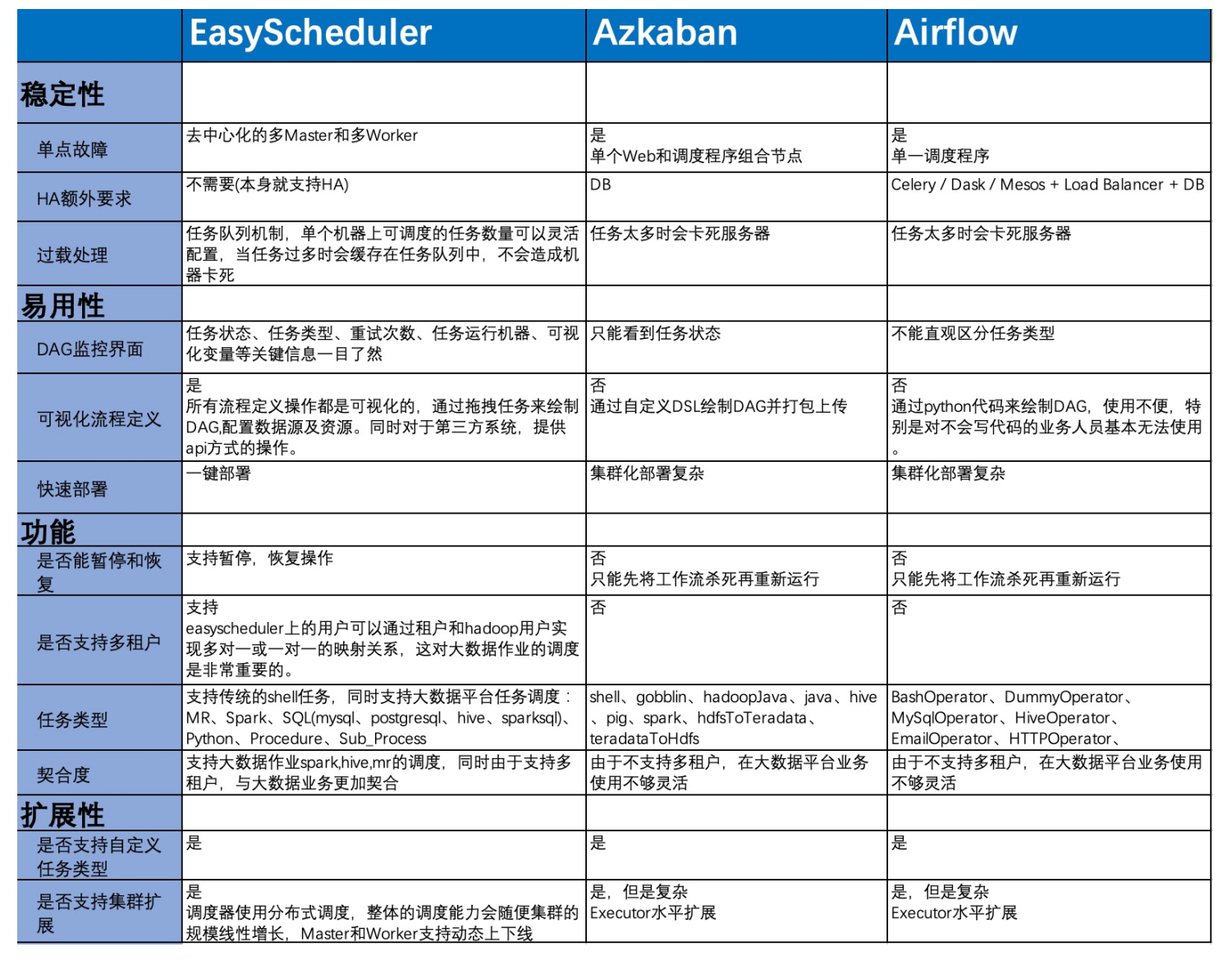
2、特性


![]()
3、谁在使用
二、DS源码编译
1、版本规划
DS在成为Apache孵化项⽬目之后发布了一个版本即1.2.0,并提供了了Flink的⽀支持,我们就尝试使⽤用1.2.0即可:
https://github.com/apache/dolphinscheduler/releases?page=3
2、克隆代码
git clone https://github.com/apache/incubator-dolphinscheduler.git
3、适配HDP3.1
DS依赖于Hadoop、 Hive的客户端,因此需要跟HDP整合,索性在1.2.0-release分支的基础上创建HDP分支,然后再编译。
创建HDP分支
cd incubator-dolphinscheduler git checkout 1.2.0-release git checkout -b 1.2.0-hdp3.1.4.0
然后通过idea把加载工程项目
4、匹配HDP3.1.4.0
修改顶层pom.xml文件
<!--<hadoop.version>2.7.3</hadoop.version>--> <hadoop.version>3.1.1</hadoop.version> <!--<hive.jdbc.version>2.1.0</hive.jdbc.version>--> <hive.jdbc.version>3.1.0</hive.jdbc.version>
变更更版本号
修改所有模块的pom.xml
<!-- <version>1.2.1-SNAPSHOT</version>--> <version>1.2.0-hdp3.1.4.0</version>
5、编译安装包
mvn -U clean package -Prelease -Dmaven.test.skip=true

可以看到报错了,说什么内存不足,我尝试过各种调参什么的,发现并没有什么卵用,然后把HDP集群的三台虚拟机直接关了,这个时候编译就没有问题了,
其实本质原因就是笔记的内存已经达到上限了。
编译完成后
同样的道理,我们把代码放到centos7下环境进行编译,如何在centos7环境下安装maven我这里不多说了,网上的教程有很多,配置文档的修改跟前面一样
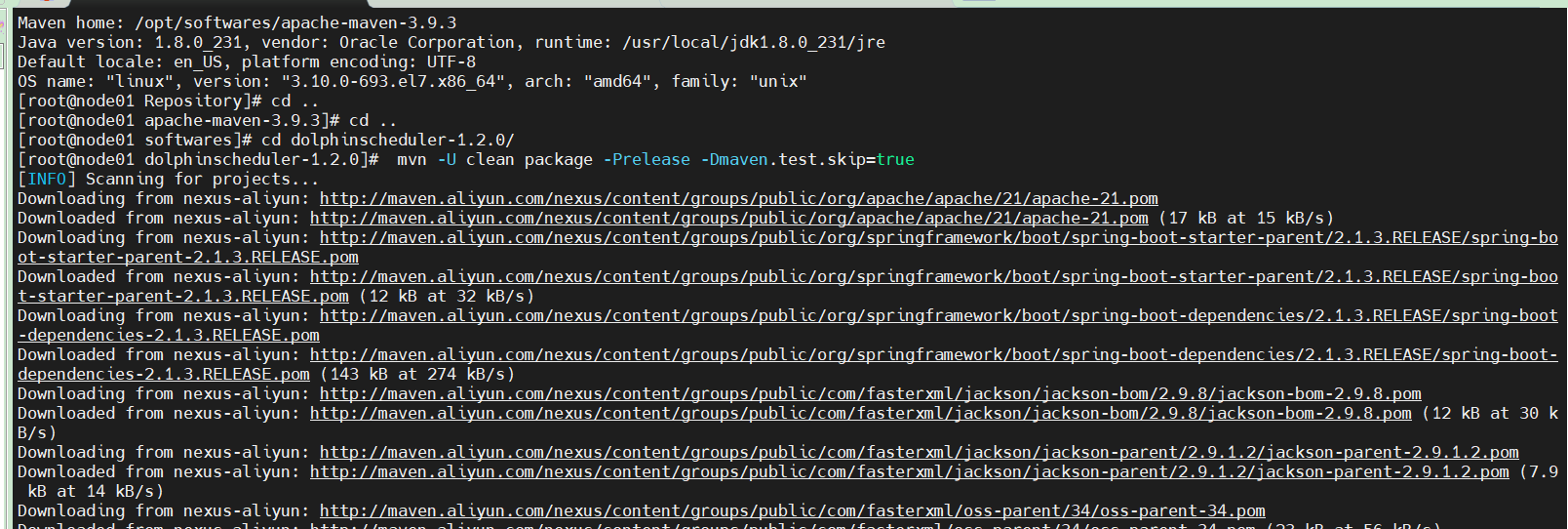
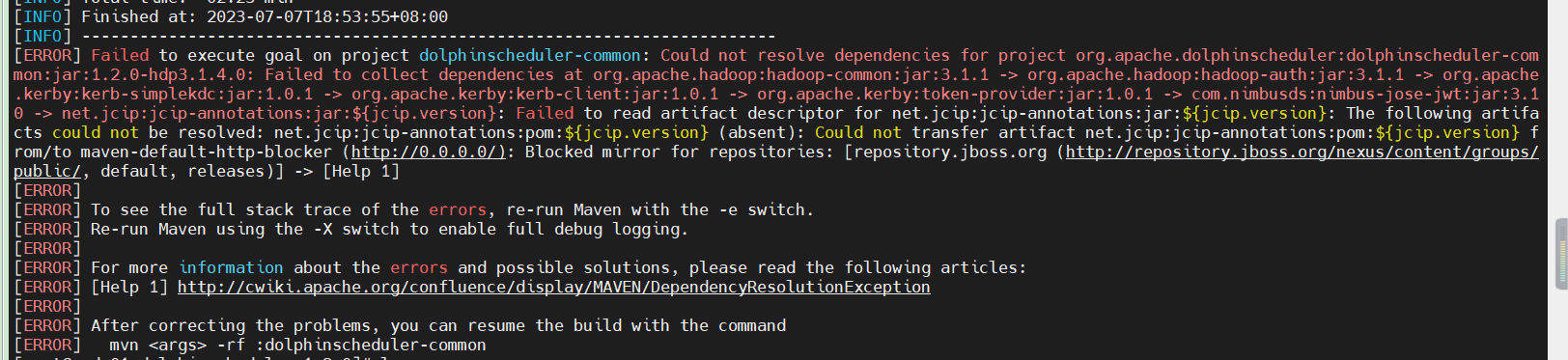
针对这个问题,我一开始以为是网络,maven的源的问题,各种排查后一直都解决不了,仔细阅读报错的日志,jcip-annotations 的¥{jcip.verion}这个版本是无法找到的,
排查,从工程dolphinscheduler-common模块的pom文件,发现里面没有jcip相关的依赖,这个时候应该想到父工程的pom文件了,结果,问题就在这里
我们通过文本编辑器打开pom文件,发现这就是问题的关键点
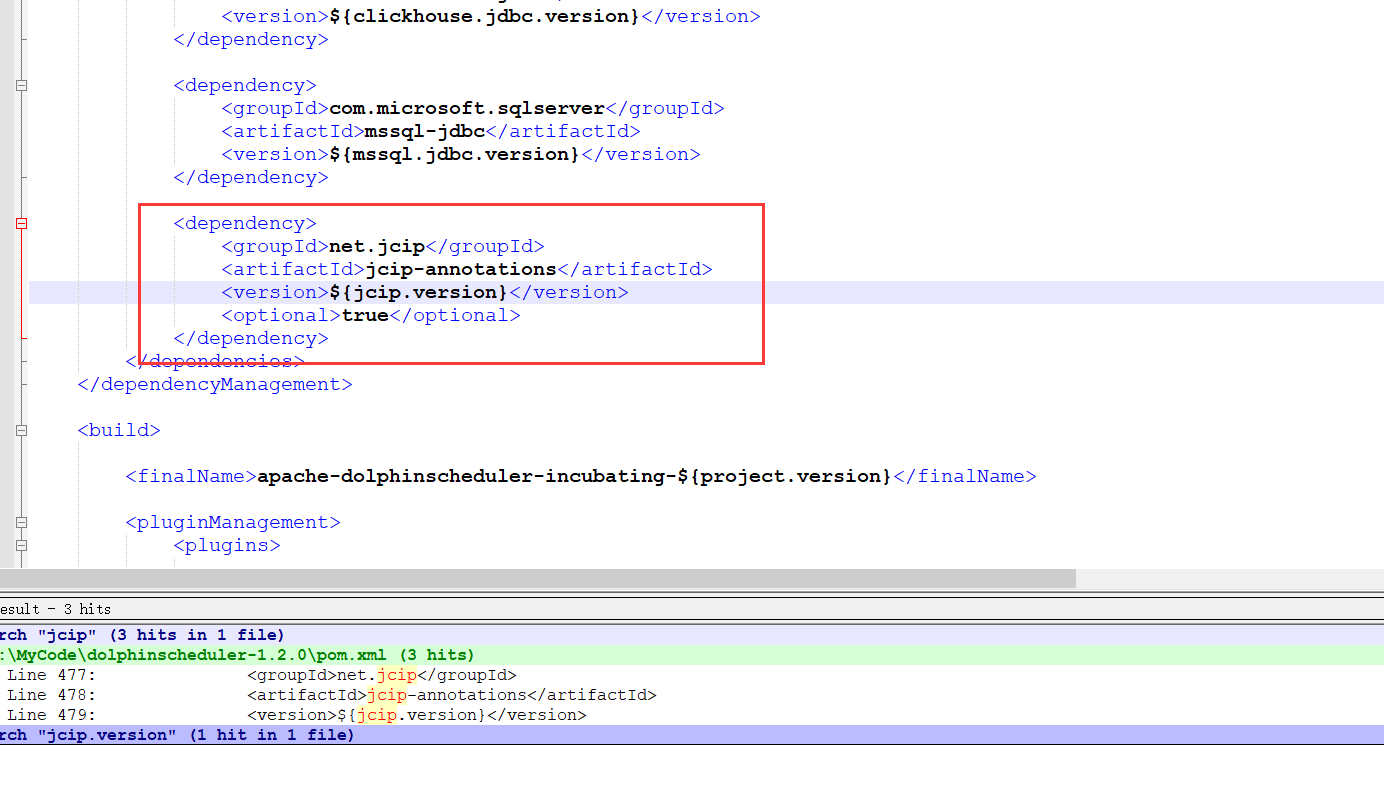
<version>${jcip.version}</version>在前面根本就没有指定版本,所以肯定编译是有问题的,但是为什么前面在windows的IDEA里面编译又成功,这个我也不知道了,既然我们的包是在centos环境
下跑的,我个人建议还是基于centos7的环境编译生产的包,起码保证这样环境编译出来的包能在该环境下运行。
经过到maven仓库里查看 jcip-annotations相关的,目前只有1.0版本的
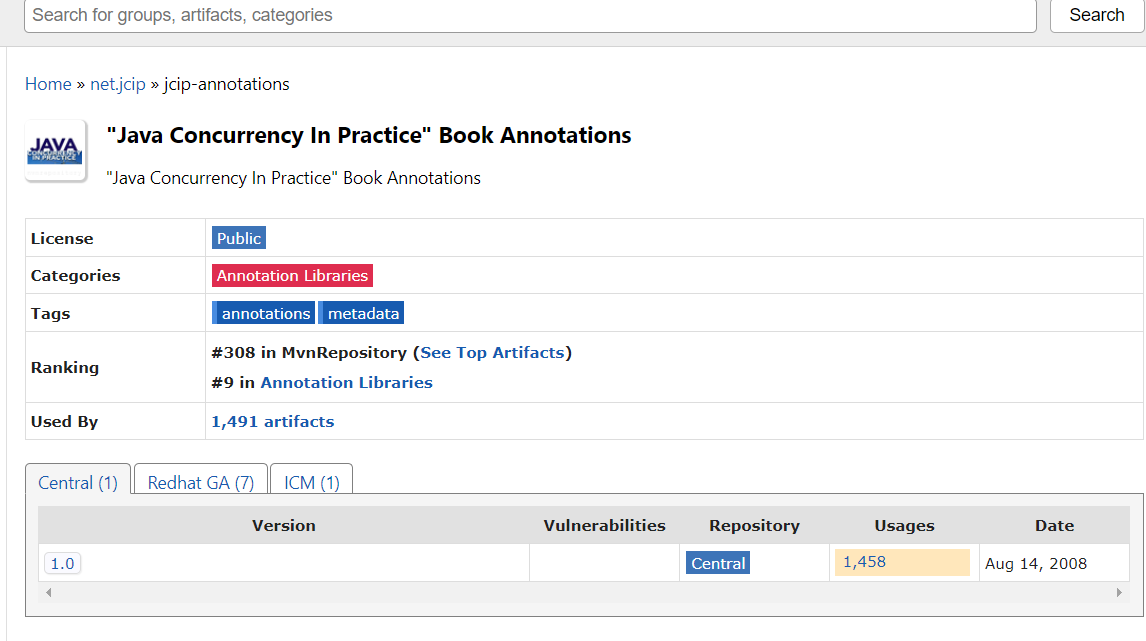
可以说也是dolphinscheduler 1.2.0版本的一个bug吧,不懂后面的版本修复了没有,我们直接把版本号修改成1.0即可

在centos7环境下我们再进行编译
mvn -U clean package -Prelease -Dmaven.test.skip=true
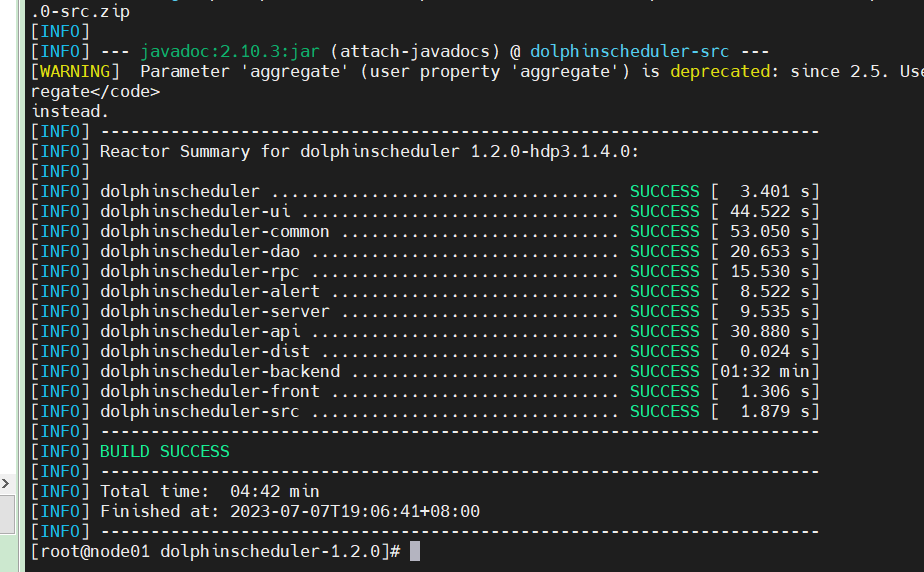
可以看到成功了!!!
三、DS快速安装
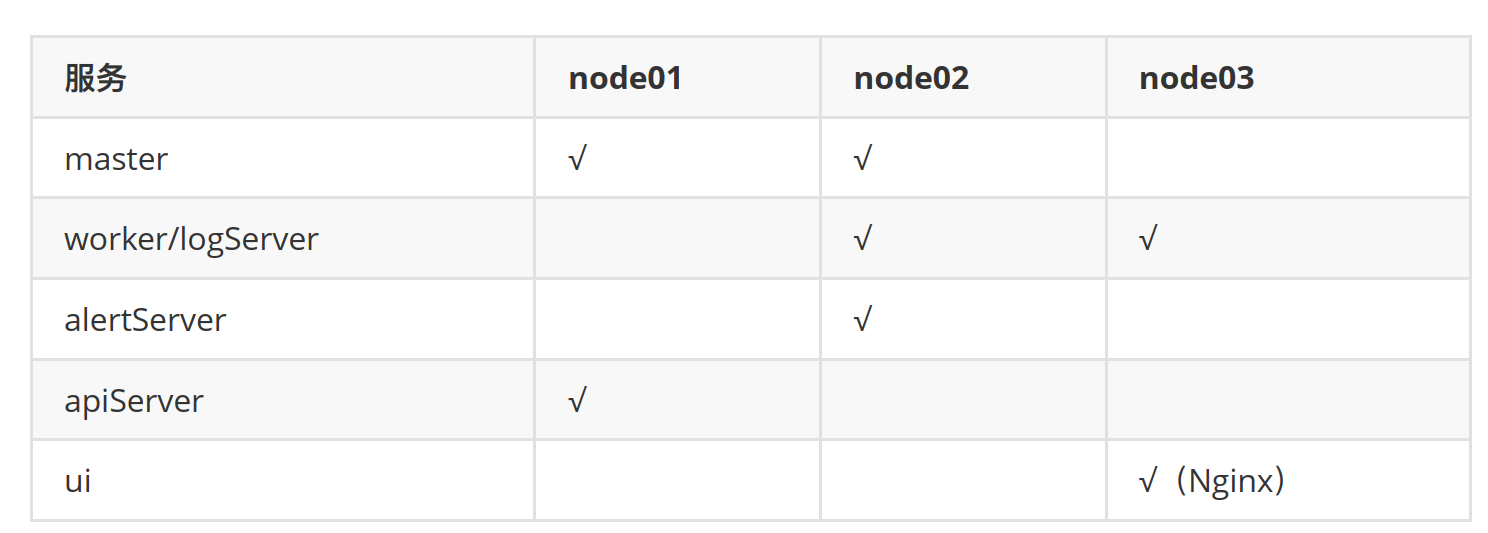
1、规划部署
2、依赖组件安装
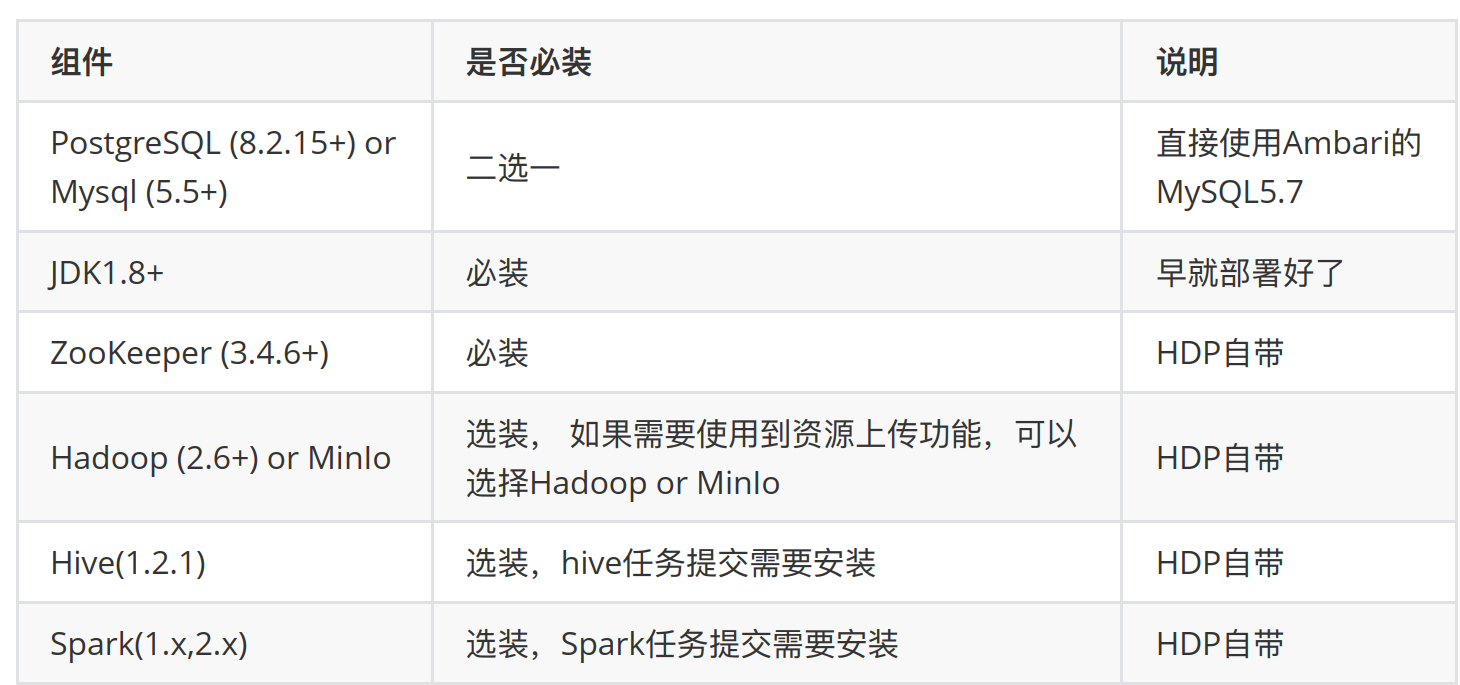
注意: HDP3.1⾃自带的Hadoop、 Hive、 Spark跟DS需要的不不⼀一样,因此需要按照前面的DS源码编译来处理理
3、创建部署⽤用户及SSH免密
在所有需要部署调度的机器器上创建部署⽤用户,因为worker服务是以 sudo -u {linux-user} ⽅方式来执⾏行行作
业,所以部署⽤用户需要有 sudo 权限,⽽而且是免密的。
我们直接采⽤用hadoop⽤用户就好了了,免密早就做好了。
4、创建数据库
在MySQL部署的那台机器器上:
mysql -uroot -p
set global validate_password_policy=0; set global validate_password_mixed_case_count=0; set global validate_password_number_count=3; set global validate_password_special_char_count=0; set global validate_password_length=3; CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; CREATE USER 'ds'@'%' IDENTIFIED BY 'ds%123'; GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'ds'@'%' IDENTIFIED BY 'ds%123'; flush privileges; exit;

5、pip、 kazoo 安装
sudo yum -y install epel-release sudo yum -y install python-pip pip --version sudo pip install kazoo
kazoo是⼀一个Python库,旨在使得Python能够轻松、便便捷的使⽤用zookeeper。
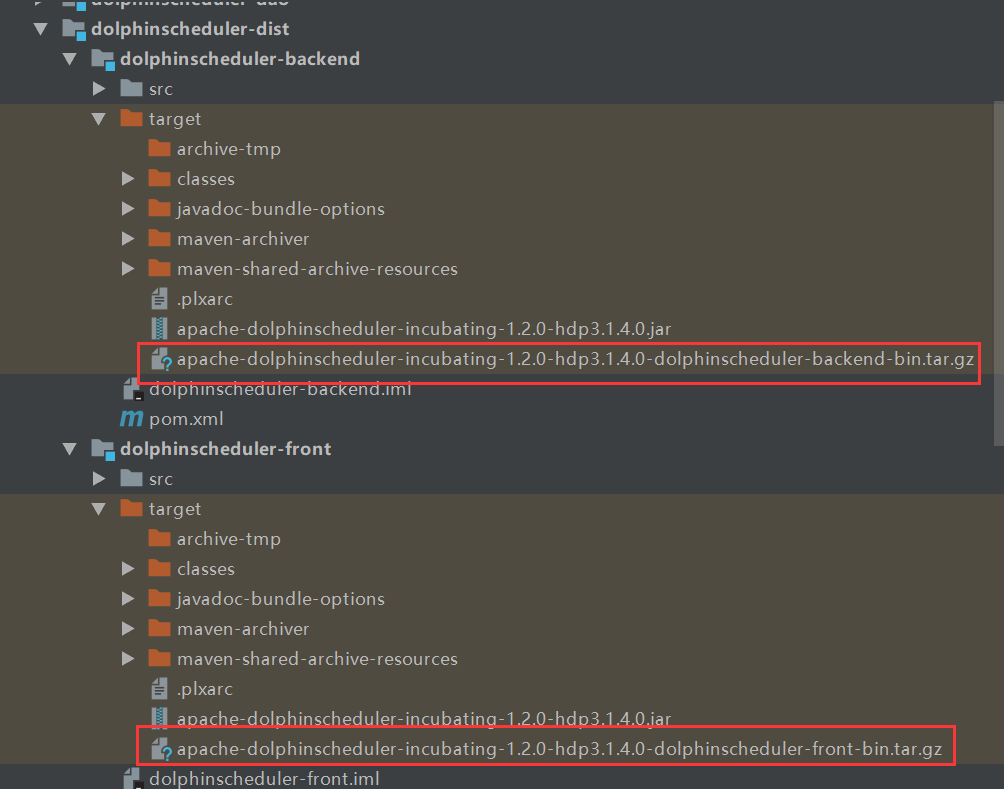
6、上传后端安装包到hadoop⽤用户主⽬目录下
cp apache-dolphinscheduler-incubating-1.2.0-hdp3.1.4.0-dolphinscheduler-backend-bin.tar.gz /home/hadoop/app/ tar -zxf apache-dolphinscheduler-incubating-1.2.0-hdp3.1.4.0-dolphinscheduler-backend-bin.tar.gz ln -s apache-dolphinscheduler-incubating-1.2.0-hdp3.1.4.0-dolphinscheduler-backend-bin ds-backend chmod ugo+x ds-backend/bin/* chmod ugo+x ds-backend/script/* chmod ugo+x ds-backend/install.sh chmod ugo+x /home/hadoop/app/ds-backend/conf/env/.dolphinscheduler_env.sh

7、数据库配置
vim /home/hadoop/app/ds-backend/conf/application-dao.properties
#spring.datasource.driver-class-name=org.postgresql.Driver #spring.datasource.url=jdbc:postgresql://192.168.xx.xx:5432/dolphinscheduler # mysql spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://node01:3306/dolphinscheduler? useUnicode=true&characterEncoding=UTF-8 spring.datasource.username=ds spring.datasource.password=ds%123
8、初始化数据库
cd /home/hadoop/app/ds-backend/lib/ ln -s /usr/share/java/mysql-connector-java-8.0.18.jar mysql-connector-java-8.0.18.jar cd /home/hadoop/app/ds-backend sh ./script/create-dolphinscheduler.sh
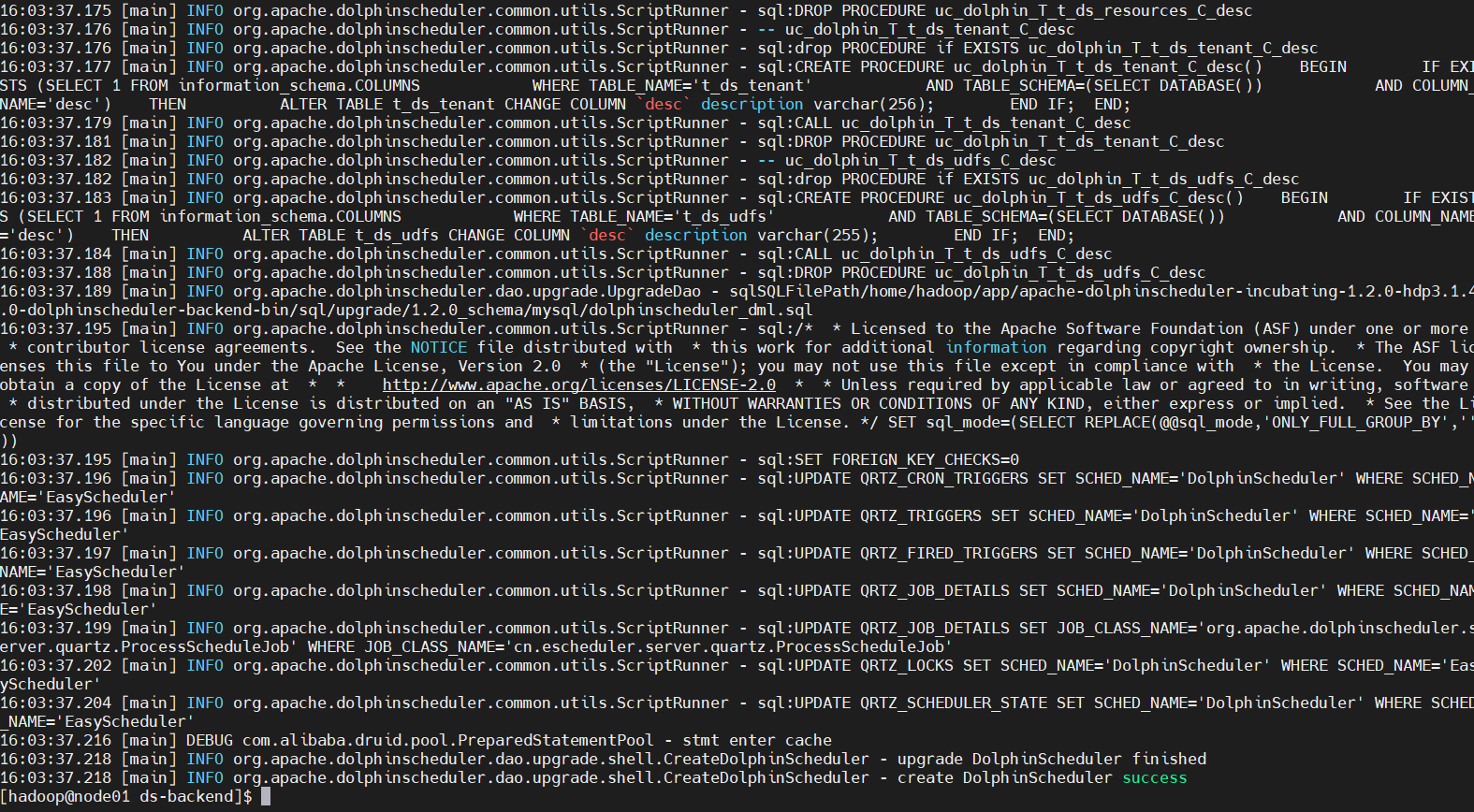
9、配置DS环境变量量⽂文件
vim /home/hadoop/app/ds-backend/conf/env/.dolphinscheduler_env.sh
export HADOOP_HOME=/usr/hdp/current/hadoop-client export HADOOP_CONF_DIR=/etc/hadoop/conf #export SPARK_HOME1=/opt/soft/spark1 export SPARK_HOME2=/usr/hdp/current/spark2-client export PYTHON_HOME=/usr/bin/python export JAVA_HOME=/usr/local/jdk export HIVE_HOME=/usr/hdp/current/hive-client #export FLINK_HOME=/opt/soft/flink export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$PATH
10、集群部署参数配置
vim /home/hadoop/app/ds-backend/install.sh
# for example postgresql or mysql ... dbtype="mysql" # db config # db address and port dbhost="node01:3306" # db name dbname="dolphinscheduler" # db username username="ds" # db passwprd # Note: if there are special characters, please use the \ transfer character to transfer passowrd="ds%123" # conf/config/install_config.conf config # Note: the installation path is not the same as the current path (pwd) installPath="/ds" # deployment user # Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself deployUser="hadoop" # zk cluster zkQuorum="node01:2181" # install hosts # Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname ips="node01,node02,node03" # conf/config/run_config.conf config # run master machine # Note: list of hosts hostname for deploying master masters="node01,node02" # run worker machine # note: list of machine hostnames for deploying workers workers="node02,node03" # run alert machine # note: list of machine hostnames for deploying alert server alertServer="node02" # run api machine # note: list of machine hostnames for deploying api server apiServers="node01" # alert config # mail protocol mailProtocol="SMTP" # mail server host mailServerHost="smtp.exmail.qq.com" # mail server port mailServerPort="25" # sender mailSender="810905729@qq.com" # user mailUser="djt" # sender password mailPassword="" # TLS mail protocol support starttlsEnable="false" sslTrust="uaxaufhjjxzvbgjh" # SSL mail protocol support # note: The SSL protocol is enabled by default. # only one of TLS and SSL can be in the true state. sslEnable="true" # download excel path xlsFilePath="/tmp/xls" # Enterprise WeChat Enterprise ID Configuration enterpriseWechatCorpId="xxxxxxxxxx" # Enterprise WeChat application Secret configuration enterpriseWechatSecret="xxxxxxxxxx" # Enterprise WeChat Application AgentId Configuration enterpriseWechatAgentId="xxxxxxxxxx" # Enterprise WeChat user configuration, multiple users to , split enterpriseWechatUsers="xxxxx,xxxxx" # alert port alertPort=7789 # whether to start monitoring self-starting scripts monitorServerState="true" # resource Center upload and select storage method:HDFS,S3,NONE resUploadStartupType="HDFS" # if resUploadStartupType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory. # if S3,write S3 address,HA,for example :s3a://dolphinscheduler, # Note,s3 be sure to create the root directory /dolphinscheduler defaultFS="hdfs://node01:8020" # if S3 is configured, the following configuration is required. s3Endpoint="http://192.168.xx.xx:9010" s3AccessKey="xxxxxxxxxx" s3SecretKey="xxxxxxxxxx" # resourcemanager HA configuration, if it is a single resourcemanager, here is yarnHaIps="" yarnHaIps="" # if it is a single resourcemanager, you only need to configure one host name. If it is resourcemanager HA, the default configuration is fine. singleYarnIp="node01" # hdfs root path, the owner of the root path must be the deployment user. # versions prior to 1.1.0 do not automatically create the hdfs root directory, you need to create it yourself. hdfsPath="/dolphinscheduler" # have users who create directory permissions under hdfs root path / # Note: if kerberos is enabled, hdfsRootUser="" can be used directly. hdfsRootUser="hdfs"
特别注意: installPath千万不不要指定某个⽤用户主⽬目录下的⽬目录,例如/home/hadoop/app/ds就不不可以。
因为最终worker会以“sudo -u 租户 sh xxx.command”⽅方式去执⾏行行脚本,⽽而每个脚本会执⾏行行如下命令:
source /home/hadoop/app/ds/conf/env/.dolphinscheduler_env.sh
如果你以hdfs⽤用户去执⾏行行,显然各级⽗父⽬目录都是没有权限的/home/hadoop/app/ds/conf/env/,即
使.dolphinscheduler_env.sh的权限是777也⽆无济于事。
因此推荐设置为:
installPath="/ds"
目录不不⽤用提前创建, ds会使⽤用sudo权限创建的。
11、添加Hadoop配置⽂文件
若 install.sh 中, resUploadStartupType 为 HDFS,则需要拷⻉贝hdfs-site.xml和core-site.xml到conf目录下
cp /etc/hadoop/conf/core-site.xml /home/hadoop/app/ds-backend/conf/
cp /etc/hadoop/conf/hdfs-site.xml /home/hadoop/app/ds-backend/conf/
12、修改JVM参数
vim /home/hadoop/app/ds-backend/bin/dolphinscheduler-daemon.sh
vim /home/hadoop/app/ds-backend/script/dolphinscheduler-daemon.sh
最前面添加:
export JAVA_HOME=/usr/local/jdk
根据自己的机器调整JVM内存:
export DOLPHINSCHEDULER_OPTS="-server -Xmx4g -Xms2g -Xss512k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70"
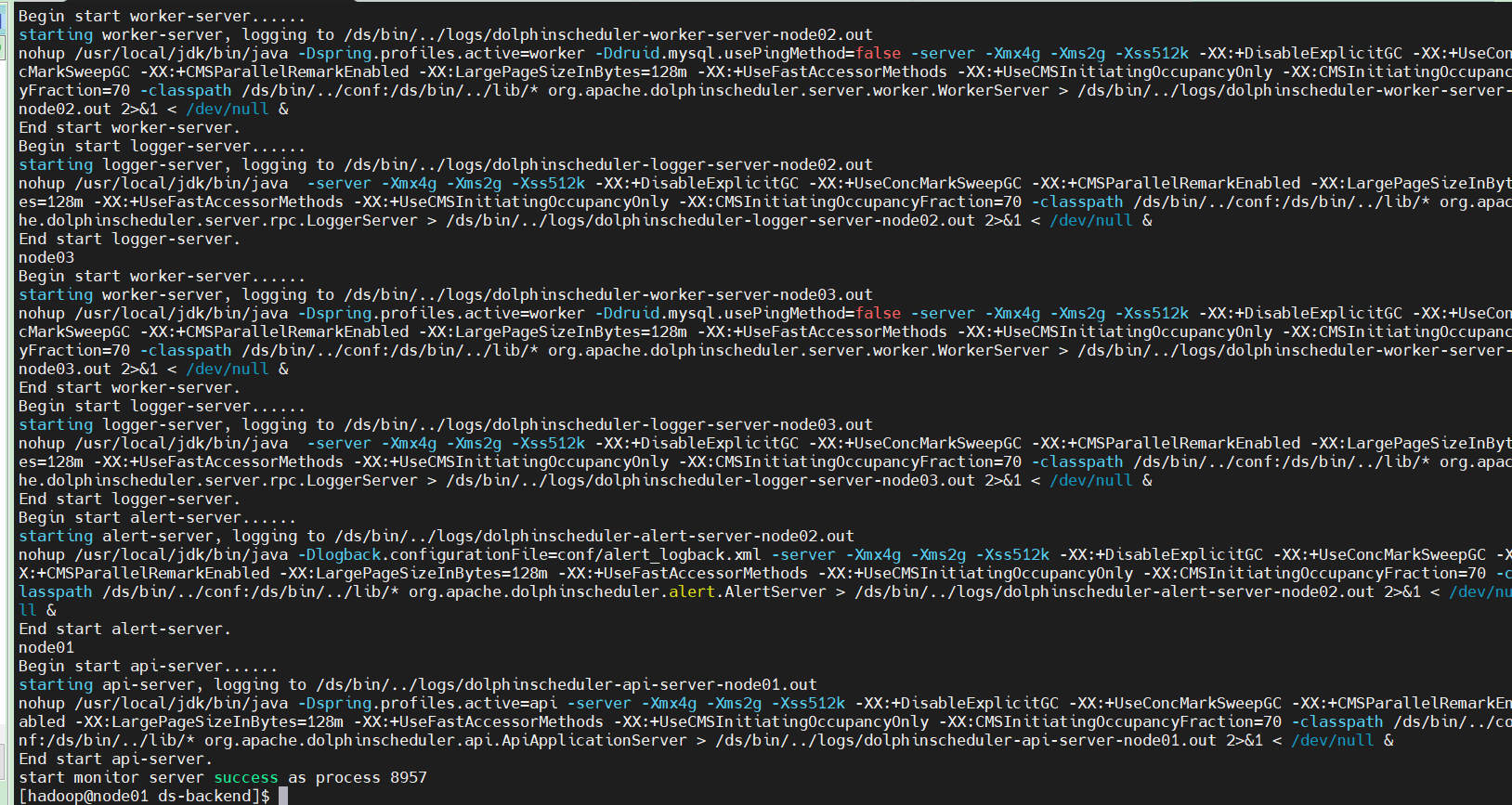
13、一键部署
cd /home/hadoop/app/ds-backend/
./install.sh
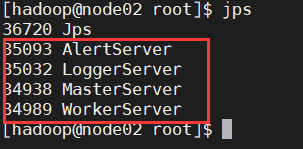
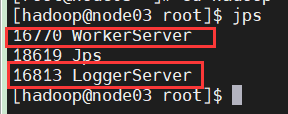
14、检查进程

15、服务启停
一键停止集群所有服务
sh ./bin/stop-all.sh
一键开启集群所有服务
sh ./bin/start-all.sh
通过单个服务逐个启动
启停master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server
启停worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server
启停api
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server
启停Logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server
启停Alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server
16、前端部署
前端部署官方文档没有问题,可参考官方文档
https://dolphinscheduler.apache.org/zh-cn/docs/user_doc/frontend-deployment.html
前端安装包
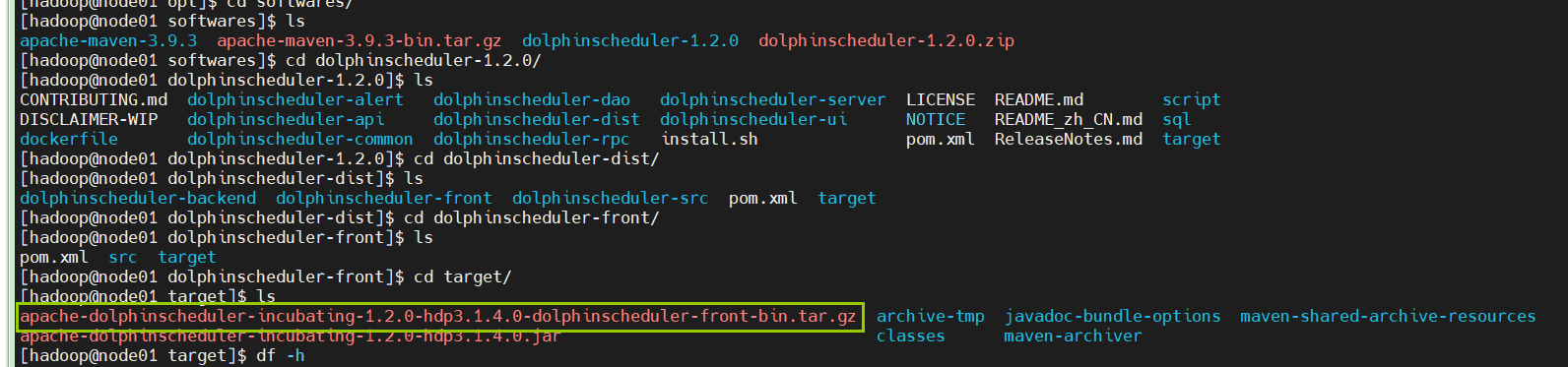
按照规划我们在node03部署ds前端,因此首先把前端安装包上传到node03的hadoop用户主目录app

tar -zxf apache-dolphinscheduler-incubating-1.2.0-hdp3.1.4.0-dolphinscheduler-front-bin.tar.gz
cd apache-dolphinscheduler-incubating-1.2.0-hdp3.1.4.0-dolphinscheduler-front-bin/
sudo cp -r dist/ /usr/share/nginx/html
最终ds前端的静态文件在:
/usr/share/nginx/html/dist

部署方式选择
DS前端部署分自动和手动两种方式:
自动部署脚本会用 yum 安装 Nginx,通过引导设置后的 Nginx 配置文件为
/etc/nginx/conf.d/escheduler.conf。
如果本地已经存在 Nginx,则需手动部署,修改 Nginx 配置文件 /etc/nginx/nginx.conf 首先使用
systemctl status nginx 查看 nginx 状态,若提示 Unit nginx.service could not be foudn. 则推荐
使用自动部署。
本节介绍手工部署,自动部署请参考官方文档。
安装nginx
sudo yum install nginx -y
我这里里之前部署DBus时已经安装了了Nginx所以直接使用即可。
配置server
sudo vim /etc/nginx/nginx.conf
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; client_max_body_size 2000M; keepalive_timeout 65; server { listen 8080; server_name localhost; #charset utf-8; #access_log logs/host.access.log main; location / { root /usr/share/nginx/html/build; index index.html index.htm; try_files $uri /index.html; add_header Cache-Control "private, no-store, no-cache, must-revalidate, proxy-revalidate"; } location /keeper/ { proxy_pass http://192.168.126.13:5090/v1/keeper/; } location /keeper-webSocket/ { proxy_pass http://192.168.126.13:8901/; proxy_read_timeout 60s; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; } } server { listen 8888; server_name localhost; location / { root /usr/share/nginx/html/dist; index index.html index.htm; } location /dolphinscheduler { proxy_pass http://node01:12345; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header x_real_ipP $remote_addr; proxy_set_header remote_addr $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_http_version 1.1; proxy_connect_timeout 4s; proxy_read_timeout 30s; proxy_send_timeout 12s; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } } include /etc/nginx/conf.d/*.conf; }
重启Nginx
sudo systemctl restart nginx
打开浏览器访问地址
http://node03:8888/

DS前端安装成功!!!
四、管理员操作
1、管理员登录
默认用户名密码: admin/dolphinscheduler123
2、修改密码
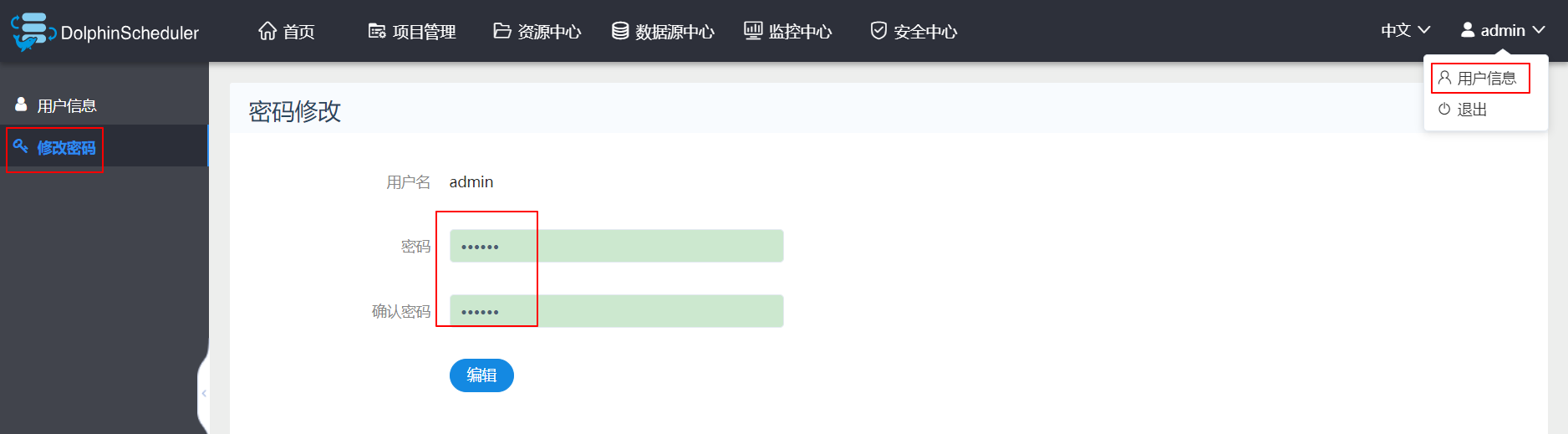
为了方便记忆,我这里把密码修改为666666,密码修改完需要重新登录一次。
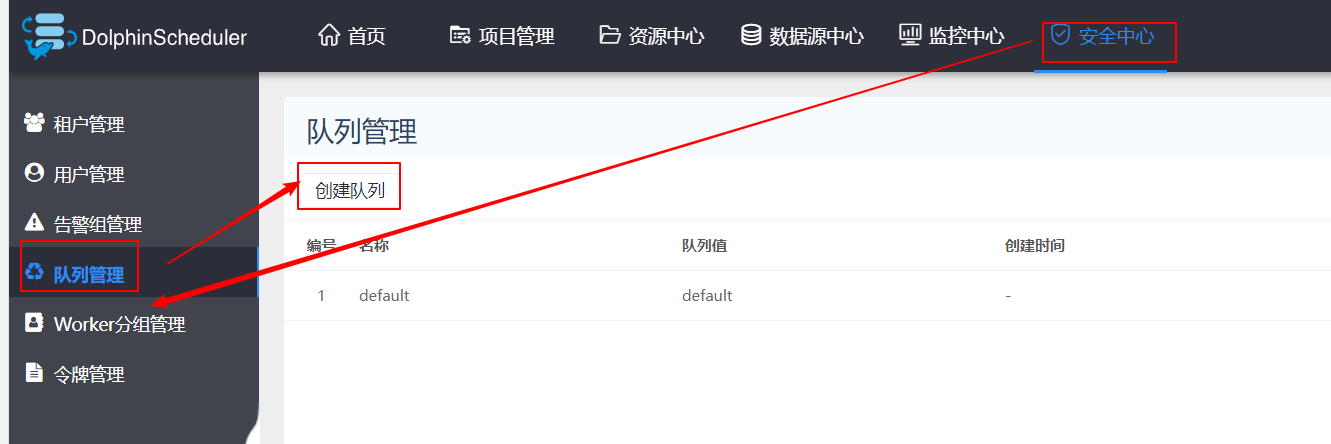
3、创建队列
这里创建的队列在执行 spark、 mapreduce 等程序时作为“队列”参数使用(创建后不可删除)。

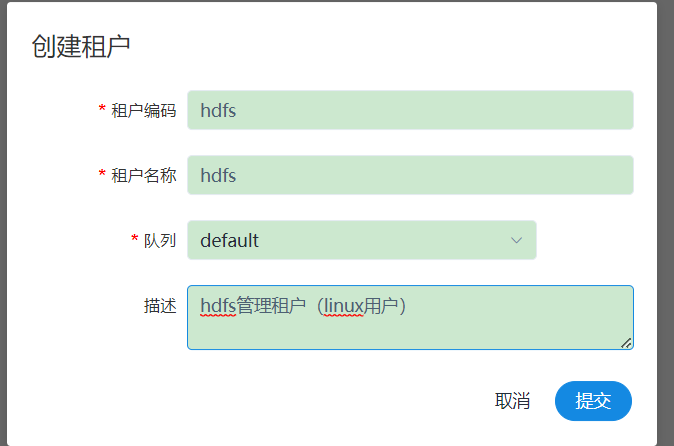
4、创建租户
- 租户对应的是 Linux 的用户,用于 worker 提交作业所使用的用户。如果 Linux 没有这个用户,worker 会在执行脚本的时候创建这个用户。
- 租户编码:是 Linux 上的用户,唯一,不能重复。 新建的租户会在 HDFS 上 $hdfsPath(默认
为: "/dolphinscheduler") 目录下创建租户目录,租户目录下为该租户上传的文件和 UDF 函数。 - 租户名称:租户编码的别名,可以重复,但是建议不要重复,以免混淆
5、创建普通用户
用户指的是DS系统的用户,分为管理员用户和普通用户。此处的普通用户即每个开发人员的登录账户。

6、创建告警组
告警组用于流程启动时设置参数,在流程结束以后会将流程的状态和其他信息以邮件形式发送给告警组
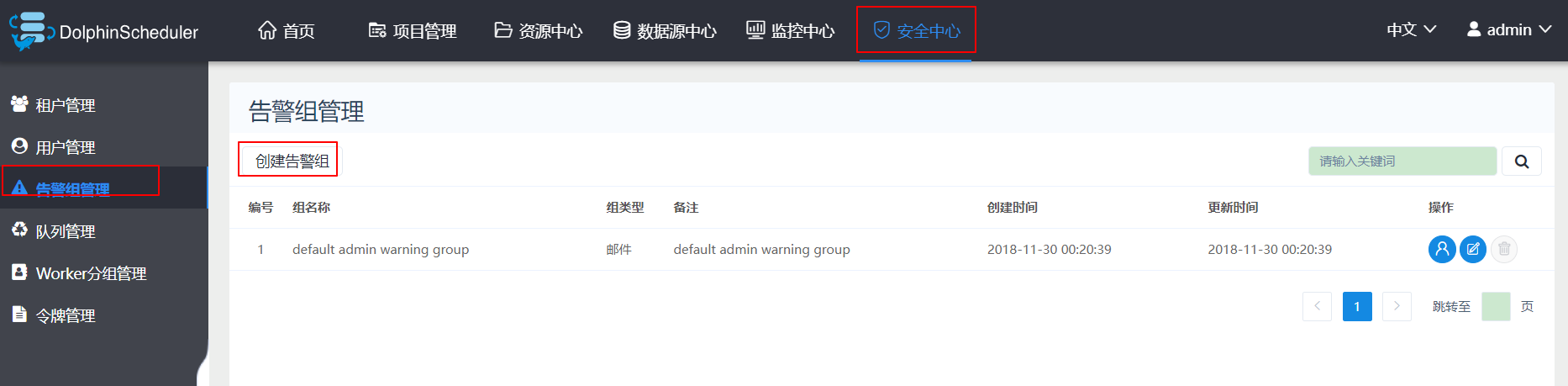

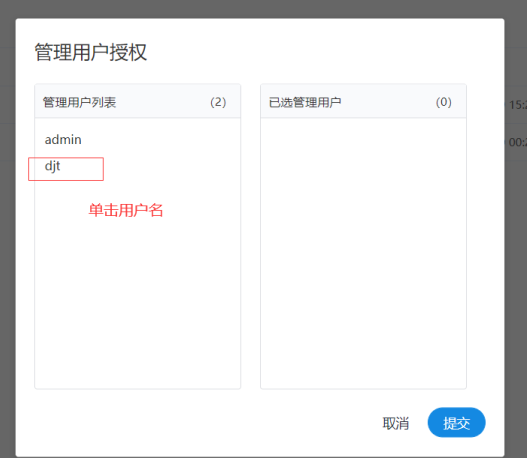
把相关用户加入告警组
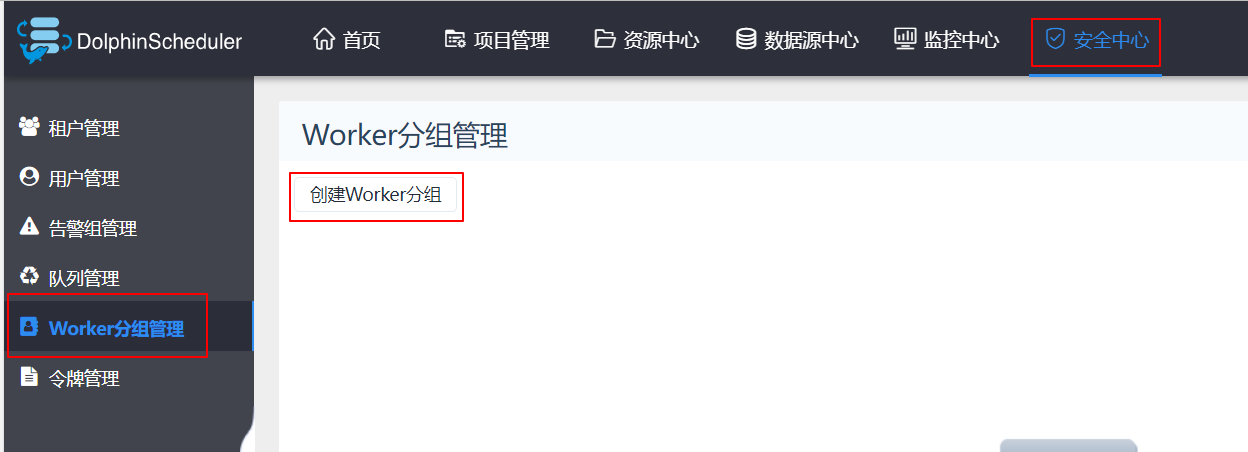
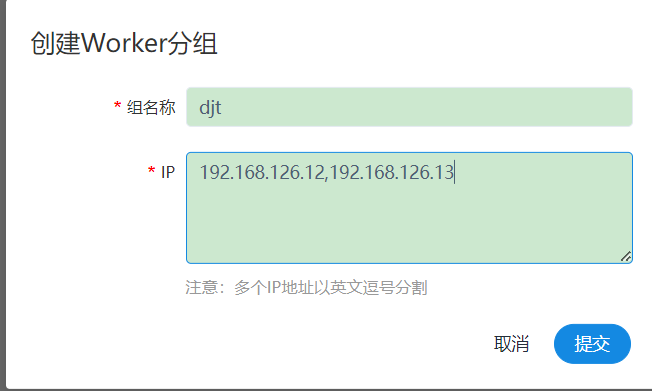
7、创建Woker分组
- worker 分组,提供了一种让任务在指定的 worker 上运行的机制。
- 管理员创建 worker 分组,在任务节点和运行参数设置中可以指定该任务运行的 worker 分组。
- 如果指定的分组被删除或者没有指定分组,则该任务会在任意⼀一个 worker 上运行。 worker 分组内多个 ip 地址(不能写别名),以英文逗号分隔。
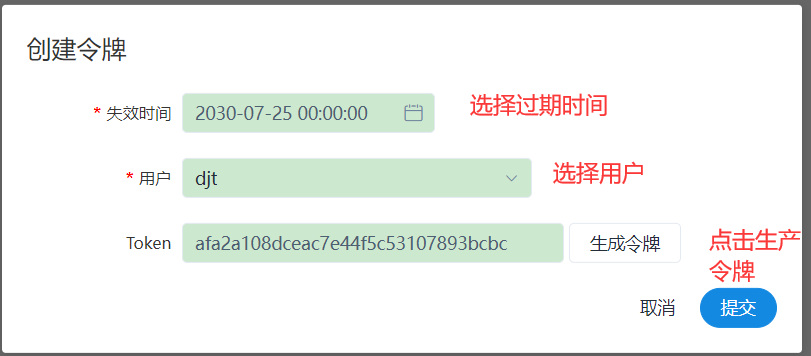
8、创建token令牌
后端接口有登录检查,令牌管理提供了一种可以通过调用接口的方式对系统进行操作的可能。

9、授权


我们在这里不进行授权操作,让用户自己创建各种资源。
五、普通用户操作
1、普通用户登录
退出admin用户,用普通用户djt/djt%123登录,登录后进入用户首页:
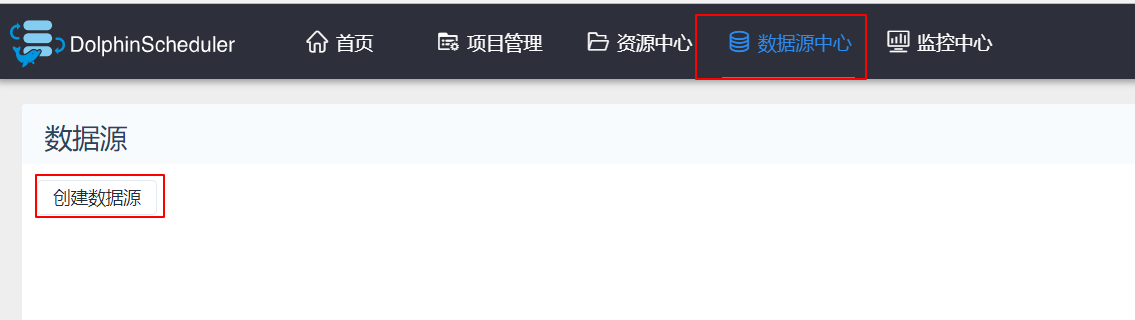
2、创建mysql数据源
DS中工作流处理的数据来自于各种数据源,因此需要提前定义。
这里需要提醒一下,如果需要连接hdp的mysql数据库,就要检查一下是否开放了远程访问权限,如果没有开发该权限就按以下执行:
mysql -u root -p use mysql; GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; flush privileges;
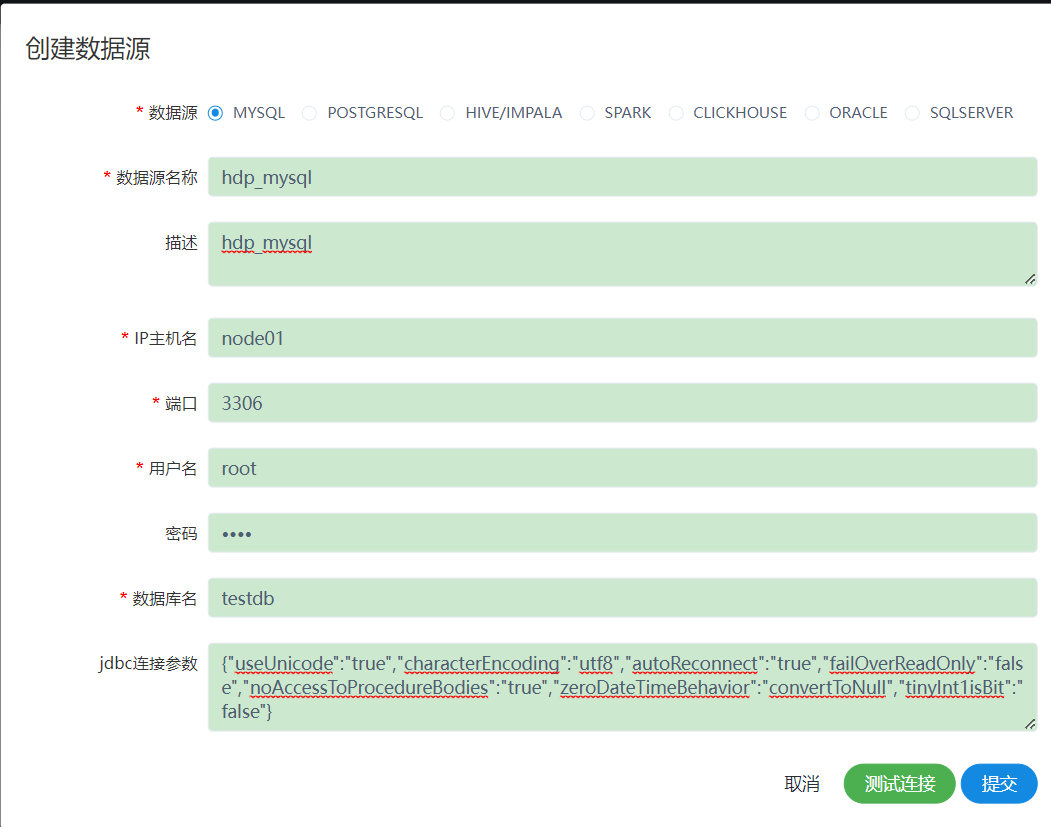
先测试,没问题再保存提交
{"useUnicode":"true","characterEncoding":"utf8","autoReconnect":"true","failOverReadOnly":"false","noAccessToProcedureBodies":"true","zeroDateTimeBehavior":"convertToNull","tinyInt1isBit":"false"}

普通用户自己创建的数据源不需要授权。
2、创建Hive/Impala数据源
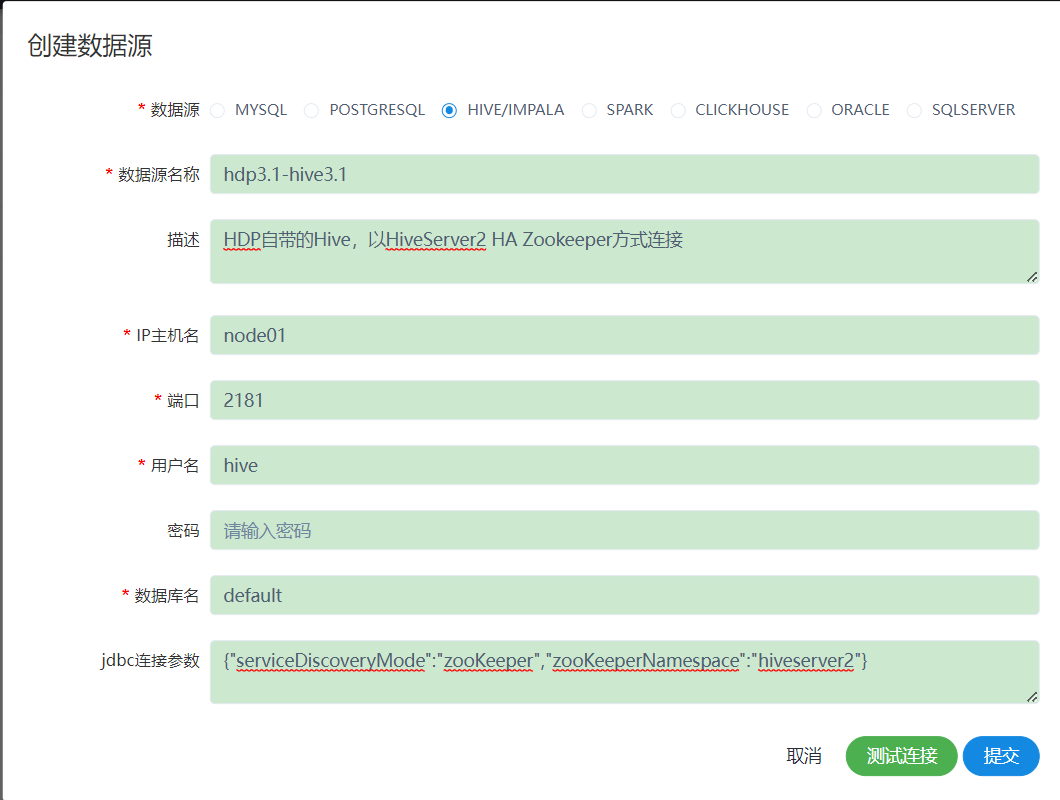
{"serviceDiscoveryMode":"zooKeeper","zooKeeperNamespace":"hiveserver2"}
如果出现hive连接失败的情况,检查一下自己的hdp集群里面的hive zookeeper是否启动,还有就是在hadoop的core-site.xml文件里面添加以下配置
<property>
<name>hadoop.proxyuser.user.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.user.groups</name>
<value>*</value>
</property>

3、创建项目
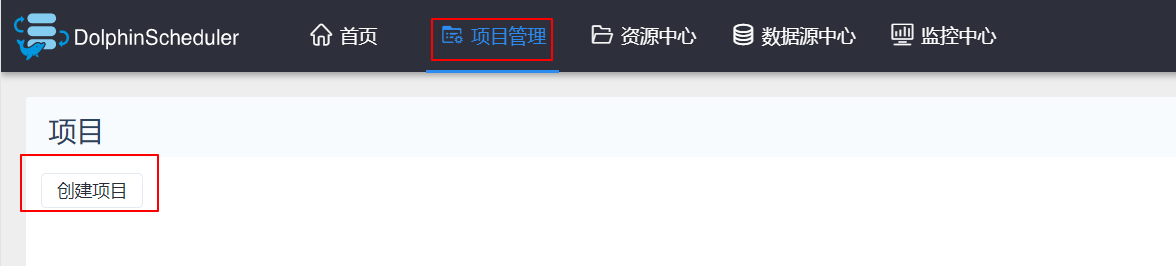


4、定义工作流
首先进入项目主页
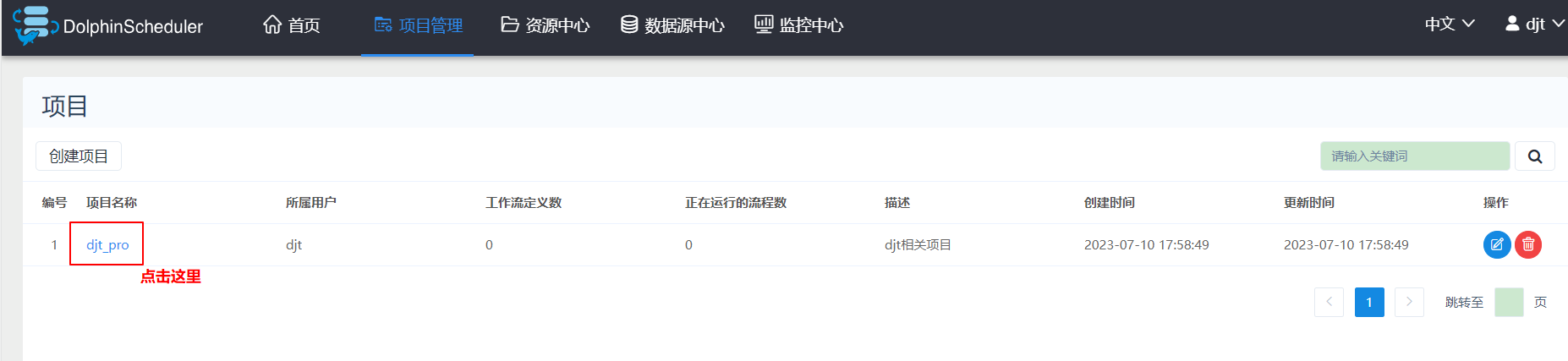
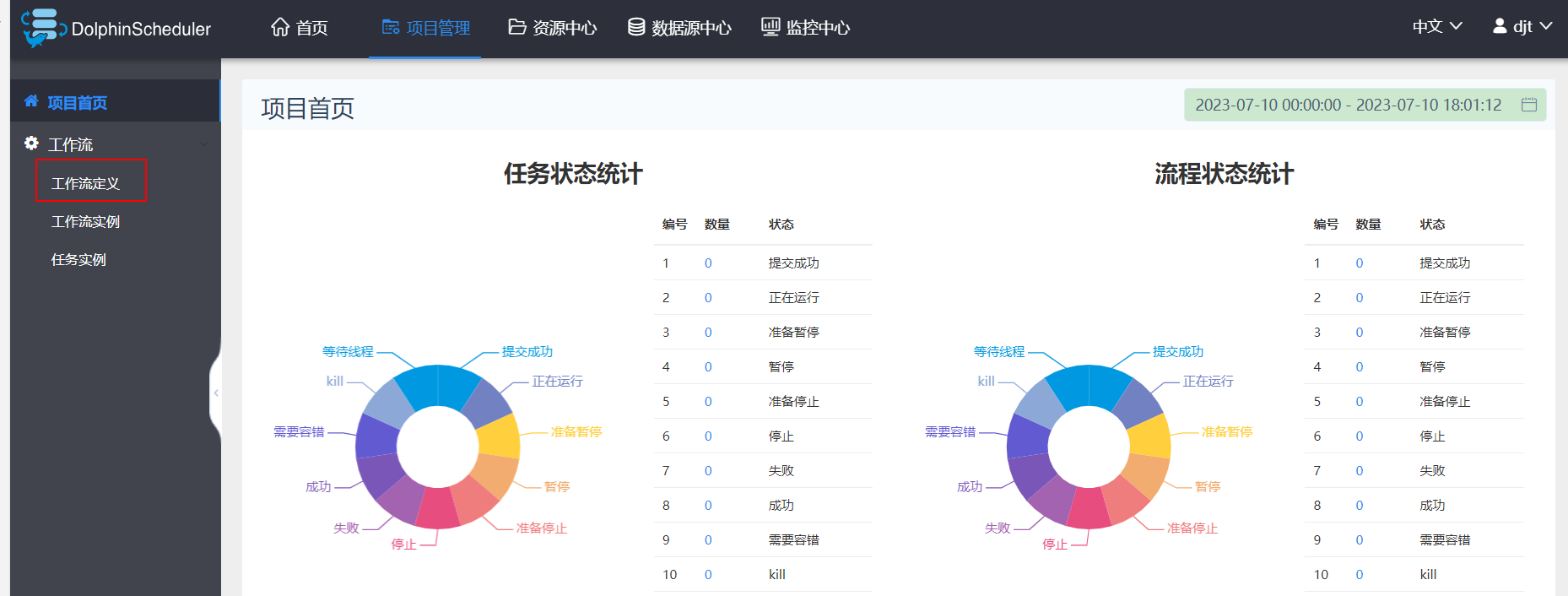
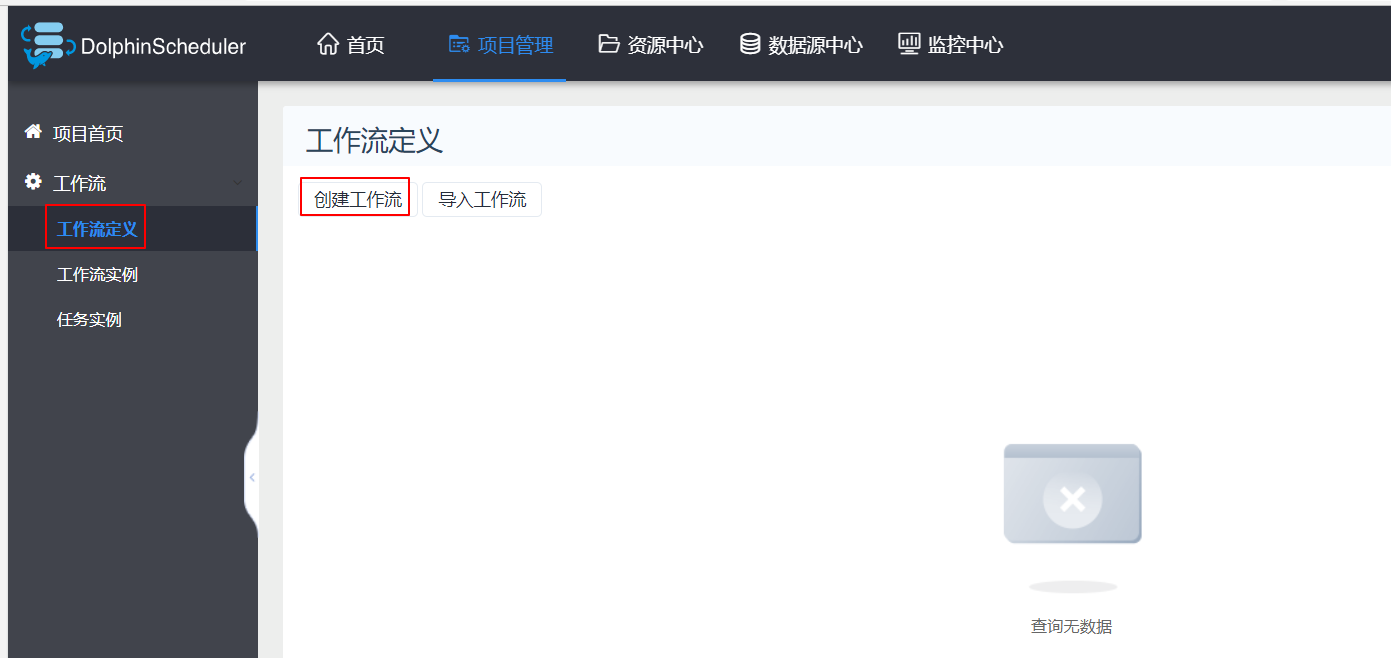
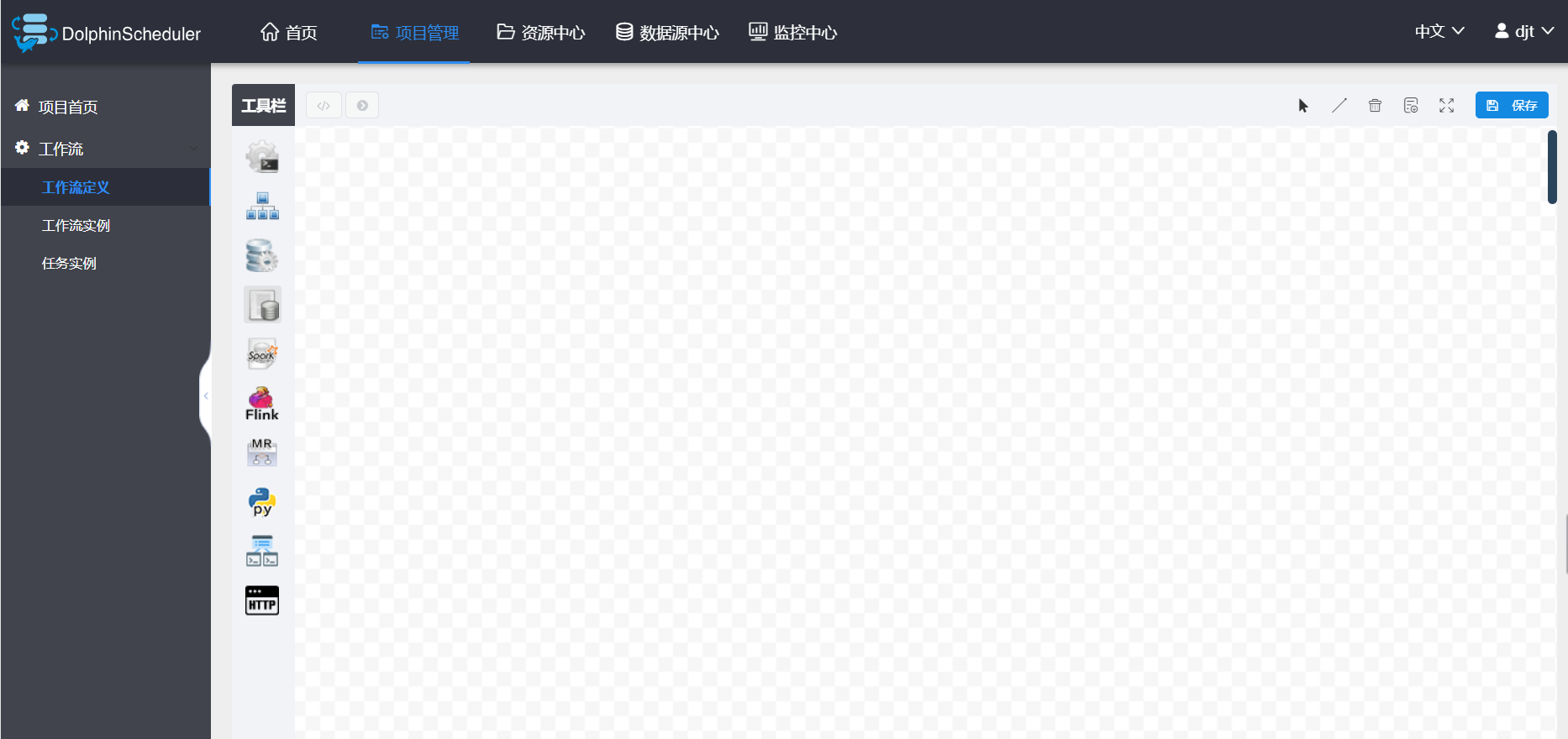
用户可以保存工作流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号