

win10+CUDA8.0+vs2013配置
前段时间,在TX2上装了OpenCV3.4,TX2更新源失败的问题,OpenCV内部很多函数都已经实现了GPU加速,但是我们手动写的函数,想要通过GPU加速就需要手动调用CUDA进行加速。下面介绍Windows平台的环境配置和编译。
Windows下VS2013 + CUDA配置
1.1 确认安装
命令行下输入
nvcc
如果出现下面的打印,说明安装完成

1.2 创建CUDA项目
然后打开vs2013,新建一个空项目
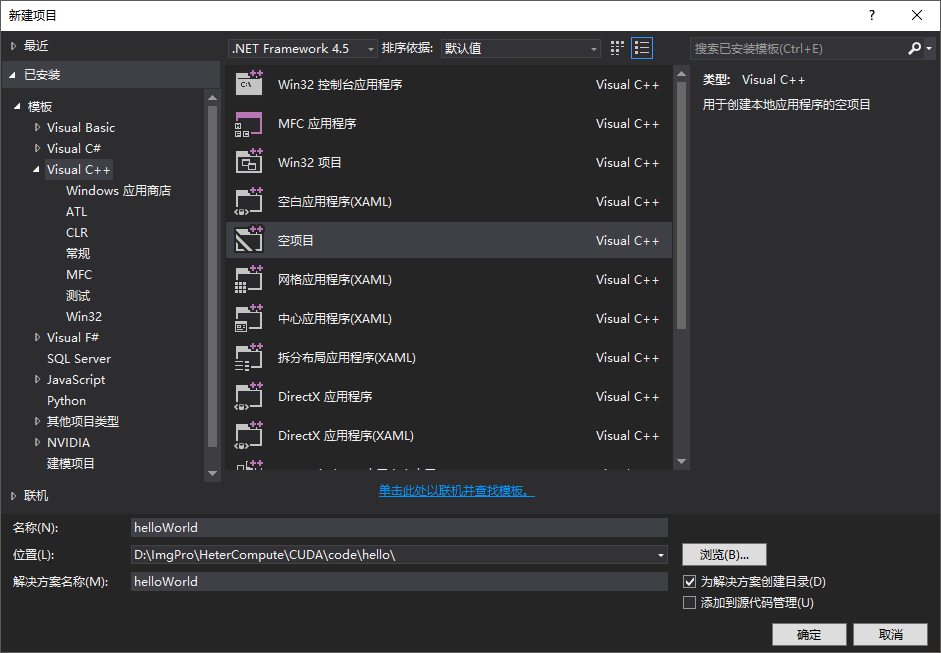
然后在项目中添加CUDA依赖,解决方案右击:生成依赖项->生成自定义,添加CUDA
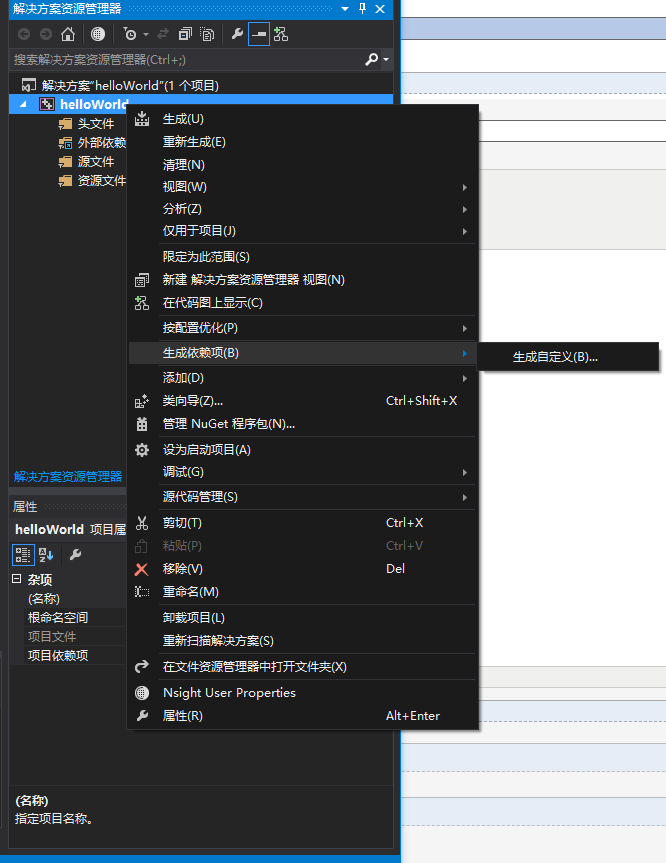

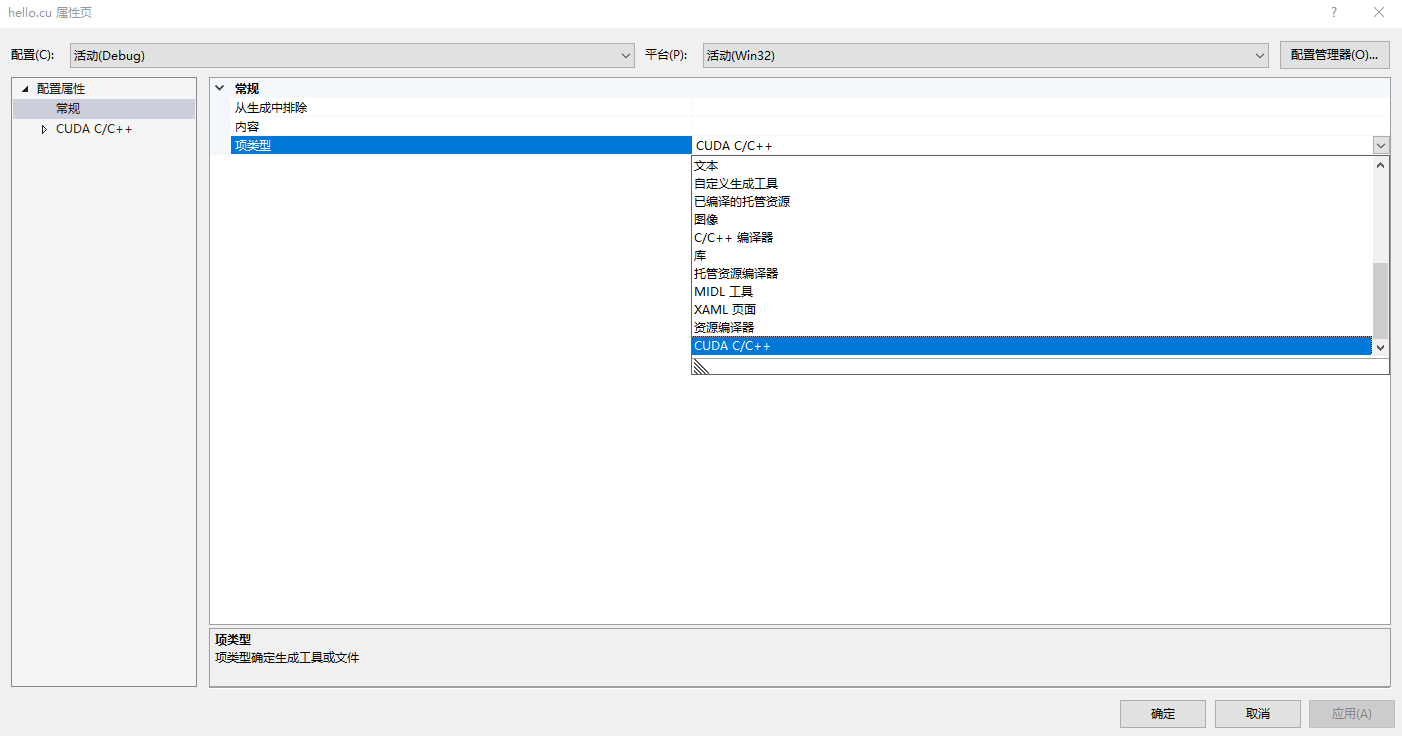
添加依赖项之后,可以新建一个.cu文件,然后右击该文件:属性->配置属性->常规->项类型->CUDA C/C++。
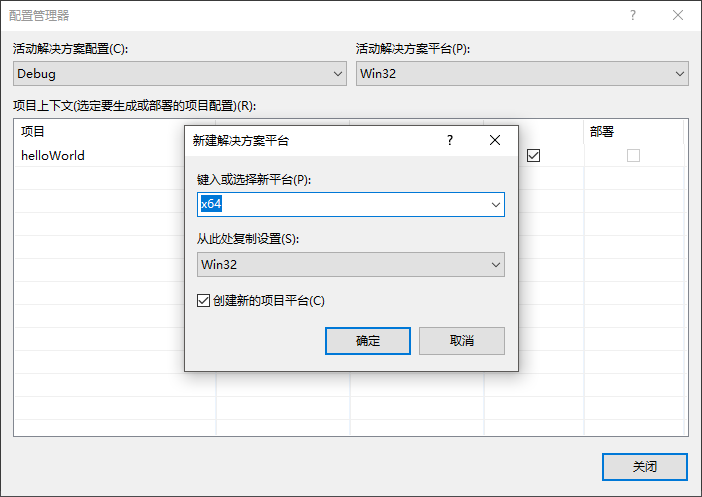
1.3 配置x64环境
工具栏点击解决方案配置->配置管理器->活动解决方案平台->新建->
1.4 配置CUDA属性
准备工作做完了,接下来配置CUDA的相关属性(包含路径,库目录等),为了方便以后使用,创建一个配置文件,在这个配置文件中配置CUDA的相关属性。
点击属性管理器(找不到属性管理器的可以按照这个顺序:视图->其他窗口->属性管理器)-> Debug | x64 -> 添加新项目属性表,填入属性表名字 CUDA_Dubeg_x64_Config.props,创建完成后双击新建的属性表->通用属性->VC++目录,在包含目录和库目录这两个选项下面添加:
包含目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\common\inc
库目录:
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\common\lib\x64 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\x64
然后:链接器->输入->附加依赖项目,添加下面这些库文件
cublas.lib
cublas_device.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusparse.lib
nppc.lib
nppi.lib
nppial.lib
nppicc.lib
nppicom.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvcuvid.lib
nvgraph.lib
nvml.lib
nvrtc.lib
OpenCL.lib
保存退出。
1.5 编译测试
配置完成后,编译一个小程序测试配置是否成功
/*hello.cu*/
// CUDA runtime 库 + CUBLAS 库 #include <cuda_runtime.h> #include <cublas_v2.h> #include <device_launch_parameters.h> #include <time.h> #include <iostream> # pragma warning (disable:4819) using namespace std; bool initDevice(void) { int cnt, i; cudaGetDeviceCount(&cnt); if (cnt < 0){ cout << "Can not find CUDA device" << endl; return false; } for (i = 0; i < cnt; i++){ cudaDeviceProp porp; if (cudaGetDeviceProperties(&porp, i) == cudaSuccess){ if (porp.major >= 1) { break; } } } if (i == cnt){ cout << "< 1.0" << endl; } return true; } __global__ void kernel_compute(float *model, float *input, float *output) { int idx_x, idx_y; idx_y = blockIdx.x; idx_x = idx_y * blockDim.x + threadIdx.x; float sum = 0; for (int i = 0; i < 9; i++){ sum += input[idx_x] * model[i]; } //printf("%3d %d %2.6f %2.6f\n", idx_x, idx_y, sum, input[idx_x]); output[idx_x] = sum; } /*block ---> row*/ int buildMaps(float *model, float *input, float *output, int height, int width) { initDevice(); float *dev_m = NULL, *dev_i = NULL, *dev_o = NULL; int size = height * width; cudaMalloc((void **)&dev_m, 9 * sizeof(float)); cudaMalloc((void **)&dev_i, size * sizeof(float)); cudaMalloc((void **)&dev_o, size * sizeof(float)); cudaMemcpy(dev_m, model, 9 * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(dev_i, input, size * sizeof(float), cudaMemcpyHostToDevice); dim3 grid(height, 1, 1); dim3 block(width, 1, 1); kernel_compute <<<grid, block>>> (dev_m, dev_i, dev_o); cudaMemcpy(output, dev_o, size * sizeof(float), cudaMemcpyDeviceToHost); return 0; }
/*main.cpp*/
#include <iostream> #include <Windows.h> #include <stdlib.h> #include <time.h> using namespace std; extern int buildMaps(float *model, float *input, float *output, int height, int width); void show(float *ptr, int height, int width, char *str) { cout << str << " : " << endl; for (int h = 0; h < height; h++){ for (int w = 0; w < width; w++){ int cnt = h * width + w; printf("%5.5f ", ptr[cnt]); } cout << endl; } } #define width 5 #define size (width * width) int main() { float *model = (float *)malloc(9 * sizeof(float)); float *input = (float *)malloc(size * sizeof(float)); float *output = (float *)malloc(size * sizeof(float)); if (!model || !input || !output){ std::cout << "Malloc Error" << endl; exit(-1); } for (int i = 0; i < 9; i++){ model[i] = (float)(i); } srand((unsigned)time(0)); for (long long int i = 0; i < size; i++){ input[i] = ((rand() % 100) * 1.f) / (rand() % 100 + 1); } buildMaps((float *)model, (float *)input, output, width, width); show(model, 3, 3, "model"); show(input, width, width, "input"); show(output, width, width, "output"); int a; cin >> a; }
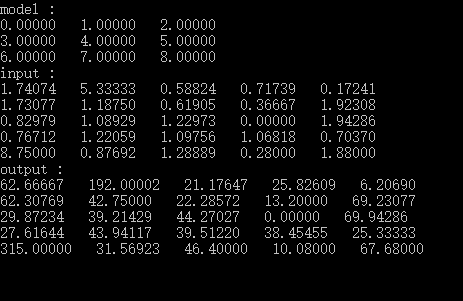
这是一个矩阵相关运算的代码,执行结果如下:
作者:Brccq
出处:http://www.cnblogs.com/br170525//
出处:http://www.loveyfyq.com//
欢迎转载,必须在文章页面明显位置给出原文连接,如需本博文源代码或者有任何问题,请在博文留下您的邮箱或者问题说明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号