如何将自己的文本数据集(CSV格式)加载进mxnet中并使用它?
对iris数据集使用mlp进行分类预测
如果你有一个自己的数据集,数据集得格式是 .csv,那么你可以按照以下步骤将数据集导进mxnet中,本教程使用iris的数据集进行示范
第一步:确定你数据集的保存位置
笔者的数据集保存在以下路径:C:/Users/d2l-zh-1.0/data/iris.csv
数据集中的数据情况如下:
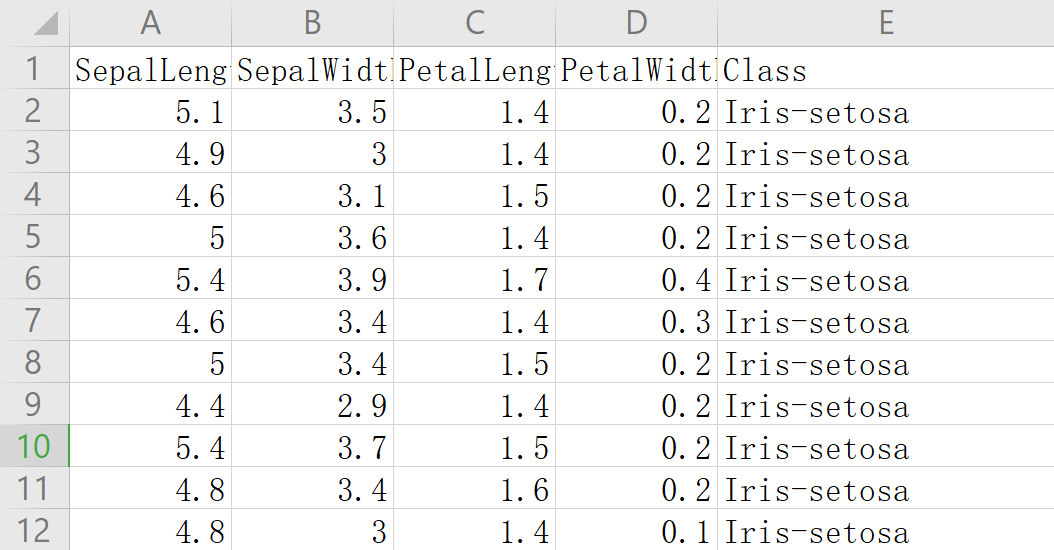
第二步:导入需要的库,将csv文件读进程序中,笔者使用pandas.read_csv读入csv文件:
import mxnet as mx
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import d2lzh as d2l
%matplotlib inline
from sklearn.model_selection import train_test_split
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn
iris_data = pd.read_csv('C:/Users/d2l-zh-1.0/data/iris.csv')
此时,你的csv文件已经读进了内存,对iris数据集还需要进行进一步的处理:增加iris的分类标签
iris_data['target'] = 0 iris_data.loc[(iris_data['Class'] == 'Iris-setosa', 'target')] = 0 iris_data.loc[(iris_data['Class'] == 'Iris-versicolor', 'target')] = 1 iris_data.loc[(iris_data['Class'] == 'Iris-virginica', 'target')] = 2
增加之后的数据集情况如下:
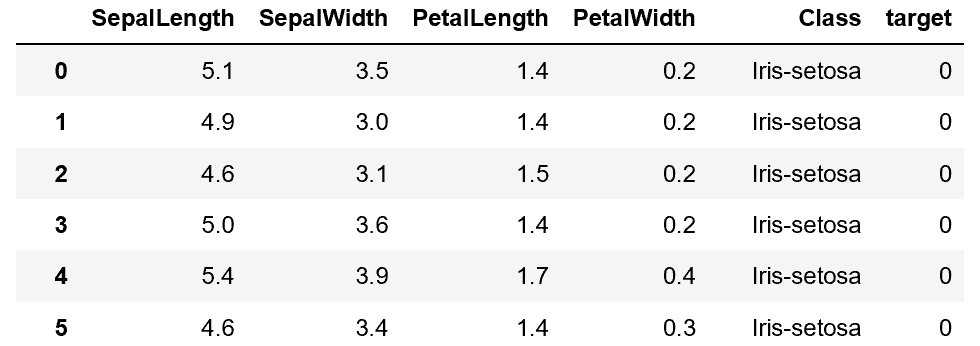
第三步:使用sklearn中的train_test_split函数划分训练集和测试集
X, y = iris_data.ix[:, 0:4], iris_data.ix[:, 5] X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
此时,数据被分成了包含112个数据的训练集和38个数据的测试集。
第四步:将读入的数据转化为NDArray的形式
X_train_nd = nd.array(X_train.values) X_test_nd = nd.array(X_test.values) y_train_nd = nd.array(y_train.values) y_test_nd = nd.array(y_test.values)
第五步:使用mxnet中自带的函数 mx.io.NDArrayIter将其转化为 train_iter和 test_iter
batch_size = 10
train_iter = mx.io.NDArrayIter(data = X_train_nd, label = y_train_nd,
batch_size = batch_size)
test_iter = mx.io.NDArrayIter(data = X_test_nd, label = y_test_nd,
batch_size = batch_size)
第六步:使用下面的类使得 train_iter和 test_iter可以迭代,如果不进行这步,后续的程序会报错,提示 'DataBatch' object is not iterable
class DataIterLoader():
def __init__(self, data_iter):
self.data_iter = data_iter
def __iter__(self):
self.data_iter.reset()
return self
def __next__(self):
batch = self.data_iter.__next__()
assert len(batch.data) == len(batch.label) == 1
data = batch.data[0]
label = batch.label[0]
return data, label
def next(self):
return self.__next__()
train_iter_loader = DataIterLoader(train_iter)
test_iter_loader = DataIterLoader(test_iter)
此时我们已经将一个csv数据转换为mxnet中可以使用的 train_iter_loader 和 test_iter_loader,这两个数据形式可以套用进我们在mxnet中学习过的模型
我们用一个mlp来测试一下:
net = nn.Sequential()
net.add(nn.Dense(100, activation='relu'),
nn.Dense(3))
net.initialize(init.Normal(sigma=0.01))
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.01})
num_epochs = 60
d2l.train_ch3(net, train_iter_loader, test_iter_loader,
loss, num_epochs, batch_size, None,
None, trainer)
经过60轮的迭代,测试集精度达到了100%
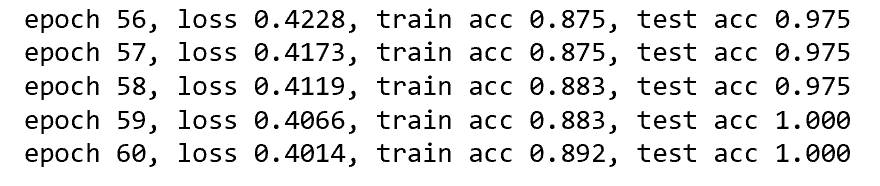
这样,我们就完成了对iris数据集使用mlp进行分类预测,如有疑问,在留言区告诉我。笔者也是刚入门mxnet,学艺不精,如有错误,请大家指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号