

第一次作业:对于Linux2.6.0源码中进程模型的分析
-
摘要:
- 作为第一次写博客,可能在排版,页面布局等方面会有大大小小的失误和不足,希望阅读者可以指出,笔者会继续学习,锻炼自己的博客水平;作为第一次分析Linux操作系统,基于进程模型的理解,在不是很熟悉Linux操作系统的情况下,即使能够明白包括进程等概念和思想,也会产生一定的失误和偏差,会在后续学习中继续改正。
- 切入正题,这一次博客中,我选择了操作系统Linux2.6.0版本的源代码来进行学习和分析,其一,Linux操作系统是开源的,其二,Linux2.6.0版本的代码量相对我而言还是可以接受的,话不多说,先抛出Linux2.6.0源码的下载链接:https://mirrors.edge.kernel.org/pub/linux/kernel/v2.6/linux-2.6.0.tar.gz
- 以下具体内容主要分为四点:
a.操作系统是怎么组织进程的
b.进程状态如何转换
c.进程是如何调度的
d.我对于该操作系统进程模型的看法
-
操作系统是怎么组织进程
- 首先,我们需要明白什么是进程,举个不是很专业的例子,作为单用户系统比如Microsoft Windows,作为其中的一员,平时我们总能够同时执行多个程序:聊天QQ、Google浏览资料、网易云听听歌之类的。可以说,进程就好比我们执行中的程序,当然,这是一种非正式的说法,因为,进程不只是程序代码,其还包括当前活动,能通过程序计数器的值和处理器、寄存器的内容来表示,以下的图片也能展示进程的状态和概念:
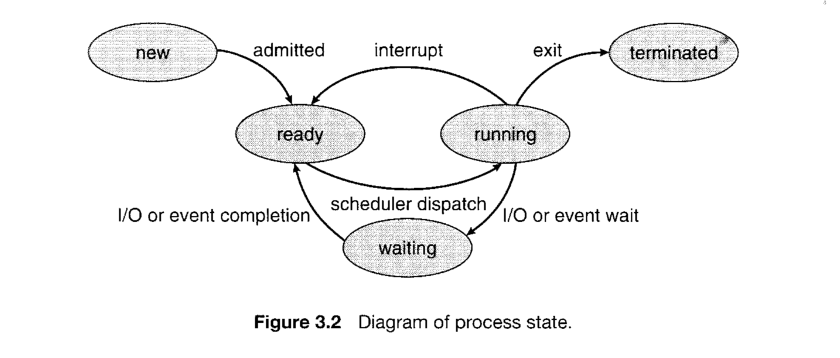
2. 那么,对于Unix、Linux操作系统来说:
进程可以认为是最基本的抽象之一,如上所述,进程并不仅仅局限于一段可执行程序代码,通常,进程还要包含其他的资源,像打开的文件、挂起的信号、内核内部数据、处理器状态、地址空间,或是一个、多个执行的线程,此外,也包括用来存放全局变量的数据段,总体而言,“进程就是正在执行的程序代码的活标本!”
3. 操作系统创建进程的基本思想和方法:
在Linux操作系统中,进程开始存活是在其被创建的时刻,分析类似Linux2.6.0源代码,这通常是调用: fork() 系统调用的结果,这个系统调用通过复制一个现有的进程来产生一个全新的进程,其中,调用 fork() 的进程被称为父进程,那么,就好理解的是,我们父进程产生的新的进程,就是子进程,调用结束后,父进程恢复原来的工作,子进程也会开始执行对应的程序步骤,通过查阅资料我还学习到了,在现代Linux内核中, fork() 实际上是由 clone() 系统调用实现的,当子进程在运行的时候,父进程也能够通过 wait4() 系统调用来查询子进程的状态,如果子进程执行了退出指令 exit() ,那么,他将处于僵死状态,下图是来自于源码中的fork.c文件中的部分创建代码,note!,Linux内核中通常也会把进程叫做任务(task)
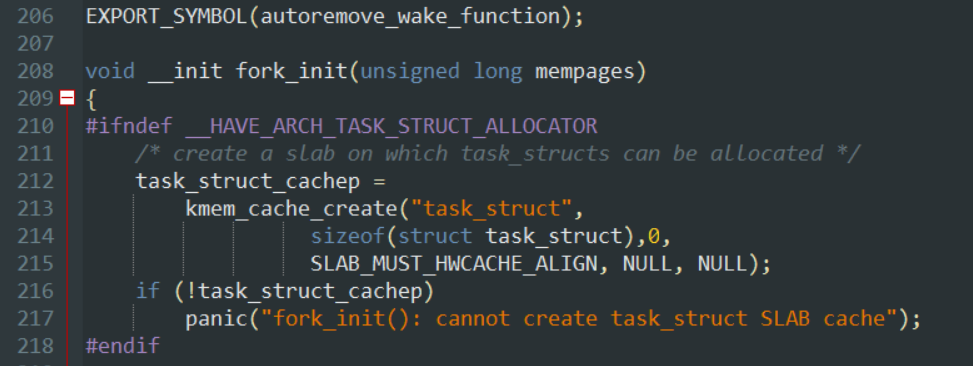
用 fork() 实现进程的创建:
a. Linux是通过 clone() 系统调用来实现 fork() ,同时,通过调节参数标志,指明父进程、子进程所能共享的资源,以此类推,子进程中也能够使用do_fork来创建新的进程。
b. 在fork.c文件中,处于kernel/fork.c文件中的 copy_process() 函数可以说是比较重要的,一方面,能够实现新进程产生时候所需要分配到的资源、内核栈等,另一方面,子进程使用描述符来实现成员值与父进程的区分开来,同时,通过其中的调用 get_pid() 来为新进程获取一个有效的PID等等初始化工作。如果函数成功返回,那么,新创建的子进程就可以开始运行了!
在Linux2.6.0源码中,找到了我们想要的函数 copy_process() :(将近有三百余行,只截取部分代码段)
1 struct task_struct *copy_process(unsigned long clone_flags, 2 unsigned long stack_start, 3 struct pt_regs *regs, 4 unsigned long stack_size, 5 int __user *parent_tidptr, 6 int __user *child_tidptr) 7 { 8 int retval; 9 struct task_struct *p = NULL; 10 11 if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS)) 12 return ERR_PTR(-EINVAL); 13 14 /* 15 * Thread groups must share signals as well, and detached threads 16 * can only be started up within the thread group. 17 */ 18 if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND)) 19 return ERR_PTR(-EINVAL); 20 21 /* 22 * Shared signal handlers imply shared VM. By way of the above, 23 * thread groups also imply shared VM. Blocking this case allows 24 * for various simplifications in other code. 25 */ 26 if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM)) 27 return ERR_PTR(-EINVAL); 28 29 /* 30 * CLONE_DETACHED must match CLONE_THREAD: it's a historical 31 * thing. 32 */ 33 if (!(clone_flags & CLONE_DETACHED) != !(clone_flags & CLONE_THREAD)) { 34 /* Warn about the old no longer supported case so that we see it */ 35 if (clone_flags & CLONE_THREAD) { 36 static int count; 37 if (count < 5) { 38 count++; 39 printk(KERN_WARNING "%s trying to use CLONE_THREAD without CLONE_DETACH\n", current->comm); 40 } 41 } 42 return ERR_PTR(-EINVAL); 43 } 44 45 retval = security_task_create(clone_flags); 46 if (retval) 47 goto fork_out; 48 49 retval = -ENOMEM; 50 p = dup_task_struct(current); 51 if (!p) 52 goto fork_out; 53 54 retval = -EAGAIN; 55 if (atomic_read(&p->user->processes) >= 56 p->rlim[RLIMIT_NPROC].rlim_cur) { 57 if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) && 58 p->user != &root_user) 59 goto bad_fork_free; 60 } 61 62 atomic_inc(&p->user->__count); 63 atomic_inc(&p->user->processes); 64 65 /* 66 * If multiple threads are within copy_process(), then this check 67 * triggers too late. This doesn't hurt, the check is only there 68 * to stop root fork bombs. 69 */ 70 if (nr_threads >= max_threads) 71 goto bad_fork_cleanup_count; 72 73 if (!try_module_get(p->thread_info->exec_domain->module)) 74 goto bad_fork_cleanup_count; 75 76 if (p->binfmt && !try_module_get(p->binfmt->module)) 77 goto bad_fork_cleanup_put_domain; 78 79 #ifdef CONFIG_PREEMPT 80 /* 81 * schedule_tail drops this_rq()->lock so we compensate with a count 82 * of 1. Also, we want to start with kernel preemption disabled. 83 */ 84 p->thread_info->preempt_count = 1; 85 #endif 86 p->did_exec = 0; 87 p->state = TASK_UNINTERRUPTIBLE; 88 89 copy_flags(clone_flags, p); 90 if (clone_flags & CLONE_IDLETASK) 91 p->pid = 0; 92 else { 93 p->pid = alloc_pidmap(); 94 if (p->pid == -1) 95 goto bad_fork_cleanup; 96 } 97 retval = -EFAULT; 98 if (clone_flags & CLONE_PARENT_SETTID) 99 if (put_user(p->pid, parent_tidptr)) 100 goto bad_fork_cleanup; 101 //后续部分省略了
4. 创建好进程之后,操作系统是这样组织进程的:
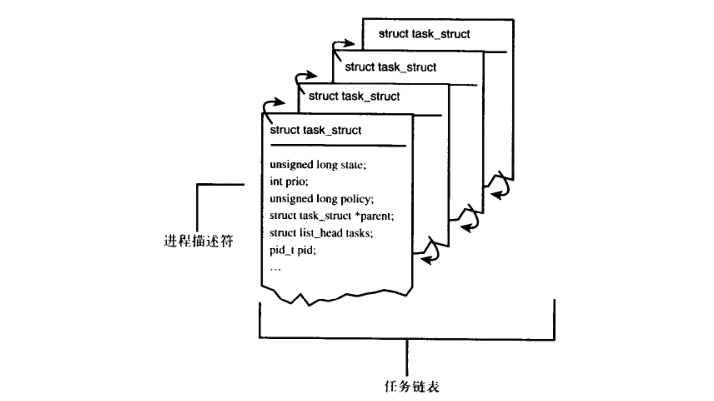
(1)通过使用进程描述符以及对应的任务(task)结构
Linux内核会把进程存放在task list的双向循环链表中,其中每一项都是类型为task_struct,也就是我们学到的进程描述符的结构,进程描述符能够包含一个具体进程的所有信息,比如我们在执行一个程序的时候,系统就会记录该进程的地址空间、状态等等
进程描述符以及任务队列结构图:
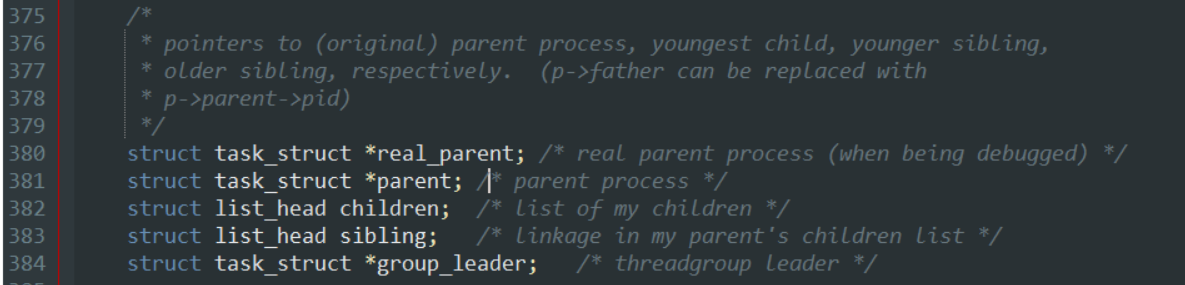
同时,我也在Linux2.6.0的源码中找到了进程描述符结构的定义,代码如下:
(2)组织进程中的分配和存放进程描述符:
a. 系统使用slab分配器来分配task_struct结构,在避免动态分配和释放所带来的资源耗费下,能够比较友好地实现重复使用,其中通过栈指针来计算出对应的位置;此外,slab分配器也能够动态生成task_struct,比如创建一个结构 struct thread_info :

b. 之前我们讲到,系统在调用 fork() 里面的 copy_process() 时候,有一个 get_pid() 的使用,这边便起到了很大的作用,从操作系统课本中,我们学习到,内核是通过唯一的进程标识值(PID)来标识每个进程的:
PID是一个数,表示为 pid_t 隐含类型,为了兼容老版本,PID的最大值默认为32768,每个进程的PID存放在它们各自的进程描述符中,其中,这个最大值很重要,因为它实际上就是系统中允许同时存在的进程的最大数目,理论上,内核中是通过PID、获得指向进程task_struct指针,来实现处理大部分进程
-
进程状态的转换
1. 通过查阅Linux相关书籍,了解学习到了开发者是这样来实现Linux系统进程状态设定的,以下引用来自部分节选:
Linux系统中的每个进程都会处于五种进程状态中的一种,其域值也会是下列五种状态标志之一:
- TASK_RUNNING(运行)——进程是可执行的:它或者正在执行,或者在运行队列中等待执行。这是进程在用户空间中执行唯一可能的状态;也可以应用到内核空间中正在执行的进程
- TASK_INTERRUPTIBLE(可中断)——进程正在睡眠,等待某些条件的达成。一旦这些条件达成,内核就会把进程状态设置为运行。处于此状态的进程也会因为接收到信号而提前被唤醒并投入运行
- TASK_UNINTERRUPTIBLE(不可中断)——除了不会因为接收到信号而被唤醒从而投入运行外,这个状态与可打断状态相同,此外,处于此状态的任务对信号不作响应
- TASK_ZOMBIE(僵死)——进程已经结束,但是其父进程还没有调用wait4( )系统调用。为了父进程能够获知它的消息,子进程的进程描述符仍然被保留着。一旦父进程调用了wait4( ),进程描述符就会被释放
- TASK_STOPPED(停止)——进程停止执行;进程没有投入运行也不能投入运行。通常这种状态发生在接收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU等信号的时候,此外,在调试期间接收到任何信号,都会使进程进入这种状态
2. 当前进程状态的设置:
Linux内核需要调整某个进程的状态的时候,一般会使用到 set_task_state(task,state) 函数,该函数将指定的进程设置为指定的状态,下面部分代码也是我在Linux2.6.0版本下找到的对应函数段:

3. 进程状态转换图:

-
进程的调度
1. 调度的基本概念:
调度程序没有很复杂的原理,通俗来说就是因为当系统需要执行的进程数目比处理器数目多的时候,就会存在有一些准备好等待运行的进程,这时候就需要调度程序来实现作用,从可执行状态的进程中选择一个来执行,这样子通过合理的调度,系统的资源也能够达到最大限度的发挥作用,从而显示出并发执行的效果
2. Linux2.6.0选择的调度程序:
a. 在早期发现了非抢占式多任务模式下的缺点之后,Linux内核开发系列中也对调度程序做了修改,包括Linux2.6.0在内的版本,也开始采用O(1)调度程序的新调度程序,不管有多少个进程,该新调度程序采用的每个算法都能在规定时间内完成
b. 调度程序定义于kernel/sched.c中,该调度程序能较好保证公平,即,在合理设定的时间范围内,没有进程会处于饥饿状态,同样,也没有进程能够显失公平地得到大量时间片
3. Linux2.6.0中进程调度的基本数据结构:运行队列(runqueue)
可执行队列是给定处理器上的可执行进程的链表,每个处理器一个,对于每个可投入运行的进程都唯一地归属于一个可执行队列,其中还可以通过使用 task_rq_lock() 和 task_rq_unlock() 函数来进行控制和管理
1 struct runqueue { 2 spinlock_t lock; 3 unsigned long nr_running, nr_switches, expired_timestamp, 4 nr_uninterruptible; 5 task_t *curr, *idle; 6 struct mm_struct *prev_mm; 7 prio_array_t *active, *expired, arrays[2]; 8 int prev_cpu_load[NR_CPUS]; 9 #ifdef CONFIG_NUMA 10 atomic_t *node_nr_running; 11 int prev_node_load[MAX_NUMNODES]; 12 #endif 13 task_t *migration_thread; 14 struct list_head migration_queue; 15 16 atomic_t nr_iowait; 17 };
4. Linux2.6.0调度程序减少对循环的依赖,而是为每个处理器维护两个优先级数组,一个是活动数组,另一个是过期数组:
(1)活动数组内可执行队列上的进程都各自还有自己的时间片剩余,对于过期数组内的可执行队列上的进程而言,它们的时间片都已经耗尽了
(2)当一个进程的时间片耗尽时,其会被移到过期数组中,重新做好时间片计算,为后续做处理
(3)优先级数组的定义:
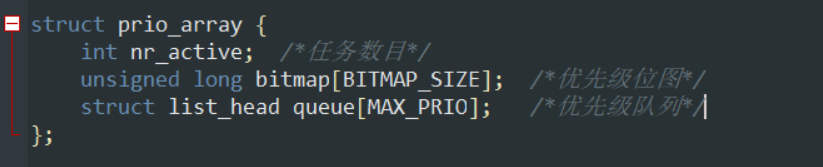
(4)schedule( )中完成交换重新计算时间:
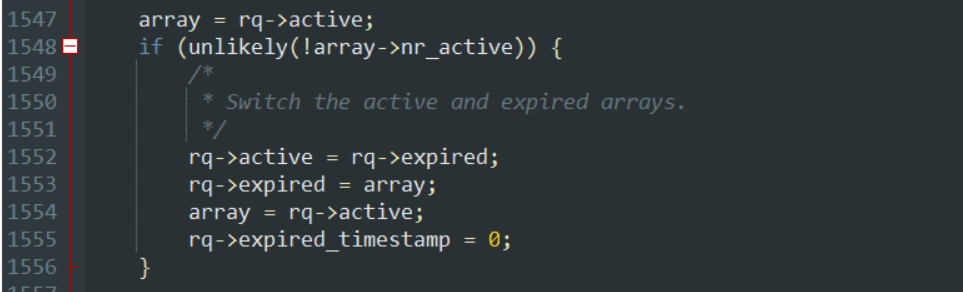
5. 进程在调度过程中,如果需要选定下一个进程并切换到它去执行是通过 schedule() 函数来实现的
6. 调度程序中用到的两大思想理念:计算优先级、时间片:
Linux2.6.0在进程调度中,也是利用优先级和时间片来影响调度程序做出决定
(1)进程拥有一个初始化的优先级,名为nice,这个值也会在一定范围内变化,观察源码,进程task_struct的static_prio域就存放的这个nice值,在调度程序运行时候,需要使用到动态优先级的情况下,就可以根据这个nice数值来确定进程执行先后的优先级别
(2)在优先级确定的条件下,新建的子进程与父进程均分父进程剩余的进程时间片,当不符合时间片规定的一定范围内,系统通过调用 task_timeslice() 函数返回一个新的时间片,为每个进程后续的执行提供可用时间片,当然,进程中优先级越高,其每次执行所得到的时间片就会越长
7. 进程通过调度程序使自己开始工作:
1 void wait_for_completion(struct completion *x) 2 { 3 might_sleep(); 4 spin_lock_irq(&x->wait.lock); 5 if (!x->done) { 6 DECLARE_WAITQUEUE(wait, current); 7 8 wait.flags |= WQ_FLAG_EXCLUSIVE; 9 __add_wait_queue_tail(&x->wait, &wait); 10 do { 11 __set_current_state(TASK_UNINTERRUPTIBLE); 12 spin_unlock_irq(&x->wait.lock); 13 schedule(); 14 spin_lock_irq(&x->wait.lock); 15 } while (!x->done); 16 __remove_wait_queue(&x->wait, &wait); 17 } 18 x->done--; 19 spin_unlock_irq(&x->wait.lock); 20 }(1)调用 DECLARE_WAITQUEUE() 创建一个等待队列的项
(2)调用 add_wait_queue_tail() 把自己加入到队列中,该队列会在进程等待的条件满足时唤醒它
(3)将进程的状态变更为TASK_UNINTERRUPTIBLE
(4)检查条件是否为真,如果是的话,那么就没必要休眠,如果条件不为真,while中调用 schedule()
(5)当进程被唤醒的时候,会再次检查条件是否为真。如果是,进程就会退出循环,否在,进程继续调用 schedule() 并重复这个步骤
(6)条件满足时候,进程将自己设置为TASK_RUNNING,同时调用 _remove_wait_queue() 把自己移出等待队列
-
对于Linux2.6.0操作系统进程模型的看法
作为Linux系统中基本的抽象之一,我认识到了进程的重要作用,通过初步了解Linux2.6.0版本的源代码,我也能够大体明白开发者在这个版本中是怎么实现进程管理程序的,同时,我认为思想或许才是最重要的:在创建进程中,父进程创建出子进程,两者又通过PID区分,在一定程度上,共享一定的资源,此外,两者也能均分父进程剩下的时间片,如果时间片不够了,又能够重新计算时间片来解决问题;另外,父进程可以查看子进程的动态信息,是否需要释放子进程的僵死状态,使得这部分资源能够供其他工作使用。学习了这一部分后,我感觉这样的设计理念是比较符合包括处理器资源的高效率利用,从而实现出能在同时间段内并发运行的效果出来,归根而言,进程位于每个现代操作系统的核心位置,也是最终导致我们拥有操作系统的根源。
当然,对于Linux2.6.0版本的进程调度,我们也不能说这是完美无缺的,毕竟还有很多的改善和算法优化,想要满足进程调度的各种需要绝不是轻而易举的,基于Linux2.6.0操作系统而言,在采用了O(1)新调度程序后,基本可以实现各个方面的完善,比如适合众多的可运行进程,具有一定的伸缩性,以及能够抵抗对应程度的负载等等。
学无止境,作为刚刚接触Linux操作系统,我的认识会是比较浅显的,需要在后续中不断学习Linux系列思想、运用,相信那时会对Linux进程、调度等有更加准确、丰富的认识!

