第二部分-分布式数据系统
第五章 数据复制
第六章 数据分区
6.1 数据分区与数据复制
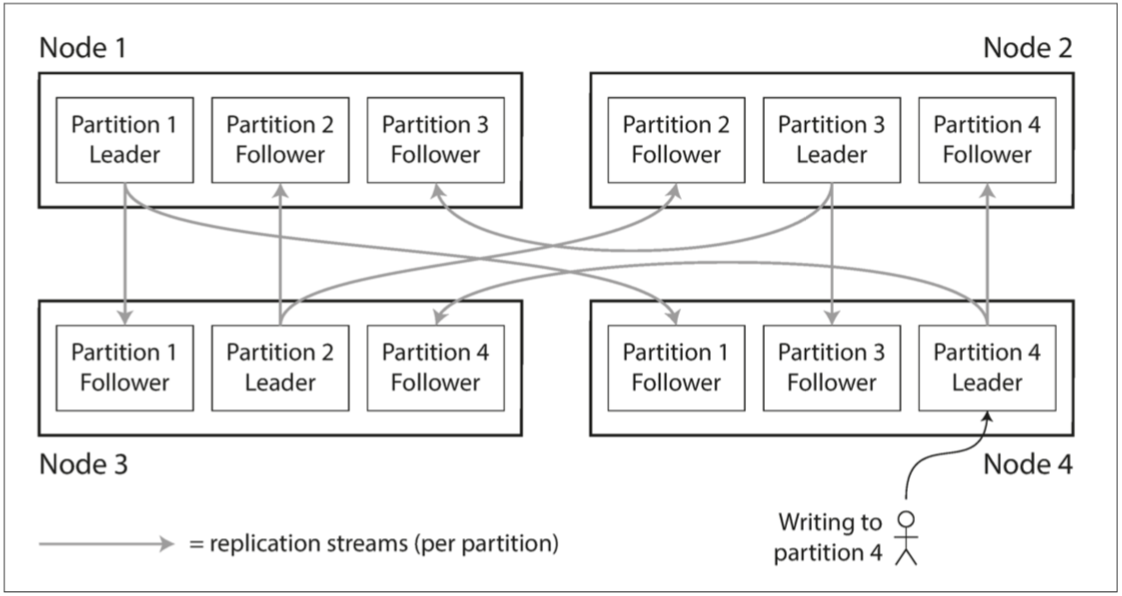
可以组合使用主从复制模型和分区,分区拓展单机性能,主从模型中从节点作为容灾备份。
每个分区节点,既包含主副本,又包含从副本,副本可以隶属于不同分区。
6.2 键值数据的分区
如果分区不均匀,某些分区节点会承担更多的数据量或者查询负载,成为倾斜,负载严重不成比例的分区即成为系统热点。
基于关键字区间分区
- 为每个分区分配一段连续的关键字,或者关键字区间范围
- 关键字区间不一定非要均匀分布,因为数据本身可能就不均匀
- 每个分区内可以按照关键字进行排序
- 缺点是某些访问模式会导致热点,解决办法是,比如原来关键字是时间戳,对于某些大事的时间戳会发生频次较高的查询,则可以使用时间戳之外的其他内容作为关键字的第一项,可以再时间戳前加上传感器名称作为前缀,这样可以首先由传感器名称,然后再由时间戳分区
基于关键字哈希值分区
- Cassandra和MongoDB使用MD5,Voldemort使用Fowler-Noll-Vo函数,一些编程语言的内置哈希函数,可以会受不同进程的影响,并不可靠
- 找到合适的关键字哈希函数,为每个分区分配一个哈希范围
- 优点:很好的将关键字均匀的分配到多个分区中
- 缺点:丧失了良好的区间查询特性,MongoDB中,区间查询会并行在所有分区查询
一致性哈希
- 可以平均分配负载
- 最初用于CDN等网络缓存系统
- 采用随机选择的分区边界来规避中央控制或者分布式共识
- 对数据库实际效果并不好,目前很少使用
分区策略综合
Cassandra采用了这种的方式,表可以声明为由多个列组成的符合主键。只有第一部分可以使用哈希分区,其他列则用作组合索引来对SSTable中的数据进行排序。
因此,它不支持再第一列区间查询,但是固定第一列时,则可以对其他列执行高效的区间查询。
负载倾斜与热点
哈希分区的极端情况是,所有读写操作针对一个关键字,即所有请求都被路由到同一个分区。
解决办法:
在应用层来减轻倾斜程度,比如某个关键字被确认为热点,可以在关键字开头或者结尾增加随机数,这样写请求会被分配到多个分区节点上。
问题就是任何读取都需要额外的工作,必须从所有分区读取数据再合并,所以通常只会对少量的热点关键字附加随机数才有意义。
6.3 分区与二级索引
二级索引:通常不能唯一标识一条记录,一般用来加速特定值的查询
前面的分区方案无法很好地适应二级索引存在的场景,主要挑战是二级索引不能规整的映射到分区中,主要有两种方案,基于文档分区和基于词条的分区。
基于文档的分区
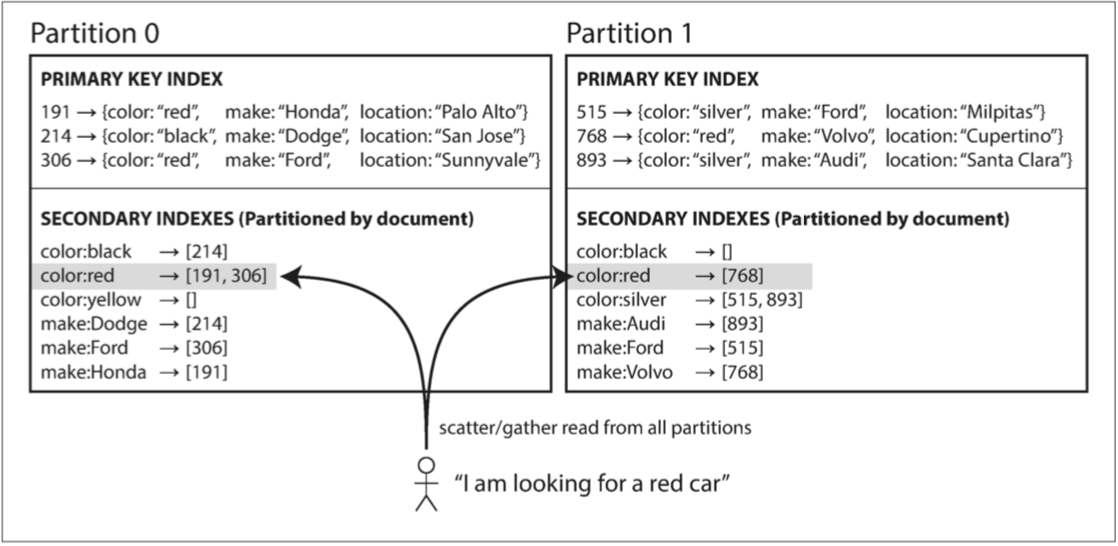
- 每个分区完全独立,各自维护自己的二级索引,且只负责自己分区内的文档
- 文档分区也被称为本地索引,而非全局索引
- 查询时需要查询所有分区,即“分散/聚集”,查询代价高昂,且即使并行查询,仍然容易导致读延迟显著放大
- 目前实践:MongoDB,Riak ,Cassandra ,Elasticsearch,SolrCloud 和VoltDB
基于词条的分区
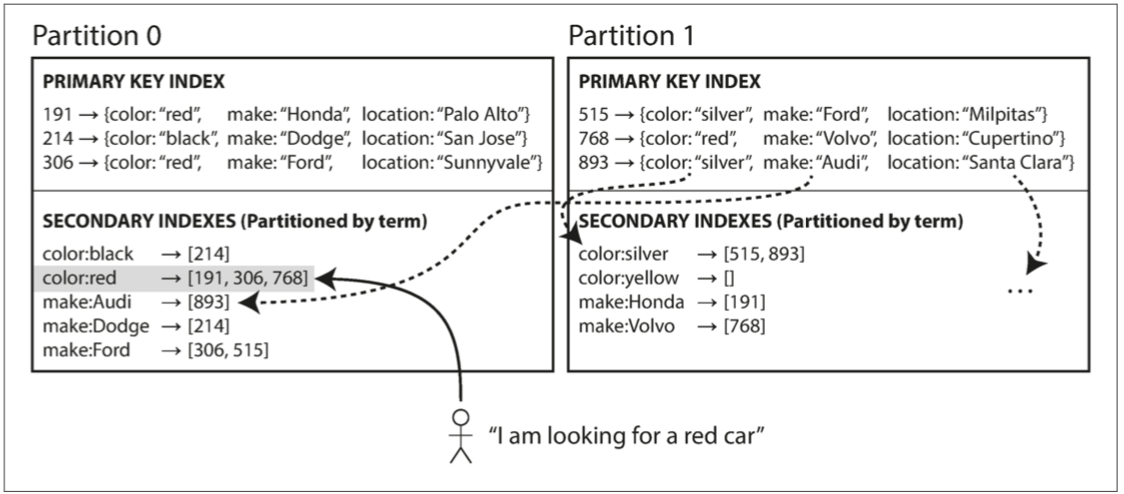
- 对所有的数据构建全局索引,而非每个分区维护自己的本地索引
- 以待查找的关键字本身作为索引
- 索引产生:可以直接用关键词来全局划分索引,或者取哈希值。直接分区可以高效区间查询,哈希则可以更均匀划分分区。
- 相比于文档分区
- 优点:读取更为高效,不需要采用“分散/聚集”来对所有的分区执行一遍查询,只要确定索引所在分区一次请求即可完成
- 缺点:写入速度较慢且非常负责,单个文
档更新时,可能会涉及到多个二级索引多个分区节点的更新;针对于此,对全局二级索引的更新一般都是异步更新
6.4 分区再平衡
查询压力增加、数据规模增加、单节点故障,都有可能需要我们进行分区再平衡,即将数据和请求从一个节点转移到另外一个节点。
不能直接取模
- 如果节点N发生变化,会导致很多关键字进行迁移,涉及到多个分区的调整,大大增加了再平衡的成本
固定数量分区
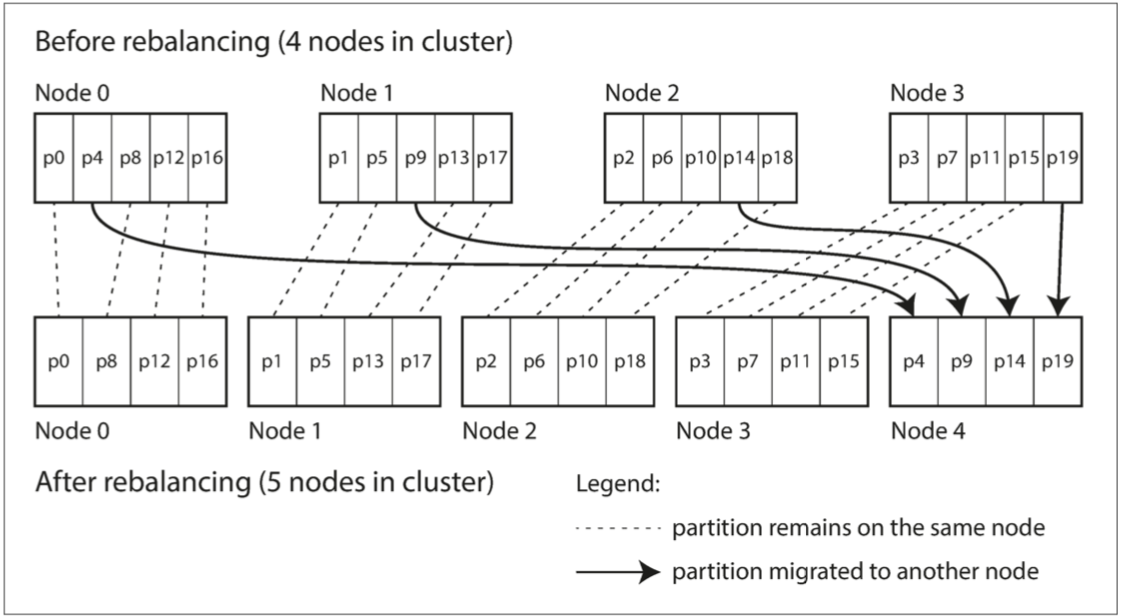
- 创建远超实际节点数的分区,然后为每个节点分配多个分区
- 如果集群增删节点,从已分配的分区进行选中一部分进行迁移即可
- 注意:需要调整分区与节点的对应关系,可以逐步完成
- 分区数量不要太大,不要太小,很那确定最佳取舍点
- 实践:Riak,Elasticsearch,Couchbase和Voldemort
动态分区
- 当分区数据增长超过一个可配置的参数阈值时,拆分为两个分区,每个分区承担一半
- 当大量数据被删除,且分区缩小到某个阈值,将其与相邻分区合并
- 与B树的分裂操作类似
- 优点:分区数量可以自动适配数据总量
- 缺点:对于空数据库,刚开始直到达到第一个分裂点之前,所有写入操作由单节点处理。缓解办法是,HBase和MongoDB允许再空数据库配置一组初始分区。
按节点比例分区
- 使分区节点和集群节点成正比例关系,即每个节点具有固定数量的分区
- 新节点加入时,随机选择固定数量的现有分区进行分裂,可能会导致不公平的分裂(Cassandra在3.0推出改进算法)
- 实践:Cassandra和Ketama
自动 or 手动
让管理员介入到再平衡是个更好的选择,比全自动响应慢一点,但是可以有效防止意外发生
6.5 请求路由
服务发现
典型的服务发现问题,任何通过网络访问的系统都有这样的需求,尤其是当服务目标支持高可用时。
主要有三种策略,
1.允许客户端链接任意节点,如果节点不包含数据,则转发给下一个合适的节点
2.客户端请求全部发送到路由层,路由层充当分区感知的负载均衡器,不处理请求
3.客户端感知分区和节点分配关系,直连目标节点
许多分布式数据系统依赖独立的协调服务(ZooKeeper/Etcd/Consul)跟踪集群范围内的元数据,每个节点向协调服务注册自己,协调服务维护了最终的映射关系。
其他数据系统,有的使用了Helix,也有的使用gossip协议来同步集群状态,由节点负责转发请求到真正的节点。这种方式增加了数据库节点的复杂性,但是避免了对外部协调服务的依赖。
并行查询执行
对于大规模并行处理(Massively Paallel Processing, 主要用于数据分析的关系数据库),查询复杂得多,可能会包含多个联合、过滤、分组和聚合操作,MPP查询优化器会将复杂查询分解为许多执行阶段和分区,以便在集群的不同节点并行执行。
第七章 事务
这一章讲的是单机数据库实现的事务,略过不做记录。
7.1 深入理解事务
7.2 弱隔离级别
7.3 串行化
第八章 分布式系统的挑战
个人感觉这一章实际意义不大,整体都是在讨论不可靠的网络和时钟,故不做记录。
8.1 故障与部分失效
8.2 不可靠的网络
8.3 不可靠的时钟
8.4 知识,真相与谎言
第九章 一致性与共识
分布式系统有太多可能出错的场景,最简单的处理办法就是停止系统服务,向用户提示出错信息,显然是不可接受的,我们需要更加容错的解决方案。
借助于抽象的事务机制,可以屏蔽系统内部很多复杂的问题,例如发生崩溃(原子性)、并发访问(隔离性)、磁盘故障(持续)等,使得应用层轻松无忧。
9.1 一致性保证
复制数据库时,同时查询数据库两个节点,可能会看到不同的数据,主要是因为写请求会在不同的时间到达不同的节点,无论数据库采用何种复制方法,都无法避免,但是一般来说,数据库最终会达到一致性,我们称之为最终一致性。本章将探索更强的一致性模型,这也意味着更高的代价,好处就是上层应用逻辑会更简单。
9.2 可线性化
如何达到线性化
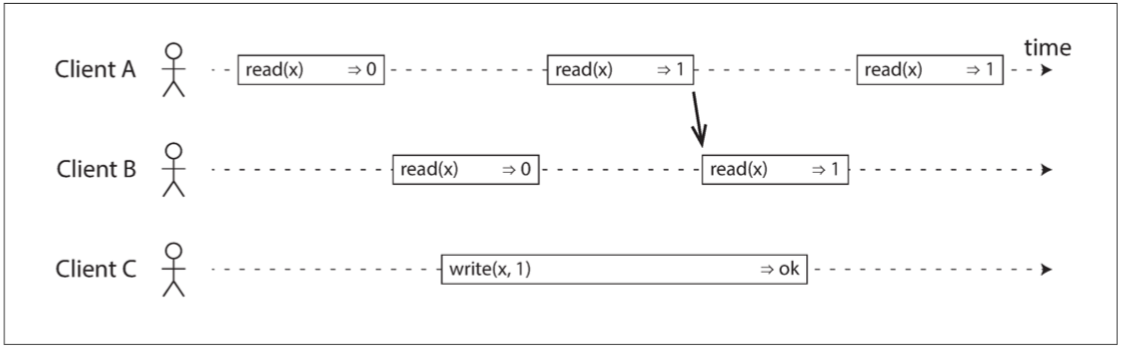
重要约束:在一个可线性化的系统中,写操作开始和结束之间,必定存在某个时间点,x的值发生了从0到1的跳变。如果某个客户端的读取返回了新值1,即使写操作尚未提交,那么后续的读取必须全部返回新值。
每个操作都在我们认为执行操作的时候用竖线标出(在每个操作的条柱之内)。这些标记按顺序连在一起,其结果必须是一个有效的寄存器读写序列(每次读取都必须返回最近一次写入设置的值)。
线性一致性的要求是,操作标记的连线总是按时间(从左到右)向前移动,而不是向后移动。这个要求确保了我们之前讨论的新鲜度保证:一旦新的值被写入或读取,所有后续的读都会看到写入的值,直到它被再次覆盖。
可线性化与可串行化
可串行化是事务的隔离级别,每个事务可以读写多个对象,用来确保事务执行的结果与船型执行的结果完全相同。
可线性化值读写寄存器(单个对象)的最新值保证,并不要求将操作组合到事务中,因此无法避免写倾斜问题。
数据库可以同时支持可串行化与可线性化,又被称为严格的可串行化或者强的单副本可串行化。
线性化的依赖条件
加锁与主节点选举
主从复制的系统需要确保只有一个节点,每次选主的时候,需要所有节点都意识到同一个节点持有锁,即该节点准备竞选主节点,不允许其他节点同时竞选,这样可以避免脑裂的问题出现。
常见的ZooKeeper和Etcd通常用来实现分布式锁和主节点选举,都是用了支持容错的共识算法来确保可线性化(Paxos和Raft)。
一些分布式数据库(如Oracle Real Application Clusters(RAC))中更多的粒度级别上使用。RAC对每个磁盘页面使用一个锁,多个节点共享对同一个磁盘存储系统的访问权限。
约束与唯一性保证
这种情况实际上类似于一个锁:当一个用户注册你的服务时,可以认为他们获得了所选用户名的“锁定”。该操作与原子性的比较与设置(CAS)非常相似:将用户名赋予声明它的用户,前提是用户名尚未被使用。
然而,一个硬性的唯一性约束(关系型数据库中常见的那种)需要线性一致性。其他类型的约束,如外键或属性约束,可以不需要线性一致性。
跨通道的时间依赖
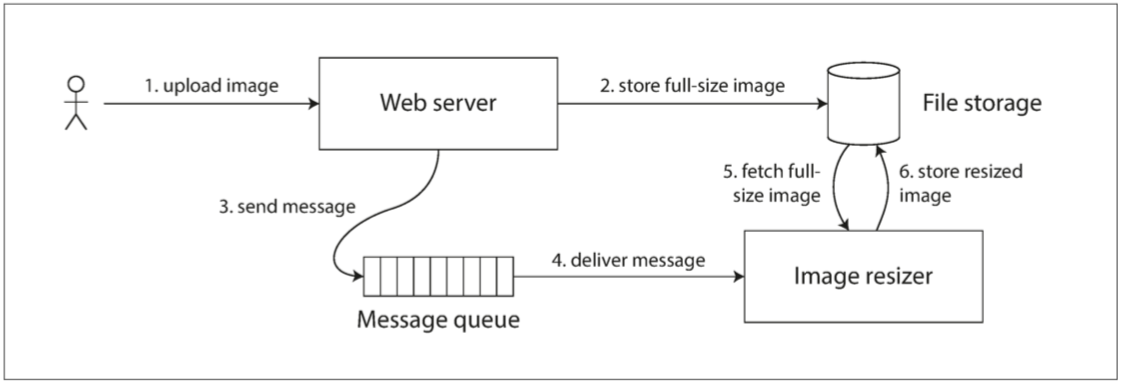
假设有一个网站,用户可以上传照片,一个后台进程会调整照片大小,降低分辨率以加快下载速度(缩略图)。
如果它不是线性一致的,则存在竞争条件的风险:消息队列可能比存储服务内部的复制(replication)更快。
出现这个问题是因为Web服务器和缩放器之间存在两个不同的信道:文件存储与消息队列。没有线性一致性的新鲜性保证,这两个信道之间的竞争条件是可能的。
实现线性化系统
线性化最简单的方案就是只使用一个数据副本,缺点就是无法容错。而关于系统容错,最常见的方法就是使用复制机制。
主从复制部分支持可线性化(只从主节点或者同步更新的节点上面去读取),共识算法也可以支持可线性化。
线性化与quorum
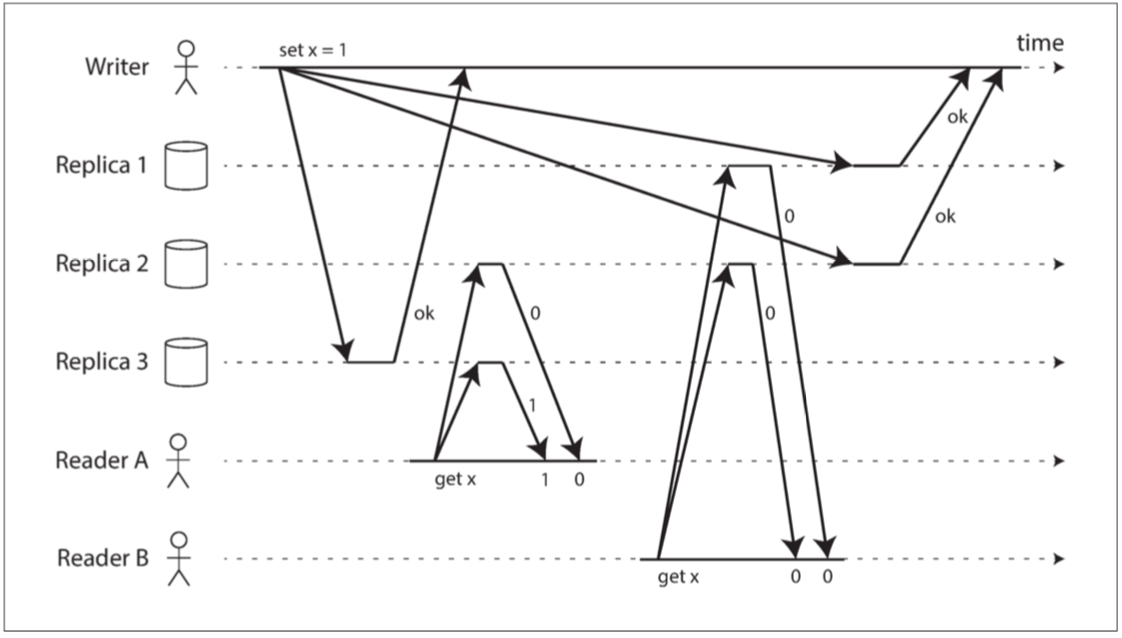
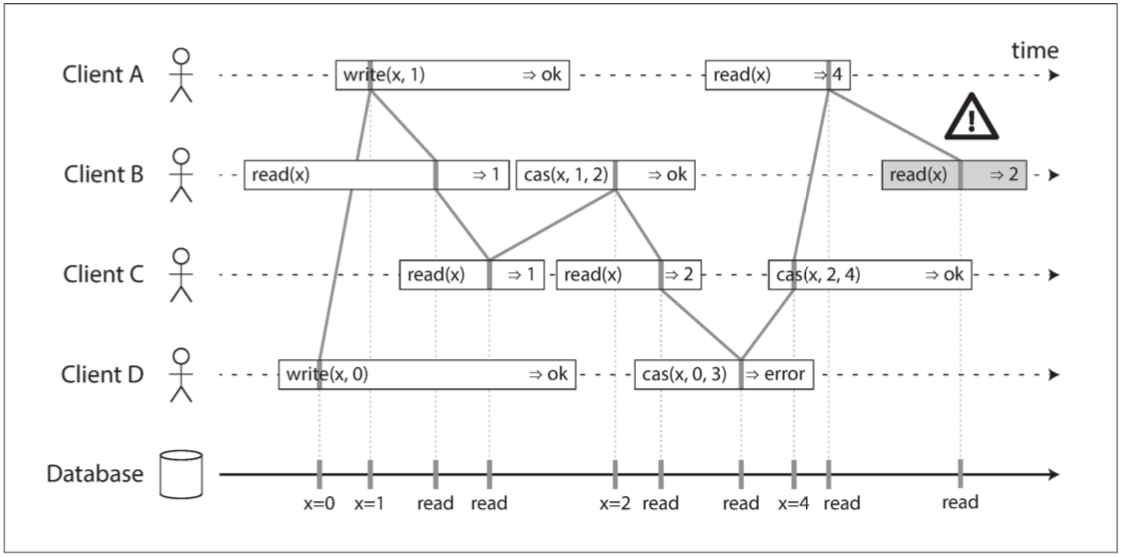
读写严格遵循了quorum,应该会支持可线性化,但是如果遇到了网络延迟,那么就会出现竞争条件。
可以使用Dynamo风格的复制系统,以牺牲性能为代价来满足可线性化:读取者必须在将结果返回给应用之前,同步执行读修复。并且写入者必须在发送写入之前,读取法定数量节点的最新状态。
这种风格只能支持线性读写,并不能支持CAS,CAS需要共识算法的支持。
线性化的代价
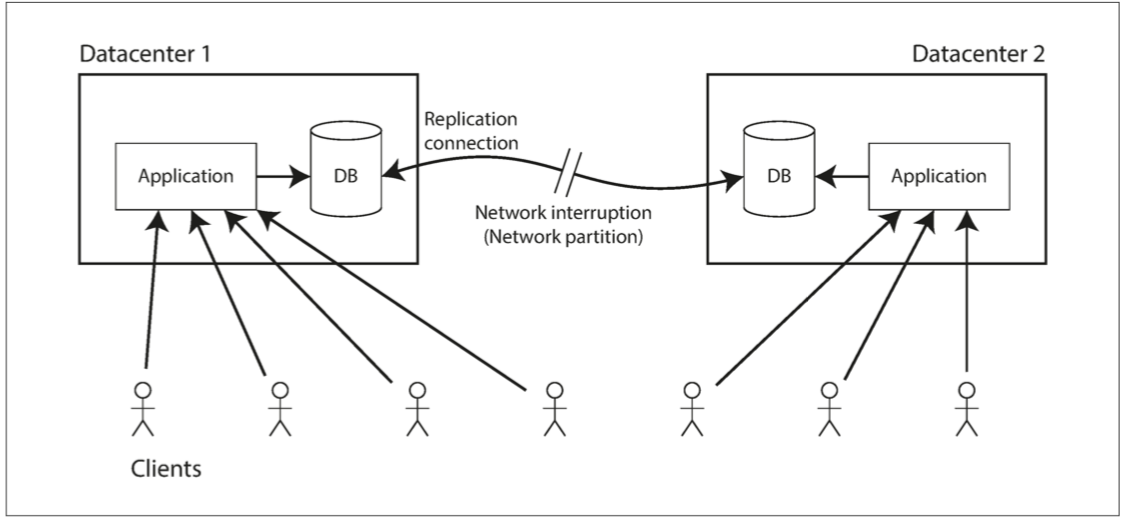
多个数据中心之间网络发生中断,如果数据库基于多主复制,则数据中心内部可以正常运行,期间发生的写操作会暂存在本地队列,等待网络恢复之后重新同步;如果数据库基于主从复制,由于线性读写必须经过主节点,所以连接到从数据中心的客户端无法再联系主节点,也无法完成任何数据的线性写入和读取。
CAP理论
CAP分别指Consistency(一致性),Availablity(可用性),Partition tolerance(分区容错性)。
即便在一个数据中心内部,只要有不可靠的网络,都会发生违背线性化的风险,所以一般分布式系统都具有分区容错性,即由于网络等原因分为多个区域后,每个区域仍然可以自治。
如果严格要求可线性化,那么可以保证CP,丢失可用性,对外不再提供可用服务(例如ZooKeeper);
如果不严格要求可线性化,每个数据中心仍然可以对外提供服务,保证AP,丢失一致性(例如Redis)。
可线性化与网络延迟
多核CPU上的内存就是非线性化,原因是每个CPU核心都有独立的cache和寄存器,之所以放弃线性化,是因为性能,而不是为了容错。
许多分布式数据库也是类似,选择不支持线性化是为了提高性能,而不是为了保住容错特性。
9.3 顺序保证
排序、可线性化和共识之间存在着某种深刻的联系,对于理解系统能做什么以及不能做什么非常有帮助。
顺序与因果关系
因果顺序并非全序
可线性化强于因果一致性
捕获因果依赖关系
序列号排序
非因果序列发生器
Lamport时间戳
时间戳排序依然不够
全序关系广播
使用全序关系广播
采用全序关系广播实现线性化存储
采用线性化存储实现全序关系广播
9.4 分布式事务与共识
原子阶段与两阶段提交
从单节点到分布式的原子提交
两阶段提交
系统的承诺
协调者发生故障
三阶段提交
实践中的分布式事务
Exactly-once消息处理
XA交易
停顿时仍然有锁
从协调者故障之中恢复
分布式事务的限制
支持容错的共识
共识算法与全序广播
主从复制与共识
Epoch和Quorum
共识的局限性
成员与协调服务
节点任务分配
服务发现
成员服务
参考文献
1.ddia中文翻译

 浙公网安备 33010602011771号
浙公网安备 33010602011771号