

流畅的python--第四章
Unicode文本和字节序列
字符串是较简单的概念,一个字符串就是一个字符序列。问题在于“字符”是如何定义的。
在2021年,“字符”的最佳定义是Unicode字符。因此从Python3的str对象中获取的项是Unicode字符。Unicode标准明确区分字符的标识和具体的字节表述。
- 字符的标识,即码点,是
0~1 114 111范围内的数(十进制),在Unicode标准中以4~6个十六进制数表示,前加“U+”,取值范围是
U+0000~U+10FFFF。例如字母A的码点是U+1D11E。 - 字符的具体表述取决于所用的编码。编码是在码点和字节序列之间转换时使用的算法。例如字母
A(U+0041)在UTF-8编码中使用单个字节\x41表述,
而在UTF-16LE编码中使用字节序列\x41\x00表述。再比如,欧元符号(U+20AC)在UTF-8编码中需要3个字节,即\xe2\x82\xac,而在UTF-16LE中,同一个码点编码成两个字节,即\xac\x20.
把码点转换成字节序列的过程叫编码,把字节序列转换为码点的过程叫解码。
![]()

.encode()是编码,将字符序列转为字节序列,为机器核心转储的字节序列,.decode()是解码,为字节序列转为Unicode字符串,为人类可读的文本序列。
字节概要
Python3引入的不可变类型bytes和可变类型bytearray。bytes和bytearray中的项是0~255(含)的整数。

虽然二进制序列其实是整数序列,但是它们的字面量表示法表明其中含有ASCII文本。因此,字节的值可能会使用以下4种不同方式显示。
- 十进制代码在
32~126范围内的字节(从空格到波浪号),使用ASCII字符本身。 - 制表符、换行符、回车符和
\对应的字节,使用转义序列\t,\n,\r和\\。 - 如果字节序列同时包含两种字符串分隔符
'和",整个序列使用'区隔,序列内的'转义为\'。 - 其他字节的值,使用十六进制转义序列(例如,
\x00是空字节)。
因此,在案例b'caf\xc3\xa9'中前三个字节b'caf'在可打印的ASCII范围内,后两个字节则不然。
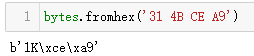
二进制序列有一个类方法是str没有的,名为fromhex,它的作用是解析十六进制数字对,构建二进制序列。
构建bytes或bytearray实例还可以调用各自的构造函数,传入以下参数。
- 一个str对象和encoding关键字参数
- 一个可迭代对象,项为0~255范围内的数
- 一个实现了缓冲协议的对象(例如
bytes,bytearray,memoryview,array.array)。构造函数把源对象中的字节序列复制到新创建的二进制序列中。
使用数组中的原始数据初始化bytes对象

基本的编码解码器
Python自带超过100种编码解码器(codec, encoder/decoder),用于在文本和字节之间相互转换。每种编码解码器都有一个名词,例如'utf-8',而且经常有几个别名,例如'utf8'、'utf-8'和'U8'。
这些名称可以传给open()、str.encode()、bytes.decode()等函数的encoding参数。
使用3种编码解码器编码字符串“El Niño”,得到的字节序列差异很大。

处理编码和解码问题
UnicodeError是一般性的异常,Python在报告错误时通常更具体,抛出UnicodeEncodeError(把str转换成二进制序列时出错)或UnicodeDecodeError(把二进制序列转换为str时出错)。如果源码的编码与预期不符,那么加载
python模块时还可能抛出SyntaxError。
多数非UTF编码解码器只能处理Unicode字符的一小部分子集。把文本转换成字节序列时,如果目标编码没有定义某个字符,则会抛出UnicodeEncodeError,除非把errors参数传给编码方法或函数,做特殊处理。
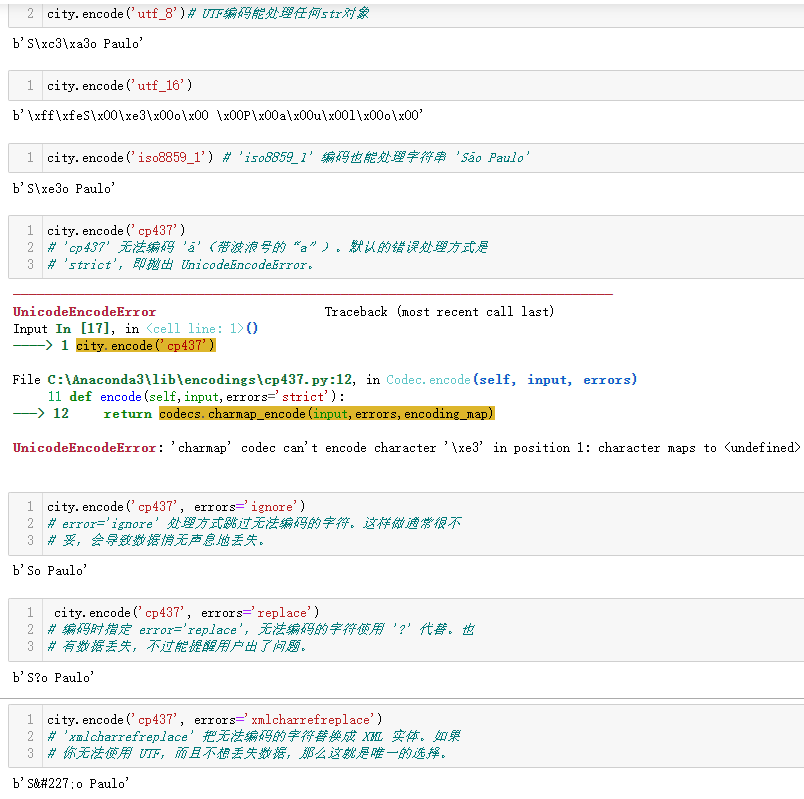
处理UnicodeDecodeError
并非所有字节都包含有效的ASCII字符,也并非所有字节序列都是有效的UTF-8或者UTF-16码点。因此把二进制序列转换成文本时,如果假定使用的是这两个编码中的一个,则遇到无法转换的字节序列时将抛出UnicodeDecodeEncodeError。
另一方面,'cp1252'、'iso8859_1'和'koi8_r'等陈旧的8位编码能解码任何字节序列流(包括随机噪声)
,而不抛出错。因此,如果程序使用错误的8位编码,则可能生成乱码,也不会报错。
乱码字符称为鬼符(
gremlin)或者mojibake(变形文本的日文)。

加载模块时编码不符合预期抛出的SyntaxError
Python3默认使用UTF-8编码源码。如果
加载的 .py 模块中包含 UTF-8 之外的数据,而且没有声明编码,那么将
看到类似下面的消息。
SyntaxError: Non-UTF-8 code starting with '\xe1' in file ola.py on line
1, but no encoding declared; see https://python.org/dev/peps/pep-0263/
for details
GNU/Linux 和 macOS 系统大都使用 UTF-8,因此打开在 Windows 系统
中使用 cp1252 编码的.py 文件时就可能遇到这种情况。注意,这个错
误在 Windows 版 Python 中也可能会发生,因为 Python 3 源码在所有平
台中均默认使用 UTF-8 编码。
为了解决这个问题,可以在文件顶部添加一个神奇的 coding 注释。
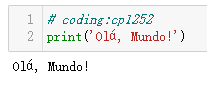
现在,Python 3 源码不再限于使用 ASCII,而是默认使用优秀
的 UTF-8 编码,因此要修正源码的陈旧编码(例如 'cp1252')问
题,最好将其转换成 UTF-8,别去麻烦 coding 注释。如果你用的
编辑器不支持 UTF-8,那么是时候换一个了。
BOM:有用的鬼符
>>> u16 = 'El Niño'.encode('utf_16')
>>> u16
b'\xff\xfeE\x00l\x00 \x00N\x00i\x00\xf1\x00o\x00'
UTF-16编码的序列开头有几个额外的字节,b'\xff\xfe'这是BOM,即字节序标记(byte-order mark),指明编码时使用Intel CPU的小端序。
在小端序设备中,各个码点的最低有效字节在前面。例如,字母 'E' 的
码点是 U+0045(十进制数 69),在字节偏移的第 2 位和第 3 位编码为
69 和 0。
>>> list(u16)
[255, 254, 69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111, 0]
在大端序 CPU 中,编码顺序反过来,'E' 被编码为 0 和 69。
为了避免混淆,UTF-16 编码在要编码的文本前面加上特殊的不可见字
符 ZERO WIDTH NO-BREAK SPACE(U+FEFF)。在小端序系统中,这
个字符编码为 b'\xff\xfe'(十进制数 255, 254)。因为按照设计,
Unicode 标准没有 U+FFFE 字符,在小端序编码中,字节序列
b'\xff\xfe' 必定是 ZERO WIDTH NO-BREAK SPACE,所以编码解码
器知道该用哪个字节序。
UTF-16 有两个变种:UTF-16LE,显式指明使用小端序;UTF-16BE,
显式指明使用大端序。如果直接使用这两个变种,则不生成 BOM。
>>> u16le = 'El Niño'.encode('utf_16le')
>>> list(u16le)
[69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111, 0]
>>> u16be = 'El Niño'.encode('utf_16be')
>>> list(u16be)
[0, 69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111]
如果有 BOM,那么 UTF-16 编码解码器应把开头的 ZERO WIDTH NO- BREAK SPACE 字符去掉,只提供文件中真正的文本内容。根据 Unicode
标准,如果文件使用 UTF-16 编码,而且没有 BOM,那么应该假定使
用的是 UTF-16BE(大端序)。然而,Intel x86 架构用的是小端序,因
此也有很多文件用的是不带 BOM 的小端序 UTF-16 编码。
字节序只对一个字(word)占多个字节的编码(例如 UTF-16 和 UTF- 32)有影响。UTF-8 的一大优势是,不管设备使用哪种字节序,生成的
字节序列始终一致,因此不需要 BOM。尽管如此,某些 Windows 应用
程序(比如 Notepad)依然会在 UTF-8 编码的文件中添加 BOM。而
且,Excel 会根据有没有BOM来确定文件是不是 UTF-8 编码,不然它
就假设内容使用 Windows 代码页(code page)编码。带有 BOM 的
UTF-8 编码,在 Python 注册的编码解码器中叫作 UTF-8-SIG。UTF-8-
SIG 编码的 U+FEFF 字符是一个三字节序列:b'\xef\xbb\xbf'。因
此,如果文件以这三个字节开头,可能就是带有 BOM 的UTF-8文件。
处理文本文件
目前处理文本的最佳实践是"Unicode 三明治"原则。

根据这个原则,我们尽可能:
- 尽早把输入的
bytes解码成str - 程序的业务逻辑处理
str对象 - 对输出来说,尽量晚的把
str编码成bytes
在 Python 3 中,我们可以轻松地采纳“Unicode 三明治”的建议,因为内
置函数 open() 在读取文件时会做必要的解码,以文本模式写入文件时
还会做必要的编码,所以调用 my_file.read() 方法得到的以及传给
my_file.write(text) 方法的都是 str 对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号