Counterfactual VQA: A Cause-Effect Look at Language Bias
Counterfactual VQA: A Cause-Effect Look at Language Bias
Abstract
VQA模型可能倾向于依赖语言偏见作为切入点,因此无法从视觉和语言两个方面充分学习多模态知识。最近提出了一种在推理过程中排除语言先验的借记方法。然而,他们未能从整体上理清“好”的语境和“坏”的语言偏见。在本文中,我们研究了如何减轻VQA中的语言偏见。在因果效应的驱动下,我们提出了一个新的反事实推理框架,它使我们能够将语言偏差作为问题对答案的直接因果效应,并通过从总因果效应中减去直接语言效应来减少语言偏差。实验表明,我们提出的反现实差异框架1)对各种VQA骨架模型和融合策略具有通用性;2)在对语言偏差敏感的VQA-CP数据集上取得了竞争性的性能,而在没有任何增广数据的情况下,在均衡的VQA-v2数据集上表现良好。
1 Introduction
视觉问答(VQA)已经成为支撑许多前沿交互式人工智能系统的基本构件,如视觉对话、视觉和语言导航[6]和视觉常识搜索。VQA系统需要执行可视化分析、语言理解和多模态推理。最近的研究发现VQA模型可能依赖于虚假的语言相关性而不是多模态推理。例如,在VQA v1.0数据集上,只需回答与运动相关的问题“网球”和问题“你看到了吗…”回答“是”,就可以获得大约40%和90%的准确率。因此,如果简单地记忆训练数据中的强语言先验,特别是在最近提出的VQA-CP数据集上,VQA模型将无法很好地推广,因为这些先验在训练集和测试集上是完全不同的。
减轻语言偏见的一个简单的解决方案是通过使用额外的注释或数据扩充来增强训练数据。特别是,视觉和文本注释被用来提高视觉基础能力。此外,反事实训练样本生成有助于平衡训练数据,并在VQA-CP上比其他借记方法有较大的优势。这些方法证明了基于DEBIASED训练的效果,提高了VQA模型的泛化能力。然而,值得注意的是,VQA-CP的提出是为了验证VQA模型是否能将所学的视觉知识和记忆化的语言先验知识分离开来。因此,如何在一个欠偏训练下生成无偏参考成为VQA的一大挑战。另一个流行的解决方案是在训练集中使用一个单独的只问问题的分支来学习语言。在测试阶段,通过去除额外的分支来减轻优先级。然而,我们认为语言优先由“坏”的语言偏见(例如,将香蕉的颜色与主要颜色“黄色”结合起来)和“好”的语言语境(例如,根据问题类型“什么颜色”缩小回答空间)组成。简单地排除额外的分支不能利用好的上下文。事实上,对于最近的去偏见模型来说,将好与坏从整体中分离出来仍然是一个挑战。
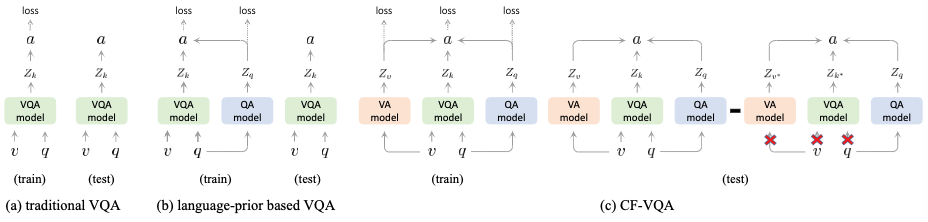
基于反事实推理和因果效应,我们提出了一个新的反事实推理框架CF-VQA来减少VQA中的语言偏见。总的来说,我们将语言偏差描述为问题对答案的直接因果效应,并通过从总的因果效应中减去直接的语言效应来减轻这种偏差。如图1所示,我们引入了两种情景,传统的VQA和反事实的VQA,分别用来估计总的因果效应和直接的语言效应。这两种情况定义如下:
Conventional VQA:如果机器听到问题Q,看到图像V并提取多模态知识K,然后回答答案A。
Counterfactual VQA:如果机器听到问题Q,但是没有看到图像V或者没有提取多模态知识K,那么将会怎么回答A。
传统的VQA当Q和V都起作用的时候能够描述答案。在这种情况下,我们能够猜测V和Q在A上面的总体因果关系。然而,传统的vqa不能将单峰语言关联和多峰推理(即直接和间接效应)分开。因此,我们考虑以下反事实问题:“如果机器没有进行多模态推理,会发生什么?”,这个问题的答案可以通过想象一个场景来获得,在这个场景中机器听到Q,但是没有多模态知识K在没有处理的情况下进行干预,因为V和Q无法被理解的。K无法给Q响应,VQA模型只能依赖于单模态影响。因此,语言偏见可以通过估计Q在A上的直接因果效应,即纯语言效应来识别。训练阶段遵循基于语言优先级的方法,该方法使用流行的VQA模型和单模态分支训练集成模型。在测试阶段,CF-VQA使用去偏见因果效应进行推理,从总效应中减去纯语言效应。也许令人惊讶的是,最近基于语言先验的方法可以作为特例进一步统一到我们提出的反事实推理框架中。特别是,CF-VQA可以很容易地将RUBi提高7.5%,只需再增加一个可学习的参数。实验结果表明,CF-VQA在VQA-CP数据集上大幅度地优于无数据论证的方法,而在平衡的VQA-v2数据集上保持稳定。
本文的主要贡献有三个方面。首先,我们的反事实推理框架是第一个将VQA中的语言偏见模拟为因果效应的框架。第二,我们提供了一个新的因果关系为基础的解释最近的去偏见VQA工作。第三,我们的因果图是通用的,适用于不同的基线VQA架构和融合策略。
2 Related Work
2.1 Language Bias in VQA
可以从两个方面来解释:第一,问题和答案之间存在着很强的相关性,这反映了“语言优先”。在VQA v1.0数据集上,简单回答“网球”与运动相关的问题可以获得大约40%的准确率。其次,提问者倾向于询问图像中看到的对象,这导致了“视觉优先偏见”。在vqav1.0数据集上,只需对所有问题回答“是”就可以获得近90%的准确率。在这两种情况下,机器可能只关注问题,而不是视觉内容。这种严重的捷径限制了VQA模型的泛化,特别是当测试场景与训练场景有很大不同时。
2.2 Debiasing Strategies in VQA
最近,人们提出了一种新的VQA数据,即变先验条件下的可视化问答模型(VQA-CP)。在VQA-CP中,在训练和两个测试阶段,每个问题类型的答案分布是不同的。最近大多数减少VQA语言偏误的解决方案可分为三类,即加强视觉基础,削弱语言优先,以及内隐/外显数据论证。首先,利用人类视觉和文本解释来加强VQA中的视觉基础。第二,基于集成的方法建议在对抗性学习或多任务学习下使用一个单独的QA分支来捕获语言先验。第三,最近的工作自动生成额外的问题图像对来平衡训练数据的分布。本文将基于语言先验的方法作为特例统一到我们提出的反事实推理框架中。
2.3 Causality-inspired Computer Vision
反事实思维和因果推理启发了计算机视觉领域的一些研究,包括视觉解释,场景图生成,图像识别,视频分析,零镜头和少镜头学习,增量学习,表征学习,语义分割和视觉语言任务。特别是,在最近的VQA研究中,反事实学习被利用了。与这些产生反事实训练样本的工作不同,我们的因果关系研究侧重于使用均匀偏差训练数据的反事实推理。
3 Preliminaries
在本节中,我们将介绍使用过的因果关系概念。在下面,我们将随机变量变量表示为大写字母(例如X),并将其观察值表示为小写字母(例如x)。
Causal graph(因果图)
反应变量之间的因果关系,用有向无环图G={V,E}表示,其中V表示变量集,E表示因果关系,下图显示了三个变量组成的因果关系示图。
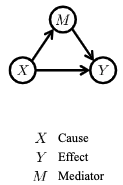
(1)如果X对Y直接影响,则称Y是X的儿子(2)如果X通过M间接影响Y则称M为X和Y之间的调解者。
Counterfactual notations(反事实符号)
用于将因果图转化为公式。
如上图,如果X设置为x,M设置为m,则Y可以表示为:
在实际的场景中上述公式的m表示为:
在反事实的情况下,X对于M和Y而言是设置为其他的值,在反世界的世界中X可以同事设置为\(x\)和\(x^*\)不同的值,如下图所示(白色表示\(X=x\),灰色表示\(X=x^*\)):

Causal effects(因果关系)
反映同一个体在两种不同处理下两种潜在结果的比较 。
将\(X=x\)表示为经过处理的条件,而\(X=x^*\)表示未经过处理的条件。
1.total effect(TE)总效应
当\(X=x\)和\(X=x^*\)两种情况在\(X=x\)作用于\(Y\)上的影响:
2.natural direct effect(NDE)自然直接效应,含义为当中间者(这里是M)不通时,X从\(x^*\)转化为\(x\)时对Y的影响:
3.total indirect effect(TIE)总间接效应:
当然总效应也可以分解成下面两项:
2.natural indirect effect(NIE)自然间接效应,含义是当直接者(这里是X)不通时,中间者M从\(M_{x^*}\)转化为\(M_{x}\)后对Y的影响:
3.total direct effect(TDE)总直接效应:
4 Cause-Effect Look at VQA
按照通常的公式,我们将VQA任务定义为一个多类分类问题。在给定一个图像\(V=v\)和一个问题\(Q=q\)的情况下,VQA模型需要从候选集合\(A={a}\)中选择一个答案。
4.1 Cause-Effect Look
VQA的因果图如下所示 ,Q为问题,V为图像,K为多模态的知识。V和Q在答案A上的影响可以分为多模态影响和单模态单独影响。
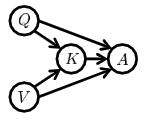
根据反事实符号,当\(V=v\),\(Q=q\)时可以将问题a的分数表示为:
为了简单性省略a:
相似的K可以表示为:
那么VQA的因果图可以表示为
其中\(k=K_{v,q}\)
那么TE(总效应)就为:
正因为VQA的模型能够受到问题和答案之间的伪相关的影响,因此我们要消除这种偏见,就是要相处问题对答案的直接影响,为了实现这一目标,我们提出了反事实VQA来估计\(Q=q\)在\(A=a\)上通过阻断\(K\)和\(V\)的效应的因果效应。反事实的VQA藐视一个\(Q\)为\(q\),\(K\)为\(k^*\),\(V=v^*\),由于中介对输入的响应被阻断,模型只能依赖给定的问题进行决策,因此我们得到了一个NDE(自然直接效应)。下图左边是传统的VQA模型,右边是反事实VQA模型。
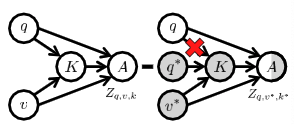
通过反事实VQA得到的自然直接效应为(即捕捉到的语言偏见):
因此消除语言偏见可以视为TE-NDE:
我们使用TIE中最大概率的值来进行推理,而不是原本的\(P(a|v,q)\)
4.2 Implementation
Parameterization
计算\(Z_{q,v,k}\)可以表示为如下
有因为神经网络无法处理空的数据集,因此在反事实VQA中的空集数据使用一个以等概率随机猜测的值替代。
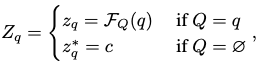
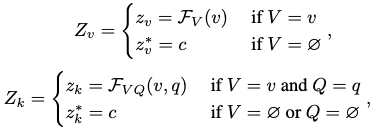
其中\(c\)为可学习的参数,我们使用均匀分布假设有两个原因,首先,对于人类而言,如果我们完全不知道具体的处理方法或问题类型和内容,我们就会随机猜测一个。第二,在计算\(Q\)的NDE时,均匀分布可以保证估计的安全性。我们进一步验证了消融研究中的假设。
Fusion Strategies
我们在这里对函数\(h()\)有两种融合策略:
-
Harmonic (HM)
\[h(Z_q,Z_v,Z_k)=log\frac{Z_{HM}}{1+Z_{HM}} \]其中\(Z_{HM}=\sigma(Z_q)\cdot\sigma(Z_v)\cdot\sigma(Z_k)\)
-
SUM
\[h(Z_q,Z_v,Z_k)=log\sigma(Z_{SUM}) \]其中\(Z_{SUM}=Z_q+Z_v+Z_k\)
Training
损失函数为:
学习参数\(c\)控制\(Z_{q,v^*,k^*}\)的数据分布的跨度。我们假设NDE的跨度应该和TE的相同,否则一个不恰当的结果将导致公式\(TIE=TE-NDE\)变成TE或者NDE主宰。因此我们使用Kullback-Leibler divergence来预测\(c\)。
其中\(p(a|q,v,k)=softmax(Z_{q,v,k})\),\(p(a|q,v^*,k^*)=softmax(Z_{q,v^*,k^*})\),其中\(c\)的更新只与\(L_{kl}\)相关,最终的总损失为:
Inference
如第4.1节所述,我们使用消除偏见因果效应进行推断,其实现如下:
4.3 Revisiting RUBi and Learned-Mixin
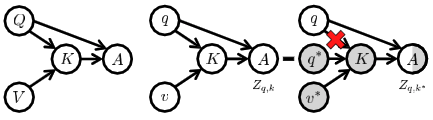
之前的模型与CF-VQA的差别:
这些方法可以统一到我们的反现实框架中,(1)遵循一个简化的因果图(图5(a)),没有直接的路径\(V→A\)、 (2)利用自然间接效应(NIE)进行推断。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号