Underwater object detection using InvertMulti-Class Adaboost with deep learning
Underwater object detection using InvertMulti-Class Adaboost with deep learning
文章介绍
作者根据水下目标检测的特殊性:波长的吸收和散射会显著降低水下图像的质量。直接导致能见度下降、对比度弱、 颜色变化,使得其目标很难被检测出来,并且水下目标检测,在实际的应用中,目标通常很小,并且图像模糊,水下数据集和实际的应用中的数据通常伴随着噪声。上述的问题,使得常用于目标检测的方法,如Faster RCNN等很难达到最佳的效果,因此作者根据水下目标检测的特殊性,进行了模型的优化,提出了创新点。
作者针对水下目标检测中目标小,图像模糊,提出了论文中第一个创新点:使用改进DSSD的网络Sample-Weighted hyPEr Network(SWIPENet)来进行水下目标检测,作者的网络SWIPENet在DSSD网络的基础上添加了空洞卷积,使得在不做pooling损失信息的情况下,增大了感受野,让每个卷积输出都包含较大范围的信息。针对水下数据通常伴随着大量的噪音提出了一种新的重新计算权重的方法,能够重新计算样本的权重,使得模型更好的学习,减少噪声的影响。
模型
SANPLE-WEIGHTE DHYPER NETWORK
SWIPENet为作者在论文中提出的网络,由证据表明,卷积神经网络的下采样导致许多分类任务的成功,然而对于目标检测任务来说是不够的,它不仅需要识别对象的类别,而且需要在空间上定位位置。而且在进行多次的下采样后,由于深层空间的分辨率过于粗糙,难以进行像水下目标检测任务这样存在大量小目标的检测。作者受Deco-nvolutional Single Shot Detector(DSSD) 的启发,提出了SWIPENet。
DSSD扩展了快速下采样框架SSD,它具有多个上采样的反卷积层,以提高特征图的分辨率。在DSDD结构中,首先构造多个下采样卷积层,提取有利于目标分类的高语义特征,由于经过多次下采样操作,特征图过于粗糙,无法提供精确的小目标定位信息,因此增加了多个上采样反卷积层和跳跃连接。以恢复特征图的高分辨率。然而即使分辨率已经恢复,下采样过程中失去的详细信息也无法完全恢复。因此作者改进了DSSD,使用了dilated convolution(空洞卷积),在不做pooling损失信息的情况下,增大了感受野,让每个卷积输出都包含较大范围的信息。
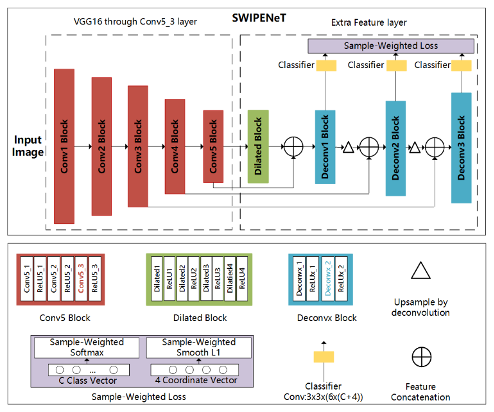
SWIPENet网络结构示意图如下所示,作者根据DSSD进行改进的网络,由卷积块(红色),空洞卷积块(绿色),反卷积块(蓝色)和新的样本加权损失(灰色),跳跃连接组成。跳跃链接将底层精细的特征传递给高层,与DSSD不同的是作者在网络中加入了四个具有ReLU激活的空洞卷积层,可以在不牺牲图像分辨率的前提下或得较大的感受野。三个反卷积层的大小逐渐增加,允许预测多个尺度的对象。
Sample-weighted loss
Sample-weighted loss为作者提出的新的损失函数,它可以在SWIPENet中对样本权重进行建模,使得SWIPENet能够专注于学习高权重的样本而忽略第权重的样本。权重通过Invert Multi-Class Adaboost(IMA)算法进行计算,通过降低权重来减少可能的噪声对SWIPENet的影响。这里我们先介绍损失函数,作者的损失函数由两部分组成,分别为\(L_{cls}\)(分类损失函数)和\(L_{reg}\)(边界框回归损失函数)。其中Num为正样本的默认框数目,\(a_1\) 和\(a_2\)分别为分类和回归损失函数的权重。
其中的\(L_{cls}\)和\(L_{reg}\)如下,其中\(L_{cls}\)分为两部分,前半部分为正样本集的损失,后半部分为负样本的损失,其中\(f(\overline{w_i})\)为样本权重损失中的权重, \(\overline{w_i}\)通过IMA获得, \(f(\cdot)\) 表示权重映射函数,\(pre\_cls_i^c\)和\(gt\_cls_i^c\)分别代表第\(i\)个预测目标和其对应的人工标注样本中的第\(i\)个类别的分数。 \(L_{reg}\)中\(pre\_loc_i^c\)和\(gt\_loc_i^c\)分别表示第\(i\)个预测目标和其对应的人工标注样本中的第\(i\)个元素,其中\(Loc=(cx,cy,w,h)\)。
样本权重通过调用反向传播的梯度来影响特征的学习,假设\(w_{cnn}\)作为SWIPENet的参数, \(w_{cnn}\)的梯度可以表示为\(\frac{\partial L}{\partial w_{cnn}}\),根据前面的损失函数可以将梯度表示为,可以看出\(f(\overline{w_i})\)影响着梯度的第一项和第三项,权重越大,第\(i\)个样本的梯度越大。SWIPENet的特征学习以高权值样本为主,忽略低权值的样本。
Invert Multi-Class Adaboost
SWIPENet可能遗漏或错误的检测到训练集中的某些对象,这些对象被视为噪声数据,这是因为噪声数据非常模糊,与背景相似,因此很容易被识别为背景,如果我们用这些噪声数据来训练SWIPENet,性能可能会受到影响,使得SWIPENet不能区分背景和物体。因此作者使用Invert Multi-Class Adaboost(IMA)来降低不确定对象的权重,使得网络的精确度得到提升。作者所提出的IMA算法的过程如下。
输入为进行训练的图像\(I_{train}\)和其的人工标注特征,和测试用的数据图像\(I_{train}\),首先初始化所有的人工标注特征的权重,\(w_j^1=\frac{1}{N},j=1,2,...,N\),对于每一次的模型前馈(这里一共执行M次)都执行以下的步骤:

-
计算正样本的权重\(f(\overline{w}_i^m )\):如果第\(i\)个正样本在训练过程中匹配第\(i\)个人工标注样本,则将其权重赋予第\(i\)个正样本,\(w_i^m=\overline{w}_i^m\),然后通过映射函数得到\(f(\overline{w}_i^m )\)。
-
根据前馈训练第m次网络。
-
计算第m次网络的误差:作者根据未被发现的物体的百分比进行计算错误率\(E_m\),第\(i\)个人工标注样本被检测到\(I(b_j)=0\)反之则为1。
- 计算第m轮网络在组合模型中的权重。
- 更新人工标注样本的权重。这里与Multi-Class相反,作者选择降低未识别的人工标注样本的权重,强行学习未识别的数据,将会导致网络无法区分背景和物体。
最后得到每次循环的输出,测试集运行过程中,输出所有M个检测集,其中第m个集合为\(D_m=\{d_1,d_2,...,d_i\},d_i=(cls,score,cx,cy,w,h)\),将每个检测目标的得分乘以网络的权重进行重新计算得分,最后通过非最大抑制去除重叠检测。
The mapping fuction
由于在初始化每个人工标注样本的权重为\(\frac{1}{N}\),并初始化每个正样本在样本权重损失中为\(1\),作者在这里凭直觉认为这种映射关系为N倍关系。即映射函数\(f(\cdot)为\):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号