2.机器学习之KNN算法
K-最近邻(k-Nearest Neighbor,KNN)分类算法:
数据分析当中KNN通过测量不同特征值之间的距离来进行分类的。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,所选择的邻居都是已经正确分类的对象,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中特征最相近的数据(最近邻)的分类标签;即利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
一般而言,我们只选择样本数据集中前k个最相似的数据,这就是KNN算法中K的由来,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的类别,作为新数据的分类。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
kNN算法的核心思想是:如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。打个比方:你们想了解我是个怎样的人,然后你们发现我的身边关系最密切的朋友是一群逗逼,所以你们可以默认我也是一个逗逼。
例如:如下图所示,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,因此绿色圆被赋予红色三角形那个类;如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。

算法的实现步骤:
1)算距离:计算测试数据与各个训练数据之间的距离,按照距离的递增关系进行排序;
2)找邻居:选取(圈定)距离最小的K个点,作为待分类样本的近邻;
3)做分类:确定前K个点所在类别的出现频率,返回前K个点中出现频率最高的类别作为测试数据的预测分类(根据这K个近邻中的大部分样本所属的类别来决定待分类样本该属于哪个分类)。
实现原理:
欧式距离又称欧几里得度量(euclidean metric),源自欧氏空间中两点间的距离公式,是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
二维空间下,欧式距离计算公式:
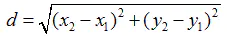
d表示坐标(x1,y1)到坐标(x2,y2)之间的直线距离。
三维空间下,欧式距离计算公式:

n维空间下,欧式距离计算公式:

k值的选择:
k越大,即使用交大的领域中的样本进行预测,训练误差会增大,模型会变得简单,容易导致欠拟合。
KNN特点:
KNN是一种非参的;惰性的算法模型;适用数据范围:数值型和标称型。
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。
KNN算法的优势和劣势:
了解KNN算法的优势和劣势,可以帮助我们在选择学习算法的时候做出更加明智的决定。
优势:
1. 思想简单,理论成熟,易于理解,易于实现,既可以用来做分类也可以用来做回归(knn的回归效果不好,很少用);
2. 无需估计参数,即无数据输入假定(对数据没有假设),惰性的,无需训练或者说模型训练时间快;
3. 精度高,预测效果好,对异常值不敏感;
4. 特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
劣势:
1. 计算复杂度高:必须对数据集中的每个数据计算距离值,计算量大,时间开销大,预测阶段可能很慢;
2. 空间复杂度高:法必须保存全部数据集,存储空间需求大,需要大量的内存;
3. 对于样本分类不均衡的问题会产生误判,即对样本容量较小的类域很容易产生误分;
4. 输出的可解释性不强,无法给出任何数据的基础结构信息,无法知晓平均实例样本和典型实例样本具有什么特征。
决策规划:
分类:多数表决法、加权多数表决法。
回归:平均值法、加权平均值法。
简单得说,当需要使用分类算法,且数据比较大的时候就可以尝试使用KNN算法进行分类了。 knn 的计算量大,所以可以提前算好,下一次直接使用(可事先离线训练好)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号