Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系、地图数据、或是基因信息等等。RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘。NoSQL数据库的兴起,很好地解决了海量数据的存放问题,图数据库也是NoSQL的一个分支,相比于NoSQL中的其他分支,它很适合用来原生表达图结构的数据。
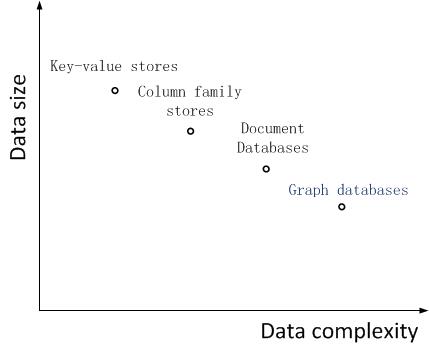
下面一张图说明,相比于其他NoSQL,图数据库存放的数据规模有所下降,但是更能够表达复杂的数据。
通常来说,一个图数据库存储的结构就如同数据结构中的图,由顶点和边组成。
Neo4j是图数据库中一个主要代表,其开源,且用Java实现。经过几年的发展,已经可以用于生产环境。其有两种运行方式,一种是服务的方式,对外提供REST接口;另外一种是嵌入式模式,数据以文件的形式存放在本地,可以直接对本地文件进行操作。
Neo4j简介
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
图形数据结构
在一个图中包含两种基本的数据类型:Nodes(节点) 和 Relationships(关系)。Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
从这几个方面来说,Neo4j是一个合适的选择。Neo4j……
- 自带一套易于学习的查询语言(名为Cypher)
- 不使用schema,因此可以满足你的任何形式的需求
- 与关系型数据库相比,对于高度关联的数据(图形数据)的查询快速要快上许多
- 它的实体与关系结构非常自然地切合人类的直观感受
- 支持兼容ACID的事务操作
- 提供了一个高可用性模型,以支持大规模数据量的查询,支持备份、数据局部性以及冗余
- 提供了一个可视化的查询控制台,你不会对它感到厌倦的
什么时候不应使用Neo4j?
作为一个图形NoSQL数据库,Neo4j提供了大量的功能,但没有什么解决方案是完美的。在以下这些用例中,Neo4j就不是非常适合的选择:
- 记录大量基于事件的数据(例如日志条目或传感器数据)
- 对大规模分布式数据进行处理,类似于Hadoop
- 二进制数据存储
- 适合于保存在关系型数据库中的结构化数据
neo4j存储模型

The node records contain only a pointer to their first property and their first relationship (in what is oftentermed the _relationship chain). From here, we can follow the (doubly) linked-list of relationships until we find the one we’re interested in, the LIKES relationship from Node 1 to Node 2 in this case. Once we’ve found the relationship record of interest, we can simply read its properties if there are any via the same singly-linked list structure as node properties, or we can examine the node records that it relates via its start node and end node IDs. These IDs, multiplied by the node record size, of course give the immediate offset of both nodes in the node store file.
上面的英文摘自<Graph Databases>(作者:IanRobinson) 一书,描述了 neo4j 的存储模型。Node和Relationship 的 Property 是用一个 Key-Value 的双向列表来保存的; Node 的 Relatsionship 是用一个双向列表来保存的,通过关系,可以方便的找到关系的 from-to Node. Node 节点保存第1个属性和第1个关系ID。
通过上述存储模型,从一个Node-A开始,可以方便的遍历以该Node-A为起点的图。下面给个示例,来帮助理解上面的存储模型,存储文件的具体格式在第2章详细描述。
示例1

在这个例子中,A~E表示Node 的编号,R1~R7 表示 Relationship 编号,P1~P10 表示Property 的编号。
- Node 的存储示例图如下,每个
Node保存了第1个Property和 第1个Relationship:![]()
- 关系的存储示意图如下:
![]()
从示意图可以看出,从 Node-B 开始,可以通过关系的 next 指针,遍历Node-B 的所有关系,然后可以到达与其有关系的第1层Nodes,在通过遍历第1层Nodes的关系,可以达到第2层Nodes,…


参考:http://www.cnblogs.com/ljhero/archive/2012/05/13/2498039.html
http://www.cnblogs.com/ljhero/archive/2012/05/13/2498039.html
底层原理:http://sunxiang0918.cn/2015/06/27/neo4j-%E5%BA%95%E5%B1%82%E5%AD%98%E5%82%A8%E7%BB%93%E6%9E%84%E5%88%86%E6%9E%90/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号