注意力机制里的qkv——目前讲解得最清晰的注意力机制
💬 例子:一句话 “The animal didn’t cross the street because it was too tired.”
我们要理解这句话中 “it” 指的是什么。
直觉告诉你,“it” 是指 “the animal” 而不是 “the street”。
而注意力机制,神奇的地方就在于:模型能自动学出这种语义依赖!
⚙️ 一、输入表示(词向量)
假设我们把句子拆成 tokens:["The", "animal", "didn't", "cross", "the", "street", "because", "it", "was", "too", "tired"]
每个词有一个向量表示,例如(简化为二维):
| 词 | 向量 (embedding) |
|---|---|
| The | [0.2, 0.1] |
| animal | [0.9, 0.8] |
| street | [0.7, 0.1] |
| it | [0.5, 0.5] |
| tired | [0.1, 0.9] |
🔁 二、计算 Self-Attention(理解 “it”)
当模型在处理当前位置 “it” 时:
- 它会生成一个 Query 向量 Q₍ᵢₜ₎。
- 同时,每个词也都有自己的 Key 向量 K(即它“展示给别人看”的信息)。
然后模型计算每个 Key 对 “it”的相关程度:
| 被关注的词 | 相似度(Q·Kᵀ) | 含义 |
|---|---|---|
| The | 0.2 | 几乎不相关 |
| animal | 0.9 | 非常相关 |
| street | 0.1 | 不相关 |
| it | 1.0 | 自身最相关 |
| tired | 0.3 | 稍有关系 |
Softmax 之后得到注意力权重:
| 词 | 注意力权重 |
|---|---|
| The | 0.05 |
| animal | 0.45 |
| street | 0.02 |
| it | 0.4 |
| tired | 0.08 |
🧩 三、加权求和(汇聚语义)
然后将这些权重乘以它们各自的 V(Value 向量)——
也就是每个词真正包含的语义特征。
加权求和之后,“it”的新表示中:
-来自 “animal” 的特征占了近一半;
-来自 “it” 自身占了 0.4;
-几乎不受 “street” 影响。
最终结果表示:
“it” 的含义 ≈ “animal” 的语义。
🌈 四、这体现了注意力的关键特点
| 特点 | 说明 |
|---|---|
| 动态性 | 不同位置的 Query(例如 “it” 或 “street”)会关注不同词。 |
| 信息聚合 | 当前词的表示由全局上下文加权求和得到。 |
| 可解释性 | 你能可视化看到 “it” 关注了哪几个词。 |
🧭 换句话说:
注意力机制让模型在“理解一个词时”,不只是看它自己,而是去找句子里谁和它最有关系。
从零开始构建大模型一书中讲解得最清晰:
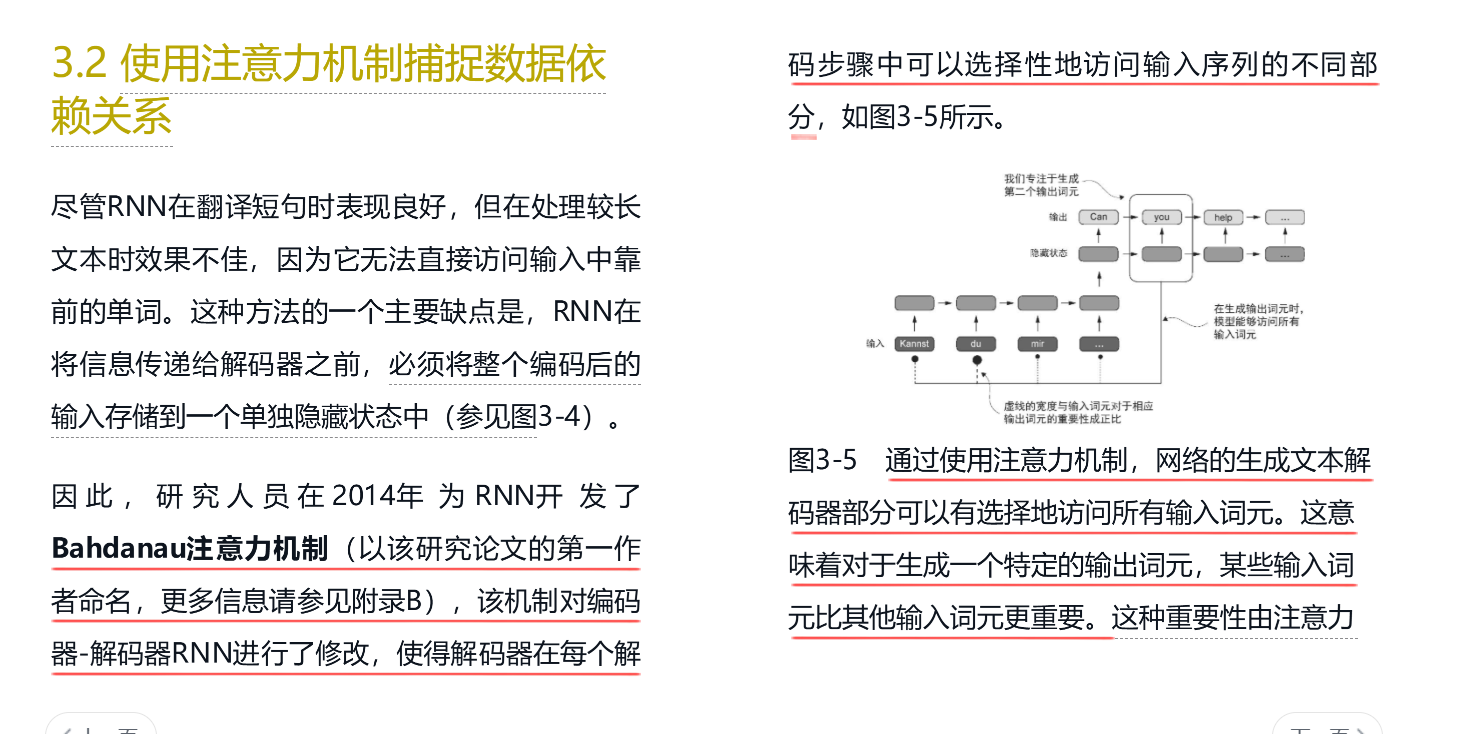








理由,点积还有一个几何等价定义:
a⋅b=∥a∥⋅∥b∥⋅cosθ
θ:它们之间的夹角
点积大(特别是正且接近最大值) ⇒ 向量方向接近 ⇒ 相似度高
点积接近 0 ⇒ 向量近乎正交 ⇒ 基本无关
点积为负 ⇒ 向量方向相反 ⇒ 语义上可能“对立”
如果我们先把向量都归一化为单位向量:点积 = 余弦相似度(cosine similarity)。因此,点积天然就能用来表示“方向相似度”;
这就是为什么在机器学习中,用「点积」衡量相似性是非常自然又高效的做法。


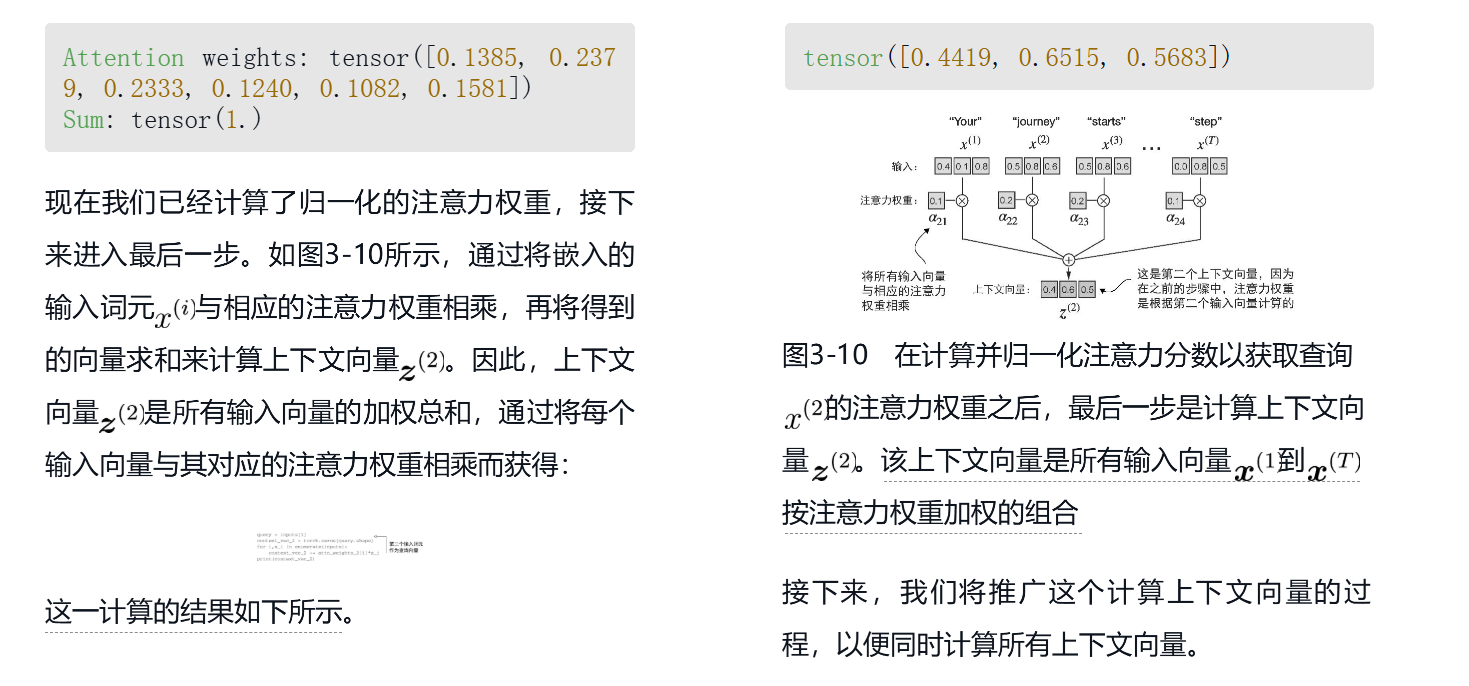






其实自注意力机制核心总结下来就是:
为了实现一个根据上下文变动的注意力向量数值。步骤:
传统embedding计算向量 --》两两计算相似度 --》获得当前单词和所有单词的权重 --》加权求和 --》即可获得当前单词(q)的注意力向量
为了让模型可以学习更新,所以引入了Wq、Wk,Wv,使其可以学习更新,因此QKV:

无非就是上面简单计算里引将原始的了embedding经过了Wqkv以后进行了一次神经网络的转换而已。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号