
【ElasticSearch】【Docker】docker 容器添加ik分词插件
这里不建议进入容器下载插件,因为是在是太慢了!并且容器提供的指令是有限的!!!
先去github下载ik分词器的插件:
https://github.com/medcl/elasticsearch-analysis-ik/releases
必须下载和当前es对应的版本,例如:我当前es是7.6.2,对应的ik分词插件也应该是7.6.2版本
我这里已经下载好了,然后进行解压,然后拷贝到docker容器即可:
docker cp ~/Downloads/elasticsearch-analysis-ik-7.6.2 elasticsearch:/usr/share/elasticsearch/plugins/
然后重启es,如看到如下日志:
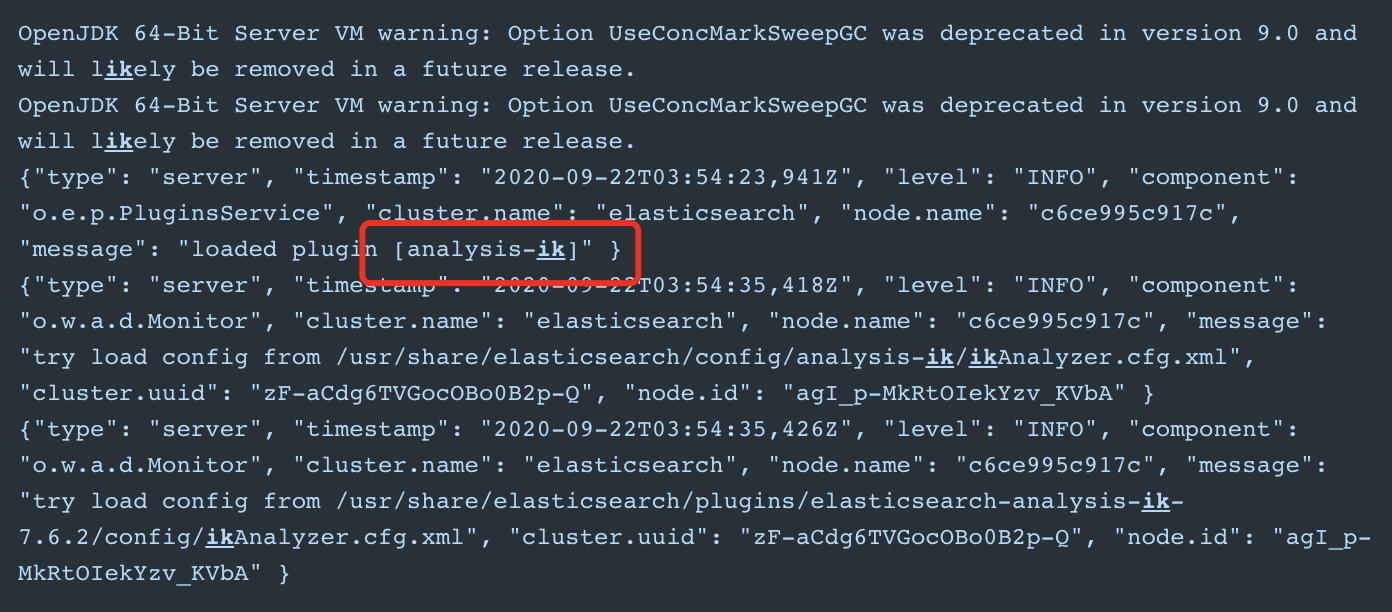
此时ik分词已经生效!
- 我们这里可以测试一下这个ik分词器,打开kibana
ik提供了两种分词算法:
ik_smart 最少切分
ik_max_word 最细粒度切分
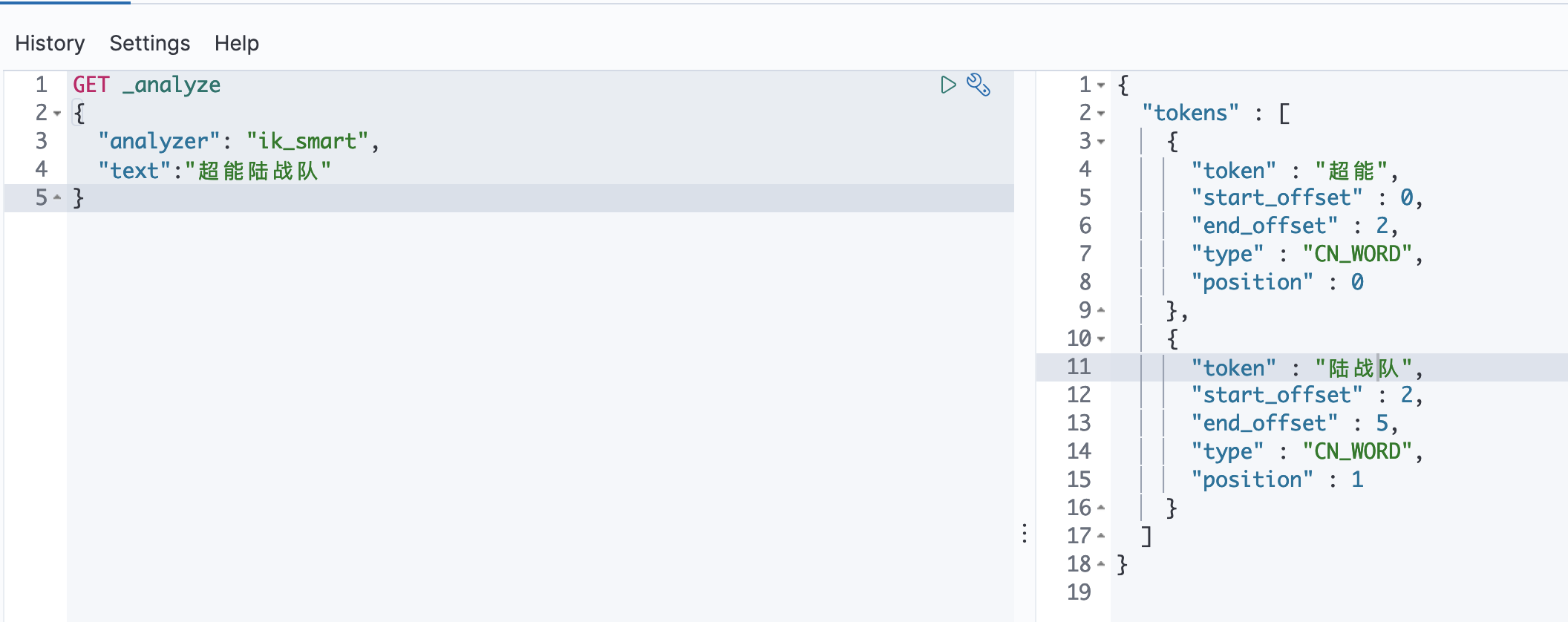
1》我们先测试一下最少切分:
GET _analyze { "analyzer": "ik_smart", "text":"超能陆战队" }
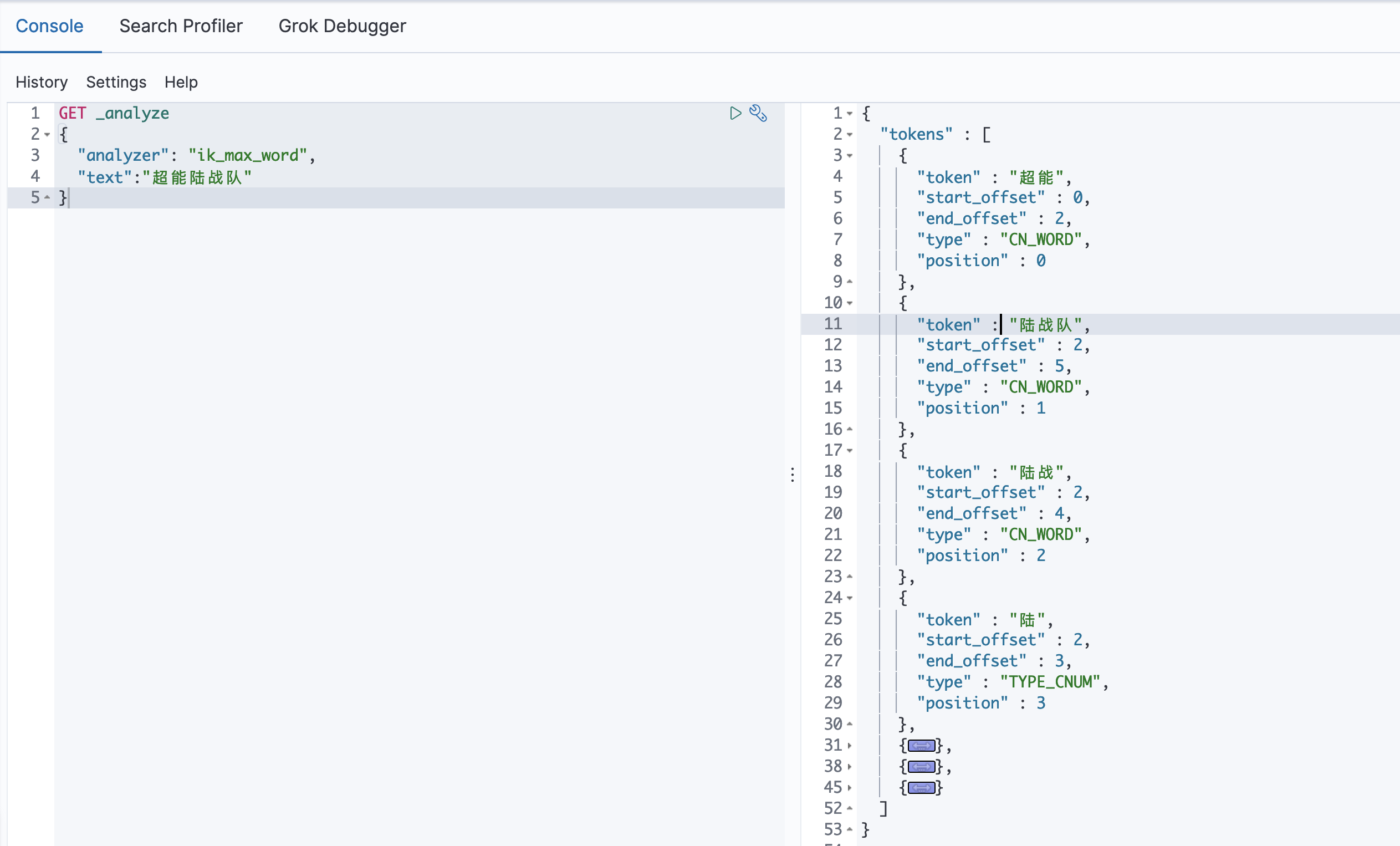
2》我们再测试一下最细粒度切分:
GET _analyze { "analyzer": "ik_max_word", "text":"超能陆战队" }
- 这些都是es原声给我提供的分词功能,但是我们再试一个词:
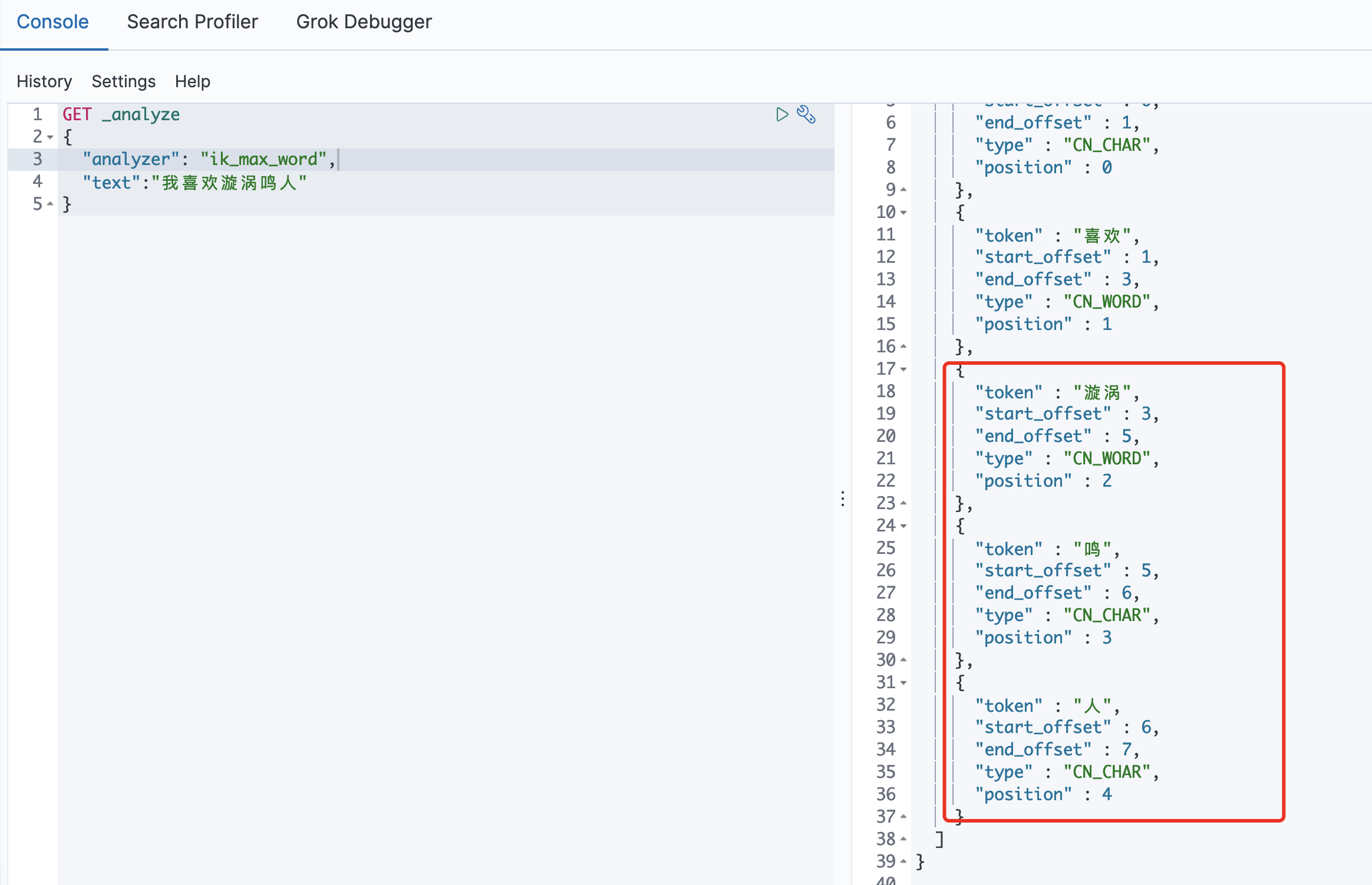
可以看到,【漩涡鸣人】其实我们认为是一个词,但是es默认将这个词分开了,
所以我们需要手动将【漩涡鸣人】这个词添加到分词器中:
1》我们先进入到目录【/usr/share/elasticsearch/plugins/elasticsearch-analysis-ik-7.6.2/config/】,
找到对应的分词文件:

2》然后我们把【漩涡鸣人】添加进分词文件中,先创建一个【my.dic】:

把【漩涡鸣人】填进去:
3》然后在把【my,dic】放进分词配置中:
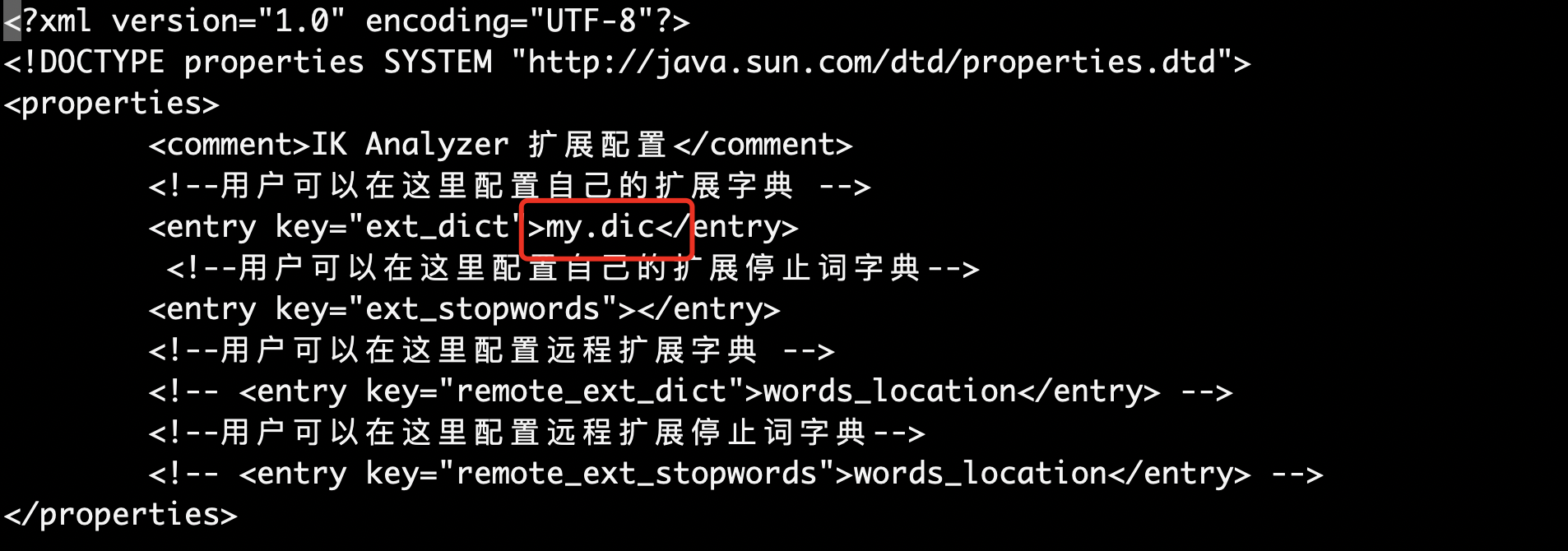
4》然后重启es我们看一下效果:
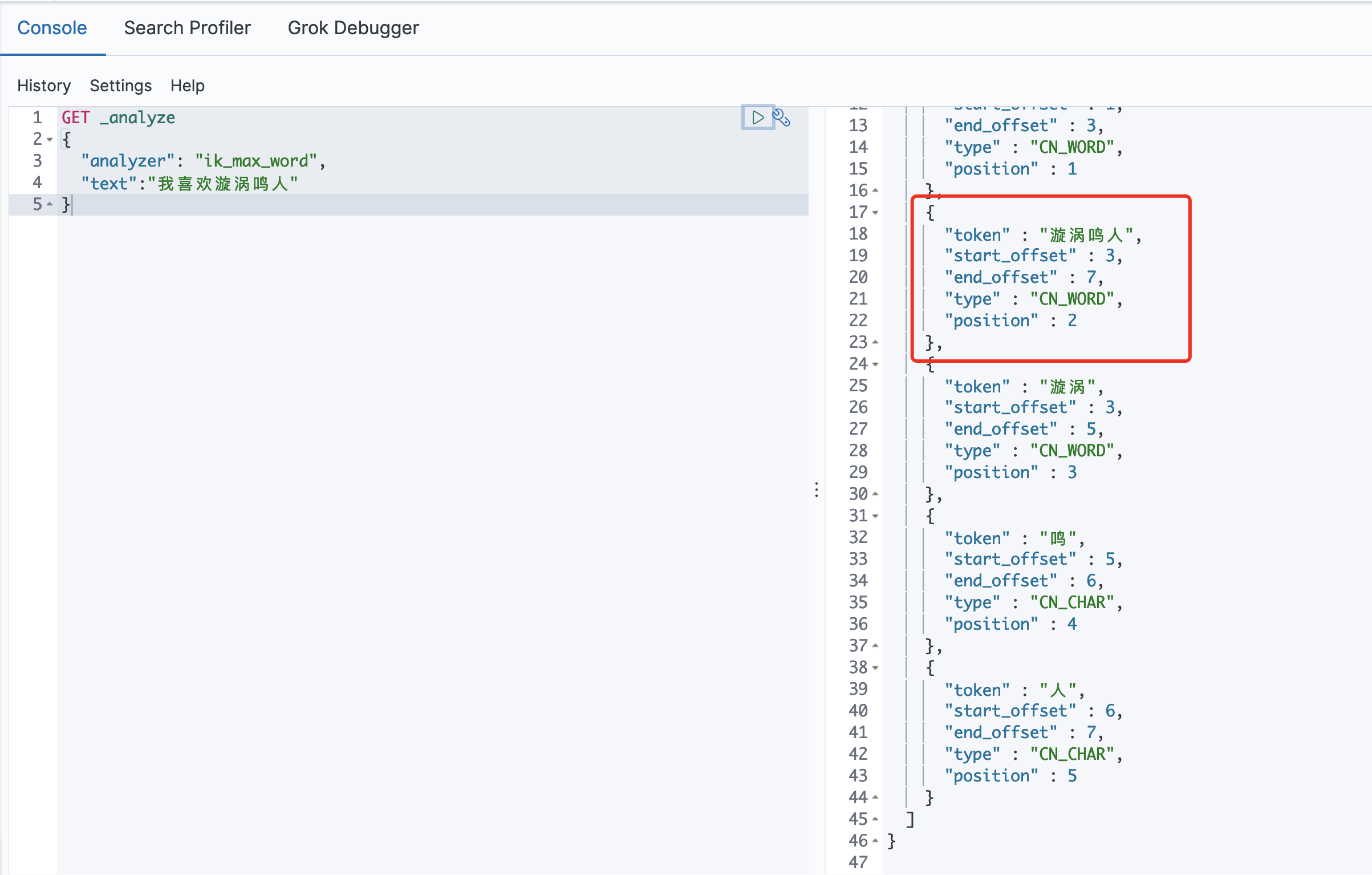
此时我们手动分词语句,可以看到【漩涡鸣人】完整展示出,说明我们手动加入分词成功!
所以其实生产环境也是一样,很有词需要我们手动加入到分词器中!
学而不思则罔 思而不学则殆 !

 浙公网安备 33010602011771号
浙公网安备 33010602011771号