Hadoop的Job提交流程源码解析
Job提交流程其实流程图的话,已经满天飞了,我也没有搬过来的必要,主要是流程图背后发生了什么,这些事情为什么发生,为什么Hadoop的WordCount本地开发也能运行,同样的代码是怎么提交到集群上的,这些问题如果不看源码, 基本都不会知道的,我就简单分析一下吧
: : 若有错误和不足的地方请直接指出来不用客气,技术这个东西0就是0,1就是1,容不得马虎
: : 其次,能看到这篇文章的人,基本都是入门或者进阶的人了,很多概念我就不再阐述了哈
那就还是以大数据入门标准的大项目WordCount为例来讲一下(Java):
先简单的画一下流程,强烈建议对比这个流程图看这篇源码,流程图的序号和正文的序号一一对应,否则直接往下看你会蒙圈的
流程图如下:
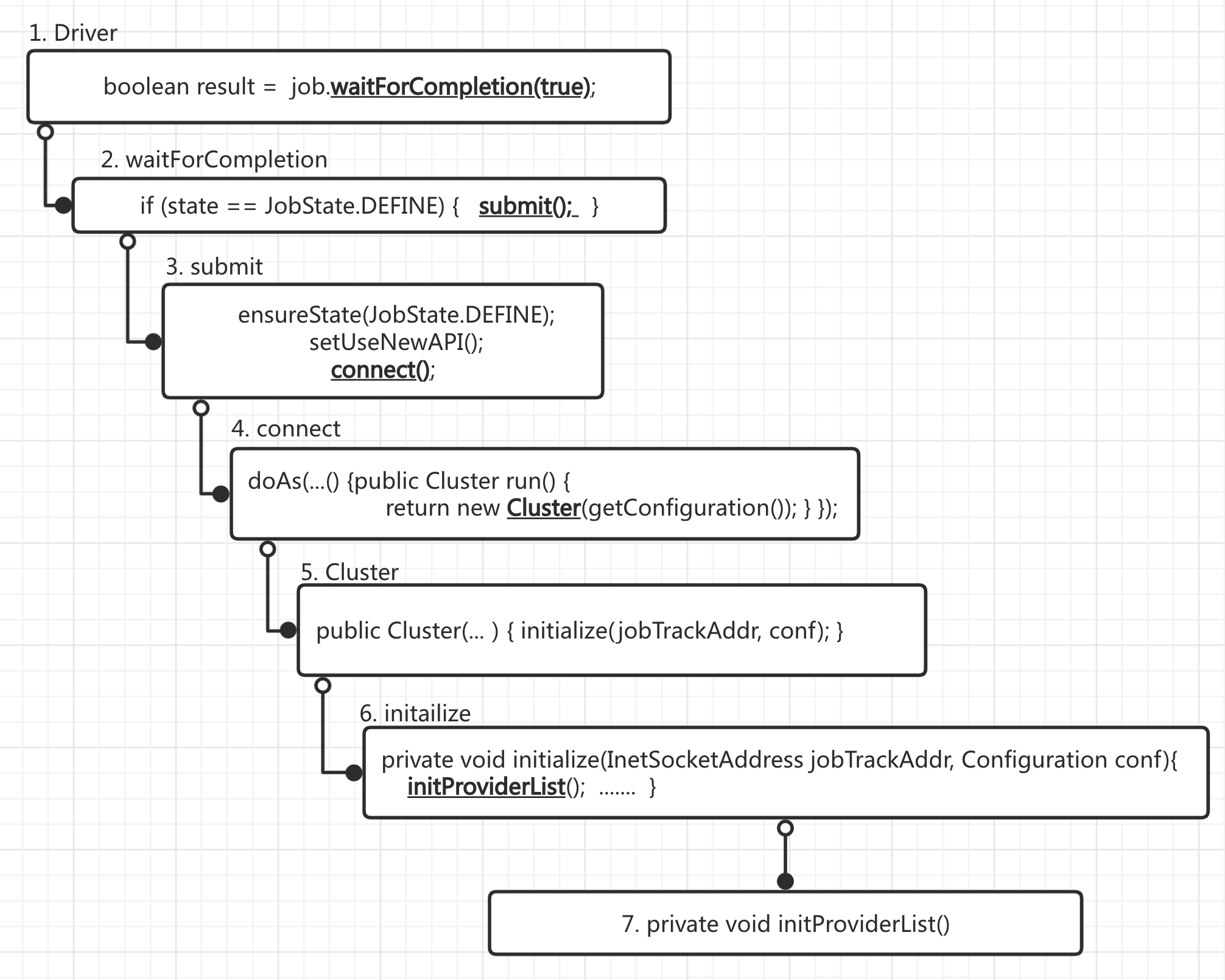
流程比较粗略,且没有展开所有类
1. Mapper和Reducer暂时略过,看Driver提交Job(waitForCompletion)
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//获取job对象,设置jar存放路径,关联Map和Reduce类,设置mapper阶段输出数据类型,设置最终数据输出的数据类型,设置输入路径和输出路径
...
//提交job
boolean result = job.waitForCompletion(true);
System.out.println(result ? 0 : 1);
}
}
2. waitForCompletion如下
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) { //判断JobState,也就是常见的RUNNING,ACCEPT,KILLED等等
submit(); //然后提交
}
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}
3. 进入submit之后如下:
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE); //判断任务状态,若状态错误则抛出异常
setUseNewAPI(); //这个是由于很多API过时了,需要用新的API来代替,主要是提高兼容性的作用
connect(); //重点,下面讲
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
4. connect()
private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) { //判断cluster是否为空,若为空,则往下,因为本地提交
cluster =
ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
return new Cluster(getConfiguration());
}
});
}
}
这里看源码的话比较晦涩,doAs进去之后建议直接StepOut,直接return new Cluster(getConfiguration()),这样对于流程的理解会好一些,否则doAs里面的步骤太多,容易走丢
5. Cluster(getConfiguration())返回cluster集群信息
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
this.conf = conf;
this.ugi = UserGroupInformation.getCurrentUser();
initialize(jobTrackAddr, conf); //在这里,初始化了集群的信息,包括配置文件,
}
这里面的conf,返回的就是各种${HADOOP_HOME}/etc/hadoop里面的配置文件,最后是以XML的集合形式存放
6. initialize(jobTrackAddr, conf)执行初始化集群配置相关信息
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
initProviderList();
....... //这里开始其实就是初始化之后的一系列动作,包括判断初始化是否成功,初始化JobTracker等等相关的返回信息,有兴趣可以去Hadoop-3.1.2源码里面查看Cluster.java的116~150行
}
7. 紧接着initProviderList()里面,开始初始化各种信息
private void initProviderList() {
if (providerList == null) {
synchronized (frameworkLoader) {
if (providerList == null) { //如果用户提交没有配置信息,则下面开始初始化LocalProviderList,
//这也就是如果本地测试运行时,clientProtocol为什么会返回org.apache.hadoop.LocalJobRunner@XXX的原因
List<ClientProtocolProvider> localProviderList =
new ArrayList<ClientProtocolProvider>();
try {
for (ClientProtocolProvider provider : frameworkLoader) {
localProviderList.add(provider);
}
} catch(ServiceConfigurationError e) {
LOG.info("Failed to instantiate ClientProtocolProvider, please "
+ "check the /META-INF/services/org.apache."
+ "hadoop.mapreduce.protocol.ClientProtocolProvider "
+ "files on the classpath", e);
}
providerList = localProviderList;
}
}
} //当然,若providerList有东西,说明是提交到集群上,并且拿到了相关配置信息,就直接退出这个方法了
}
走出上面这里,就返回doAs里面了,里面已经拿到了集群的信息了,然后走出connect(),往下走,final阶段提交之前会获取一些job提交者(submitter)的相关信息,然后设置state = JobState.RUNNING; 在这之后任务就开始运行了,任务运行过程中还有很多监控和任务信息的实时获取,比如循环获取map和reduce的任务进度,提交者信息获取等等很多信息,后面有机会在挖一下,提交的流程就在这里了,有兴趣的可以自己更详细的看一下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号