
网络协议学习笔记(七)流媒体协议和P2P协议
概述
上一篇讲解了http和https的协议的相关的知识,现在我们谈一下流媒体协议和P2P协议。
流媒体协议:如何在直播里看到美女帅哥
最近直播比较火,很多人都喜欢看直播,那一个直播系统里面都有哪些组成部分,都使用了什么协议呢?无论是直播还是点播,其实都是对于视频数据的传输。一提到视频,大家都爱看,但是一提到视频技术,大家都头疼,因为名词实在是太多了。
三个名字系列
名词系列一:AVI、MPEG、RMVB、MP4、MOV、FLV、WebM、WMV、ASF、MKV。例如 RMVB 和 MP4,看着是不是很熟悉?
名词系列二:H.261、 H.262、H.263、H.264、H.265。这个是不是就没怎么听过了?别着急,你先记住,要重点关注 H.264。
名词系列三:MPEG-1、MPEG-2、MPEG-4、MPEG-7。MPEG 好像听说过,但是后面的数字是怎么回事?是不是又熟悉又陌生?
这里,我想问你个问题,视频是什么?我说,其实就是快速播放一连串连续的图片。每一张图片,我们称为一帧。只要每秒钟帧的数据足够多,也即播放得足够快。比如每秒 30 帧,以人的眼睛的敏感程度,是看不出这是一张张独立的图片的,这就是我们常说的帧率(FPS)。每一张图片,都是由像素组成的,假设为 1024*768(这个像素数不算多)。每个像素由 RGB 组成,每个 8 位,共 24 位。我们来算一下,每秒钟的视频有多大?30 帧 × 1024 × 768 × 24 = 566,231,040Bits = 70,778,880Bytes如果一分钟呢?4,246,732,800Bytes,已经是 4 个 G 了。
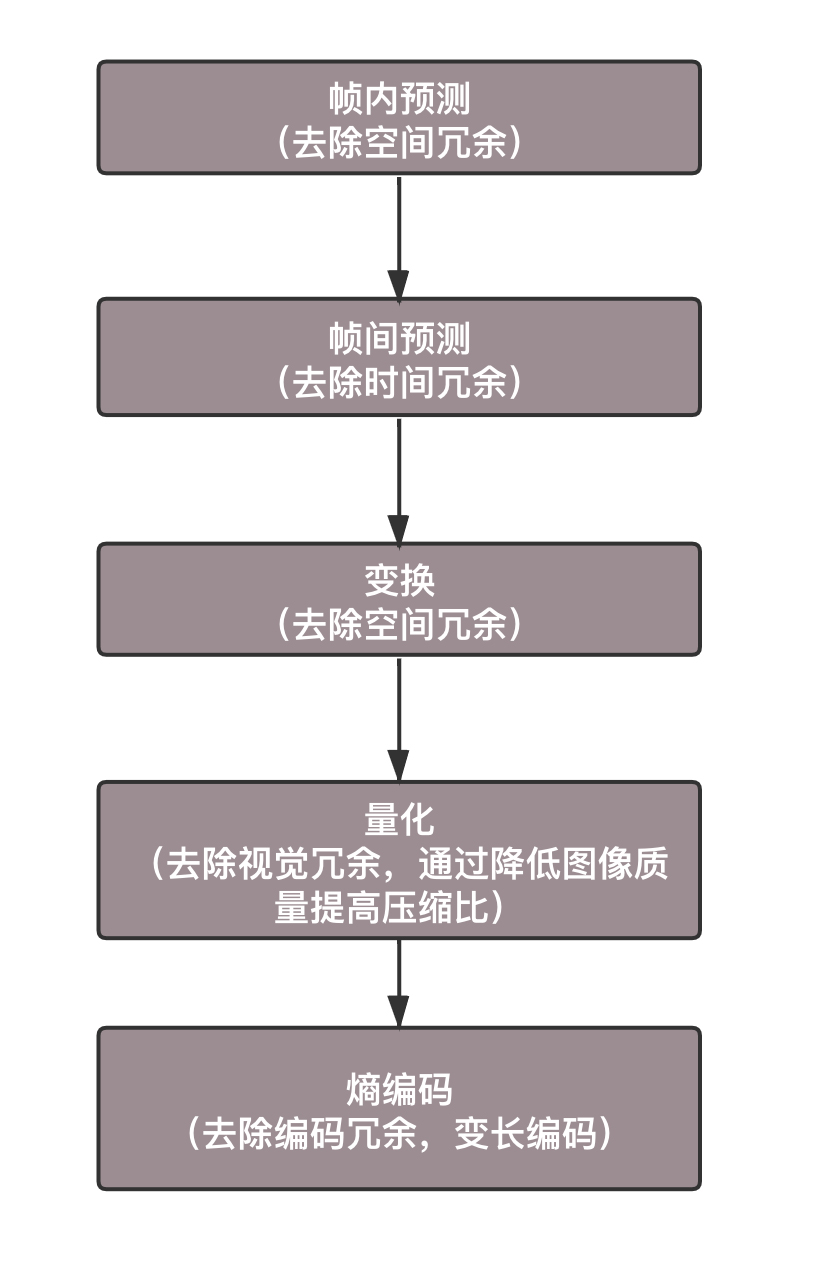
是不是不算不知道,一算吓一跳?这个数据量实在是太大,根本没办法存储和传输。如果这样存储,你的硬盘很快就满了;如果这样传输,那多少带宽也不够用啊!怎么办呢?人们想到了编码,就是看如何用尽量少的 Bit 数保存视频,使播放的时候画面看起来仍然很精美。编码是一个压缩的过程。
视频和图片的压缩过程有什么特点?
之所以能够对视频流中的图片进行压缩,因为视频和图片有这样一些特点。
空间冗余:图像的相邻像素之间有较强的相关性,一张图片相邻像素往往是渐变的,不是突变的,没必要每个像素都完整地保存,可以隔几个保存一个,中间的用算法计算出来。
时间冗余:视频序列的相邻图像之间内容相似。一个视频中连续出现的图片也不是突变的,可以根据已有的图片进行预测和推断。
视觉冗余:人的视觉系统对某些细节不敏感,因此不会每一个细节都注意到,可以允许丢失一些数据。
编码冗余:不同像素值出现的概率不同,概率高的用的字节少,概率低的用的字节多,类似霍夫曼编码(Huffman Coding)的思路。
总之,用于编码的算法非常复杂,而且多种多样,但是编码过程其实都是类似的。
视频编码的两大流派
能不能形成一定的标准呢?要不然开发视频播放的人得累死了。当然能,我这里就给你介绍,视频编码的两大流派。
流派一:ITU(International Telecommunications Union)的 VCEG(Video Coding Experts Group),这个称为国际电联下的 VCEG。既然是电信,可想而知,他们最初做视频编码,主要侧重传输。名词系列二,就是这个组织制定的标准。
流派二:ISO(International Standards Organization)的 MPEG(Moving Picture Experts Group),这个是 ISO 旗下的 MPEG,本来是做视频存储的。例如,编码后保存在 VCD 和 DVD 中。当然后来也慢慢侧重视频传输了。名词系列三,就是这个组织制定的标准。
后来,ITU-T(国际电信联盟电信标准化部门,ITU Telecommunication Standardization Sector)与 MPEG 联合制定了 H.264/MPEG-4 AVC,这才是我们这一节要重点关注的。经过编码之后,生动活泼的一帧一帧的图像,就变成了一串串让人看不懂的二进制,这个二进制可以放在一个文件里面,按照一定的格式保存起来,这就是名词系列一。其实这些就是视频保存成文件的格式。例如,前几个字节是什么意义,后几个字节是什么意义,然后是数据,数据中保存的就是编码好的结果。
如何在直播里看到帅哥美女
当然,这个二进制也可以通过某种网络协议进行封装,放在互联网上传输,这个时候就可以进行网络直播了。网络协议将编码好的视频流,从主播端推送到服务器,在服务器上有个运行了同样协议的服务端来接收这些网络包,从而得到里面的视频流,这个过程称为接流。服务端接到视频流之后,可以对视频流进行一定的处理,例如转码,也即从一个编码格式,转成另一种格式。因为观众使用的客户端千差万别,要保证他们都能看到直播。流处理完毕之后,就可以等待观众的客户端来请求这些视频流。观众的客户端请求的过程称为拉流。
如果有非常多的观众,同时看一个视频直播,那都从一个服务器上拉流,压力太大了,因而需要一个视频的分发网络,将视频预先加载到就近的边缘节点,这样大部分观众看的视频,是从边缘节点拉取的,就能降低服务器的压力。当观众的客户端将视频流拉下来之后,就需要进行解码,也即通过上述过程的逆过程,将一串串看不懂的二进制,再转变成一帧帧生动的图片,在客户端播放出来,这样你就能看到美女帅哥啦。整个直播过程,可以用这个的图来描述。

接下来,我们依次来看一下每个过程。
编码:如何将丰富多彩的图片变成二进制流
虽然我们说视频是一张张图片的序列,但是如果每张图片都完整,就太大了,因而会将视频序列分成三种帧。
I 帧,也称关键帧。里面是完整的图片,只需要本帧数据,就可以完成解码。
P 帧,前向预测编码帧。P 帧表示的是这一帧跟之前的一个关键帧(或 P 帧)的差别,解码时需要用之前缓存的画面,叠加上和本帧定义的差别,生成最终画面。
B 帧,双向预测内插编码帧。B 帧记录的是本帧与前后帧的差别。要解码 B 帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的数据与本帧数据的叠加,取得最终的画面。
可以看出,I 帧最完整,B 帧压缩率最高,而压缩后帧的序列,应该是在 IBBP 的间隔出现的。这就是通过时序进行编码。
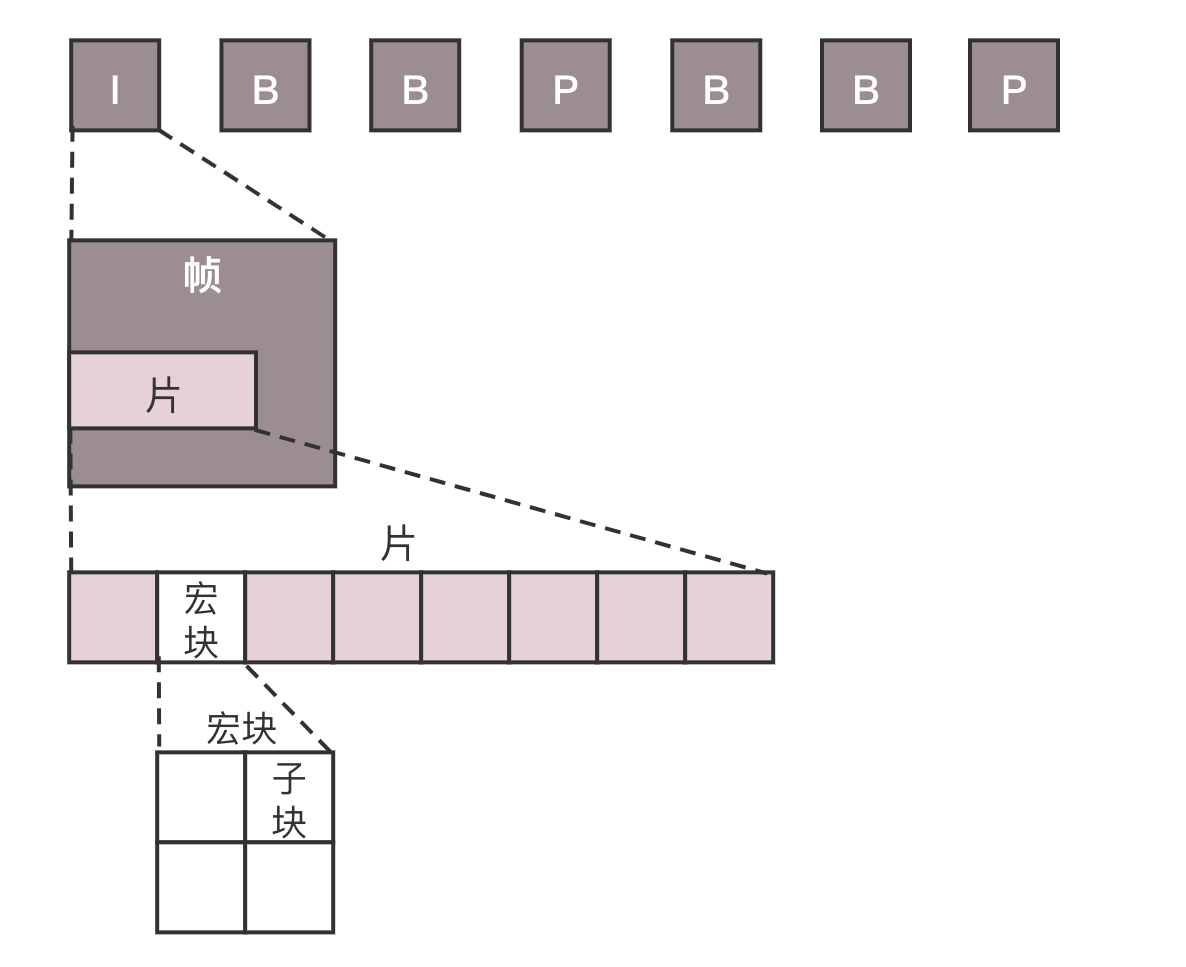
在一帧中,分成多个片,每个片中分成多个宏块,每个宏块分成多个子块,这样将一张大的图分解成一个个小块,可以方便进行空间上的编码。尽管时空非常立体地组成了一个序列,但是总归还是要压缩成一个二进制流。这个流是有结构的,是一个个的网络提取层单元(NALU,Network Abstraction Layer Unit)。变成这种格式就是为了传输,因为网络上的传输,默认的是一个个的包,因而这里也就分成了一个个的单元。
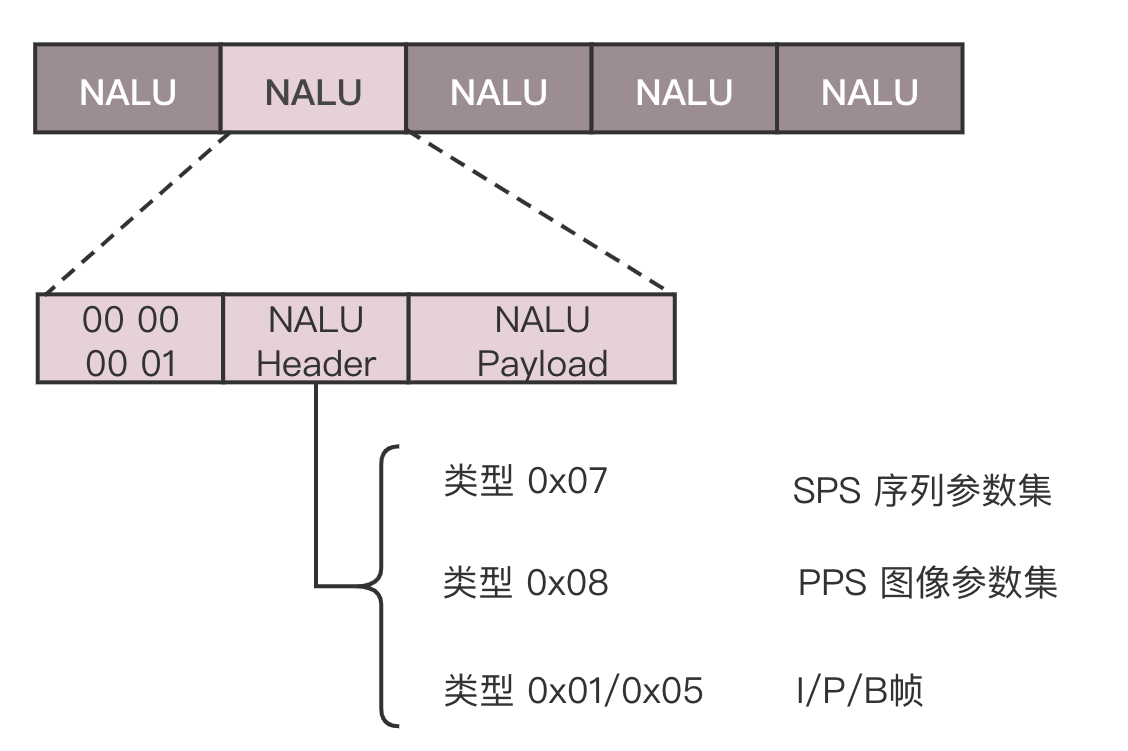
每一个 NALU 首先是一个起始标识符,用于标识 NALU 之间的间隔;然后是 NALU 的头,里面主要配置了 NALU 的类型;最终 Payload 里面是 NALU 承载的数据。在 NALU 头里面,主要的内容是类型 NAL Type。
0x07 表示 SPS,是序列参数集, 包括一个图像序列的所有信息,如图像尺寸、视频格式等。
0x08 表示 PPS,是图像参数集,包括一个图像的所有分片的所有相关信息,包括图像类型、序列号等。
在传输视频流之前,必须要传输这两类参数,不然无法解码。为了保证容错性,每一个 I 帧前面,都会传一遍这两个参数集合。如果 NALU Header 里面的表示类型是 SPS 或者 PPS,则 Payload 中就是真正的参数集的内容。如果类型是帧,则 Payload 中才是正的视频数据,当然也是一帧一帧存放的,前面说了,一帧的内容还是挺多的,因而每一个 NALU 里面保存的是一片。对于每一片,到底是 I 帧,还是 P 帧,还是 B 帧,在片结构里面也有个 Header,这里面有个类型,然后是片的内容。
这样,整个格式就出来了,一个视频,可以拆分成一系列的帧,每一帧拆分成一系列的片,每一片都放在一个 NALU 里面,NALU 之间都是通过特殊的起始标识符分隔,在每一个 I 帧的第一片前面,要插入单独保存 SPS 和 PPS 的 NALU,最终形成一个长长的 NALU 序列。
推流:如何把数据流打包传输到对端?
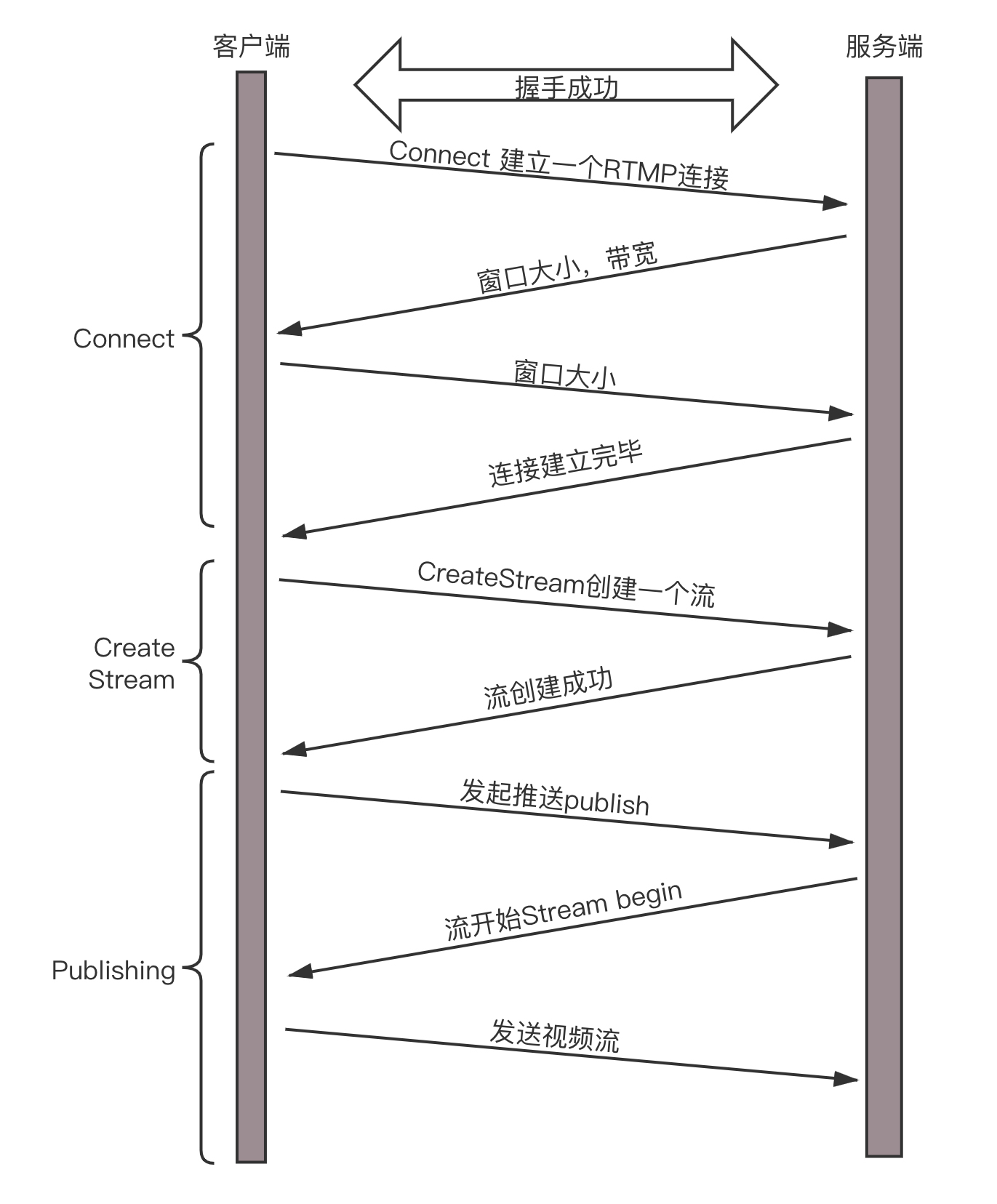
那这个格式是不是就能够直接在网上传输到对端,开始直播了呢?其实还不是,还需要将这个二进制的流打包成网络包进行发送,这里我们使用 RTMP 协议。这就进入了第二个过程,推流。RTMP 是基于 TCP 的,因而肯定需要双方建立一个 TCP 的连接。在有 TCP 的连接的基础上,还需要建立一个 RTMP 的连接,也即在程序里面,你需要调用 RTMP 类库的 Connect 函数,显示创建一个连接。RTMP 为什么需要建立一个单独的连接呢?
因为它们需要商量一些事情,保证以后的传输能正常进行。主要就是两个事情,一个是版本号,如果客户端、服务器的版本号不一致,则不能工作。另一个就是时间戳,视频播放中,时间是很重要的,后面的数据流互通的时候,经常要带上时间戳的差值,因而一开始双方就要知道对方的时间戳。未来沟通这些事情,需要发送六条消息:客户端发送 C0、C1、 C2,服务器发送 S0、 S1、 S2。首先,客户端发送 C0 表示自己的版本号,不必等对方的回复,然后发送 C1 表示自己的时间戳。服务器只有在收到 C0 的时候,才能返回 S0,表明自己的版本号,如果版本不匹配,可以断开连接。服务器发送完 S0 后,也不用等什么,就直接发送自己的时间戳 S1。客户端收到 S1 的时候,发一个知道了对方时间戳的 ACK C2。同理服务器收到 C1 的时候,发一个知道了对方时间戳的 ACK S2。于是,握手完成。

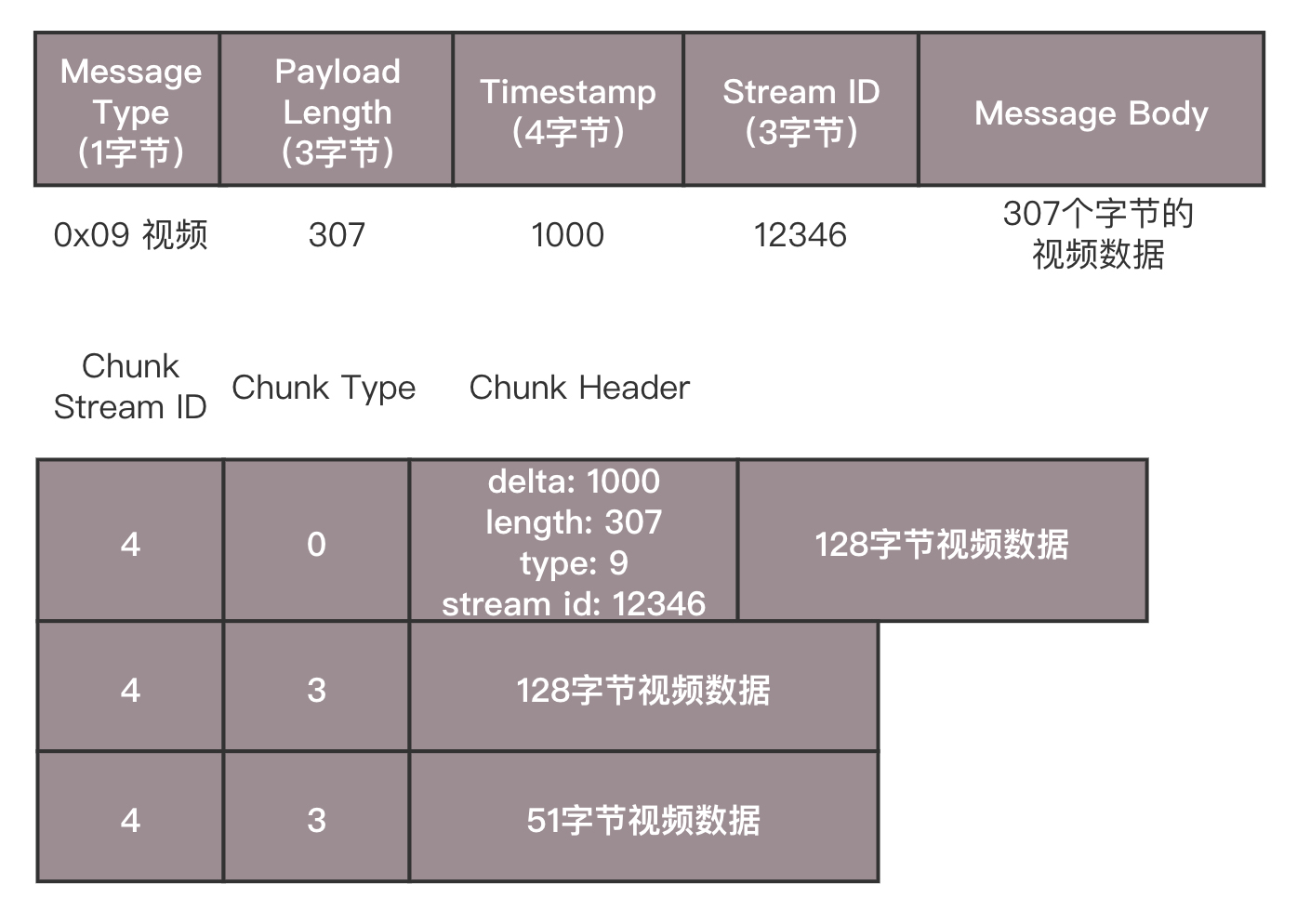
握手之后,双方需要互相传递一些控制信息,例如 Chunk 块的大小、窗口大小等。真正传输数据的时候,还是需要创建一个流 Stream,然后通过这个 Stream 来推流 publish。推流的过程,就是将 NALU 放在 Message 里面发送,这个也称为 RTMP Packet 包。Message 的格式就像这样。
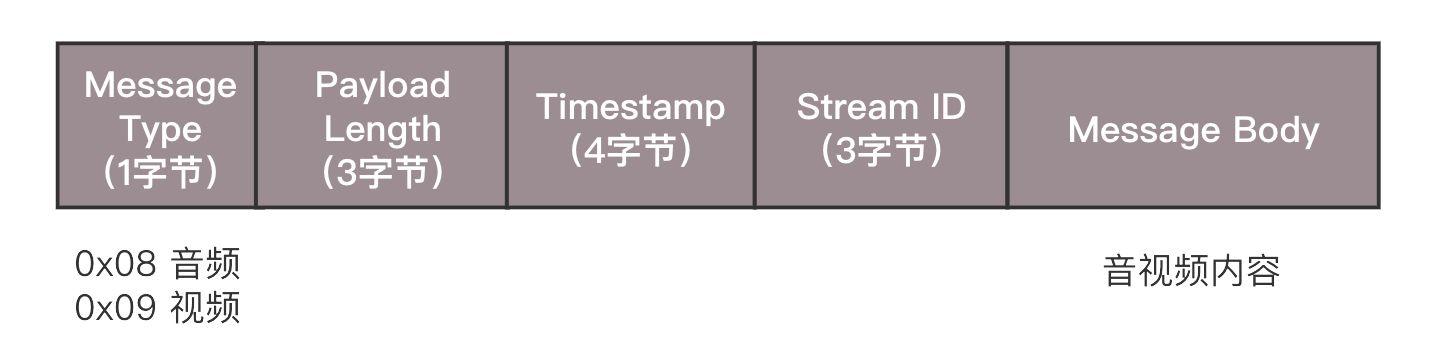
发送的时候,去掉 NALU 的起始标识符。因为这部分对于 RTMP 协议来讲没有用。接下来,将 SPS 和 PPS 参数集封装成一个 RTMP 包发送,然后发送一个个片的 NALU。RTMP 在收发数据的时候并不是以 Message 为单位的,而是把 Message 拆分成 Chunk 发送,而且必须在一个 Chunk 发送完成之后,才能开始发送下一个 Chunk。每个 Chunk 中都带有 Message ID,表示属于哪个 Message,接收端也会按照这个 ID 将 Chunk 组装成 Message。前面连接的时候,设置的 Chunk 块大小就是指这个 Chunk。将大的消息变为小的块再发送,可以在低带宽的情况下,减少网络拥塞。这有一个分块的例子,你可以看一下。
假设一个视频的消息长度为 307,但是 Chunk 大小约定为 128,于是会拆分为三个 Chunk。第一个 Chunk 的 Type=0,表示 Chunk 头是完整的;头里面 Timestamp 为 1000,总长度 Length 为 307,类型为 9,是个视频,Stream ID 为 12346,正文部分承担 128 个字节的 Data。第二个 Chunk 也要发送 128 个字节,Chunk 头由于和第一个 Chunk 一样,因此采用 Chunk Type=3,表示头一样就不再发送了。第三个 Chunk 要发送的 Data 的长度为 307-128-128=51 个字节,还是采用 Type=3。
就这样数据就源源不断到达流媒体服务器,整个过程就像这样。
这个时候,大量观看直播的观众就可以通过 RTMP 协议从流媒体服务器上拉取,但是这么多的用户量,都去同一个地方拉取,服务器压力会很大,而且用户分布在全国甚至全球,如果都去统一的一个地方下载,也会时延比较长,需要有分发网络。分发网络分为中心和边缘两层。边缘层服务器部署在全国各地及横跨各大运营商里,和用户距离很近。中心层是流媒体服务集群,负责内容的转发。智能负载均衡系统,根据用户的地理位置信息,就近选择边缘服务器,为用户提供推 / 拉流服务。中心层也负责转码服务,例如,把 RTMP 协议的码流转换为 HLS 码流。

这套机制在后面的 DNS、HTTPDNS、CDN 的章节会更有详细的描述。
拉流:观众的客户端如何看到视频?
接下来,我们再来看观众的客户端通过 RTMP 拉流的过程。
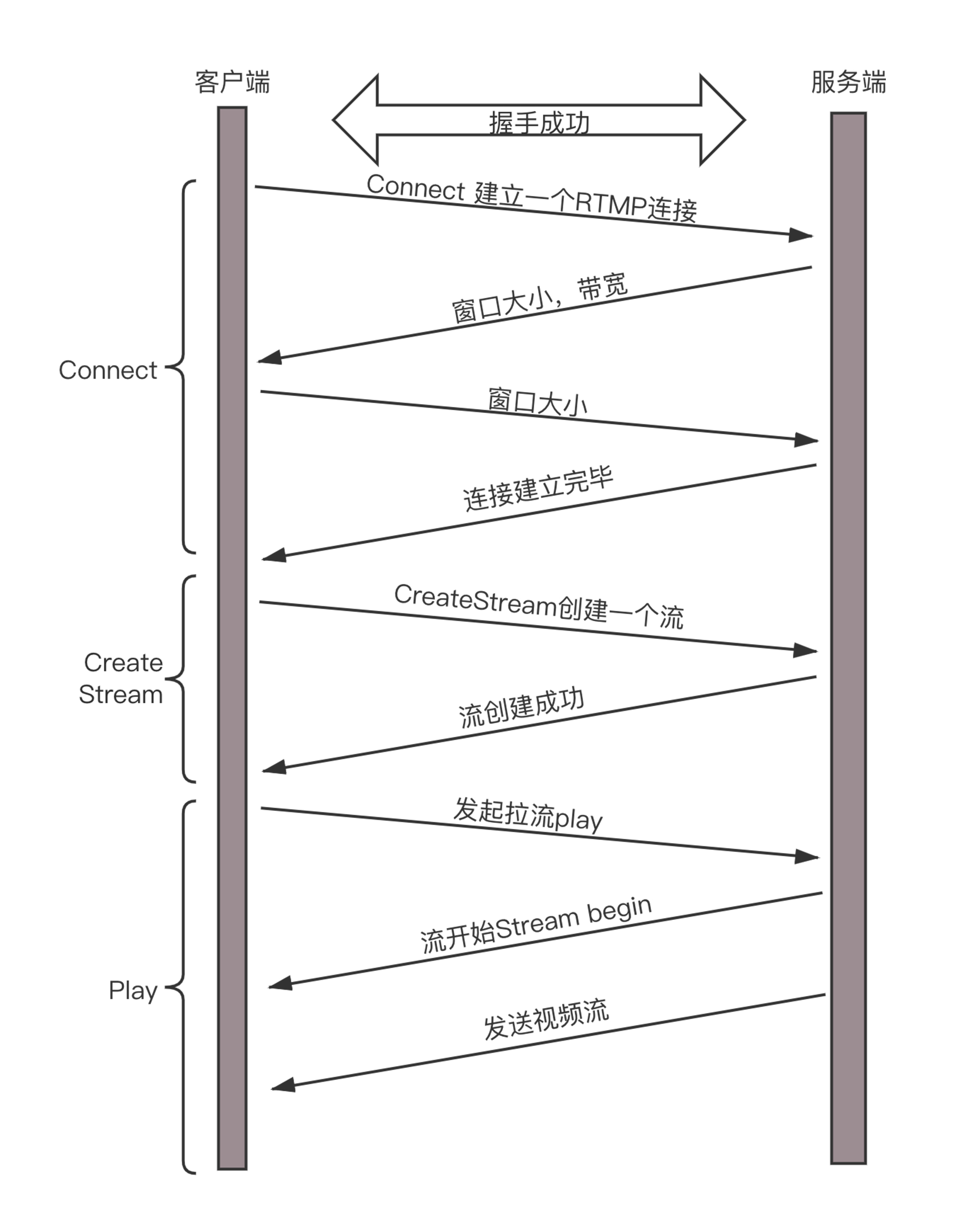
先读到的是 H.264 的解码参数,例如 SPS 和 PPS,然后对收到的 NALU 组成的一个个帧,进行解码,交给播发器播放,一个绚丽多彩的视频画面就出来了。
小结
视频名词比较多,编码两大流派达成了一致,都是通过时间、空间的各种算法来压缩数据;压缩好的数据,为了传输组成一系列 NALU,按照帧和片依次排列;排列好的 NALU,在网络传输的时候,要按照 RTMP 包的格式进行包装,RTMP 的包会拆分成 Chunk 进行传输;推送到流媒体集群的视频流经过转码和分发,可以被客户端通过 RTMP 协议拉取,然后组合为 NALU,解码成视频格式进行播放。
P2P协议:我下小电影,99%急死你
如果你想下载一个电影,一般会通过什么方式呢?当然,最简单的方式就是通过 HTTP 进行下载。但是相信你有过这样的体验,通过浏览器下载的时候,只要文件稍微大点,下载的速度就奇慢无比。还有种下载文件的方式,就是通过 FTP,也即文件传输协议。FTP 采用两个 TCP 连接来传输一个文件。
控制连接:服务器以被动的方式,打开众所周知用于 FTP 的端口 21,客户端则主动发起连接。该连接将命令从客户端传给服务器,并传回服务器的应答。常用的命令有:list——获取文件目录;reter——取一个文件;store——存一个文件。
数据连接:每当一个文件在客户端与服务器之间传输时,就创建一个数据连接。
FTP 的两种工作模式
每传输一个文件,都要建立一个全新的数据连接。FTP 有两种工作模式,分别是主动模式(PORT)和被动模式(PASV),这些都是站在 FTP 服务器的角度来说的。主动模式下,客户端随机打开一个大于 1024 的端口 N,向服务器的命令端口 21 发起连接,同时开放 N+1 端口监听,并向服务器发出 “port N+1” 命令,由服务器从自己的数据端口 20,主动连接到客户端指定的数据端口 N+1。被动模式下,当开启一个 FTP 连接时,客户端打开两个任意的本地端口 N(大于 1024)和 N+1。第一个端口连接服务器的 21 端口,提交 PASV 命令。然后,服务器会开启一个任意的端口 P(大于 1024),返回“227 entering passive mode”消息,里面有 FTP 服务器开放的用来进行数据传输的端口。客户端收到消息取得端口号之后,会通过 N+1 号端口连接服务器的端口 P,然后在两个端口之间进行数据传输。
P2P 是什么?
但是无论是 HTTP 的方式,还是 FTP 的方式,都有一个比较大的缺点,就是难以解决单一服务器的带宽压力, 因为它们使用的都是传统的客户端服务器的方式。后来,一种创新的、称为 P2P 的方式流行起来。P2P 就是 peer-to-peer。资源开始并不集中地存储在某些设备上,而是分散地存储在多台设备上。这些设备我们姑且称为 peer。想要下载一个文件的时候,你只要得到那些已经存在了文件的 peer,并和这些 peer 之间,建立点对点的连接,而不需要到中心服务器上,就可以就近下载文件。一旦下载了文件,你也就成为 peer 中的一员,你旁边的那些机器,也可能会选择从你这里下载文件,所以当你使用 P2P 软件的时候,例如 BitTorrent,往往能够看到,既有下载流量,也有上传的流量,也即你自己也加入了这个 P2P 的网络,自己从别人那里下载,同时也提供给其他人下载。可以想象,这种方式,参与的人越多,下载速度越快,一切完美。
种子(.torrent)文件
但是有一个问题,当你想下载一个文件的时候,怎么知道哪些 peer 有这个文件呢?这就用到种子啦,也即咱们比较熟悉的.torrent 文件。.torrent 文件由两部分组成,分别是:announce(tracker URL)和文件信息。文件信息里面有这些内容。
info 区:这里指定的是该种子有几个文件、文件有多长、目录结构,以及目录和文件的名字。Name 字段:指定顶层目录名字。每个段的大小:BitTorrent(简称 BT)协议把一个文件分成很多个小段,然后分段下载。段哈希值:将整个种子中,每个段的 SHA-1 哈希值拼在一起。
下载时,BT 客户端首先解析.torrent 文件,得到 tracker 地址,然后连接 tracker 服务器。tracker 服务器回应下载者的请求,将其他下载者(包括发布者)的 IP 提供给下载者。下载者再连接其他下载者,根据.torrent 文件,两者分别对方告知自己已经有的块,然后交换对方没有的数据。此时不需要其他服务器参与,并分散了单个线路上的数据流量,因此减轻了服务器的负担。下载者每得到一个块,需要算出下载块的 Hash 验证码,并与.torrent 文件中的对比。如果一样,则说明块正确,不一样则需要重新下载这个块。这种规定是为了解决下载内容的准确性问题。从这个过程也可以看出,这种方式特别依赖 tracker。tracker 需要收集下载者信息的服务器,并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。虽然下载的过程是非中心化的,但是加入这个 P2P 网络的时候,都需要借助 tracker 中心服务器,这个服务器是用来登记有哪些用户在请求哪些资源。所以,这种工作方式有一个弊端,一旦 tracker 服务器出现故障或者线路遭到屏蔽,BT 工具就无法正常工作了。
去中心化网络(DHT)
那能不能彻底非中心化呢?于是,后来就有了一种叫作 DHT(Distributed Hash Table)的去中心化网络。每个加入这个 DHT 网络的人,都要负责存储这个网络里的资源信息和其他成员的联系信息,相当于所有人一起构成了一个庞大的分布式存储数据库。有一种著名的 DHT 协议,叫 Kademlia 协议。这个和区块链的概念一样,很抽象,我来详细讲一下这个协议。任何一个 BitTorrent 启动之后,它都有两个角色。一个是 peer,监听一个 TCP 端口,用来上传和下载文件,这个角色表明,我这里有某个文件。另一个角色 DHT node,监听一个 UDP 的端口,通过这个角色,这个节点加入了一个 DHT 的网络。
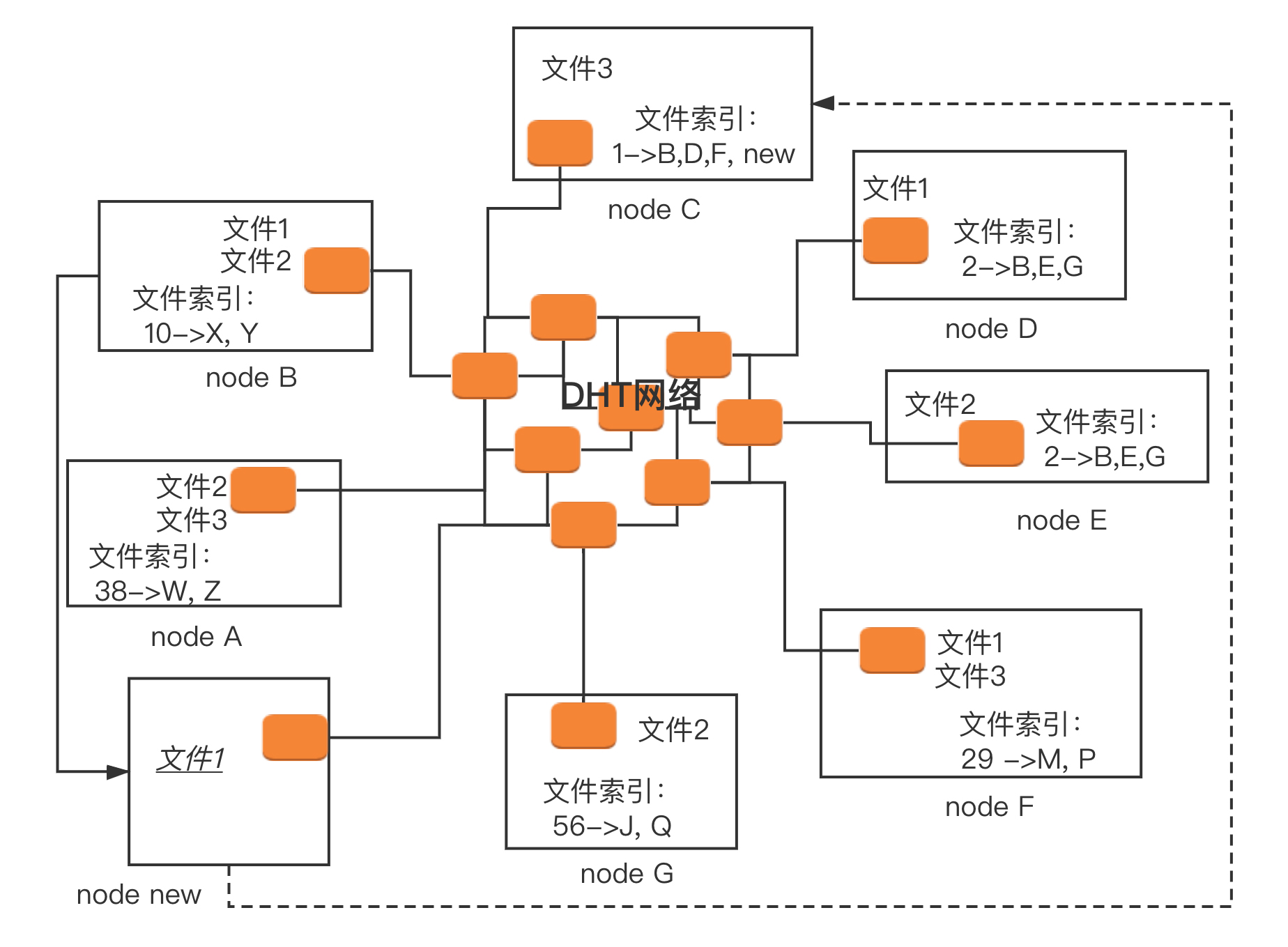
在 DHT 网络里面,每一个 DHT node 都有一个 ID。这个 ID 是一个很长的串。每个 DHT node 都有责任掌握一些知识,也就是文件索引,也即它应该知道某些文件是保存在哪些节点上。它只需要有这些知识就可以了,而它自己本身不一定就是保存这个文件的节点。
哈希值
当然,每个 DHT node 不会有全局的知识,也即不知道所有的文件保存在哪里,它只需要知道一部分。那应该知道哪一部分呢?这就需要用哈希算法计算出来。每个文件可以计算出一个哈希值,而 DHT node 的 ID 是和哈希值相同长度的串。DHT 算法是这样规定的:如果一个文件计算出一个哈希值,则和这个哈希值一样的那个 DHT node,就有责任知道从哪里下载这个文件,即便它自己没保存这个文件。当然不一定这么巧,总能找到和哈希值一模一样的,有可能一模一样的 DHT node 也下线了,所以 DHT 算法还规定:除了一模一样的那个 DHT node 应该知道,ID 和这个哈希值非常接近的 N 个 DHT node 也应该知道。
什么叫和哈希值接近呢?例如只修改了最后一位,就很接近;修改了倒数 2 位,也不远;修改了倒数 3 位,也可以接受。总之,凑齐了规定的 N 这个数就行。刚才那个图里,文件 1 通过哈希运算,得到匹配 ID 的 DHT node 为 node C,当然还会有其他的,我这里没有画出来。所以,node C 有责任知道文件 1 的存放地址,虽然 node C 本身没有存放文件 1。同理,文件 2 通过哈希运算,得到匹配 ID 的 DHT node 为 node E,但是 node D 和 E 的 ID 值很近,所以 node D 也知道。当然,文件 2 本身没有必要一定在 node D 和 E 里,但是碰巧这里就在 E 那有一份。接下来一个新的节点 node new 上线了。如果想下载文件 1,它首先要加入 DHT 网络,如何加入呢?
在这种模式下,种子.torrent 文件里面就不再是 tracker 的地址了,而是一个 list 的 node 的地址,而所有这些 node 都是已经在 DHT 网络里面的。当然随着时间的推移,很可能有退出的,有下线的,但是我们假设,不会所有的都联系不上,总有一个能联系上。node new 只要在种子里面找到一个 DHT node,就加入了网络。node new 会计算文件 1 的哈希值,并根据这个哈希值了解到,和这个哈希值匹配,或者很接近的 node 上知道如何下载这个文件,例如计算出来的哈希值就是 node C。但是 node new 不知道怎么联系上 node C,因为种子里面的 node 列表里面很可能没有 node C,但是它可以问,DHT 网络特别像一个社交网络,node new 只有去它能联系上的 node 问,你们知道不知道 node C 的联系方式呀?在 DHT 网络中,每个 node 都保存了一定的联系方式,但是肯定没有 node 的所有联系方式。DHT 网络中,节点之间通过互相通信,也会交流联系方式,也会删除联系方式。和人们的方式一样,你有你的朋友圈,你的朋友有它的朋友圈,你们互相加微信,就互相认识了,过一段时间不联系,就删除朋友关系。
有个理论是,社交网络中,任何两个人直接的距离不超过六度,也即你想联系比尔盖茨,也就六个人就能够联系到了。所以,node new 想联系 node C,就去万能的朋友圈去问,并且求转发,朋友再问朋友,很快就能找到。如果找不到 C,也能找到和 C 的 ID 很像的节点,它们也知道如何下载文件 1。在 node C 上,告诉 node new,下载文件 1,要去 B、D、 F,于是 node new 选择和 node B 进行 peer 连接,开始下载,它一旦开始下载,自己本地也有文件 1 了,于是 node new 告诉 node C 以及和 node C 的 ID 很像的那些节点,我也有文件 1 了,可以加入那个文件拥有者列表了。但是你会发现 node new 上没有文件索引,但是根据哈希算法,一定会有某些文件的哈希值是和 node new 的 ID 匹配上的。在 DHT 网络中,会有节点告诉它,你既然加入了咱们这个网络,你也有责任知道某些文件的下载地址。好了,一切都分布式了。这里面遗留几个细节的问题。
DHT node ID 以及文件哈希是个什么东西?
节点 ID 是一个随机选择的 160bits(20 字节)空间,文件的哈希也使用这样的 160bits 空间。
所谓 ID 相似,具体到什么程度算相似?
在 Kademlia 网络中,距离是通过异或(XOR)计算的。我们就不以 160bits 举例了。我们以 5 位来举例。
01010 与 01000 的距离,就是两个 ID 之间的异或值,为 00010,也即为 2。 01010 与 00010 的距离为 01000,也即为 8,。01010 与 00011 的距离为 01001,也即 8+1=9 。以此类推,高位不同的,表示距离更远一些;低位不同的,表示距离更近一些,总的距离为所有的不同的位的距离之和。这个距离不能比喻为地理位置,因为在 Kademlia 网络中,位置近不算近,ID 近才算近,所以我把这个距离比喻为社交距离,也即在朋友圈中的距离,或者社交网络中的距离。这个和你住的位置没有关系,和人的经历关系比较大。还是以 5 位 ID 来举例,就像在领英中,排第一位的表示最近一份工作在哪里,第二位的表示上一份工作在哪里,然后第三位的是上上份工作,第四位的是研究生在哪里读,第五位的表示大学在哪里读。如果你是一个猎头,在上面找候选人,当然最近的那份工作是最重要的。而对于工作经历越丰富的候选人,大学在哪里读的反而越不重要。
DHT 网络中的朋友圈是怎么维护的?
就像人一样,虽然我们常联系人的只有少数,但是朋友圈里肯定是远近都有。DHT 网络的朋友圈也是一样,远近都有,并且按距离分层。假设某个节点的 ID 为 01010,如果一个节点的 ID,前面所有位数都与它相同,只有最后 1 位不同。这样的节点只有 1 个,为 01011。与基础节点的异或值为 00001,即距离为 1;对于 01010 而言,这样的节点归为“k-bucket 1”。如果一个节点的 ID,前面所有位数都相同,从倒数第 2 位开始不同,这样的节点只有 2 个,即 01000 和 01001,与基础节点的异或值为 00010 和 00011,即距离范围为 2 和 3;对于 01010 而言,这样的节点归为“k-bucket 2”。如果一个节点的 ID,前面所有位数相同,从倒数第 i 位开始不同,这样的节点只有 2^(i-1) 个,与基础节点的距离范围为[2^(i-1), 2^i);对于 01010 而言,这样的节点归为“k-bucket i”。最终到从倒数 160 位就开始都不同。你会发现,差距越大,陌生人越多,但是朋友圈不能都放下,所以每一层都只放 K 个,这是参数可以配置。
DHT 网络是如何查找朋友的?
假设,node A 的 ID 为 00110,要找 node B ID 为 10000,异或距离为 10110,距离范围在[2^4, 2^5),所以这个目标节点可能在“k-bucket 5”中,这就说明 B 的 ID 与 A 的 ID 从第 5 位开始不同,所以 B 可能在“k-bucket 5”中。然后,A 看看自己的 k-bucket 5 有没有 B。如果有,太好了,找到你了;如果没有,在 k-bucket 5 里随便找一个 C。因为是二进制,C、B 都和 A 的第 5 位不同,那么 C 的 ID 第 5 位肯定与 B 相同,即它与 B 的距离会小于 2^4,相当于比 A、B 之间的距离缩短了一半以上。再请求 C,在它自己的通讯录里,按同样的查找方式找一下 B。如果 C 知道 B,就告诉 A;如果 C 也不知道 B,那 C 按同样的搜索方法,可以在自己的通讯录里找到一个离 B 更近的 D 朋友(D、B 之间距离小于 2^3),把 D 推荐给 A,A 请求 D 进行下一步查找。Kademlia 的这种查询机制,是通过折半查找的方式来收缩范围,对于总的节点数目为 N,最多只需要查询 log2(N) 次,就能够找到。例如,图中这个最差的情况。
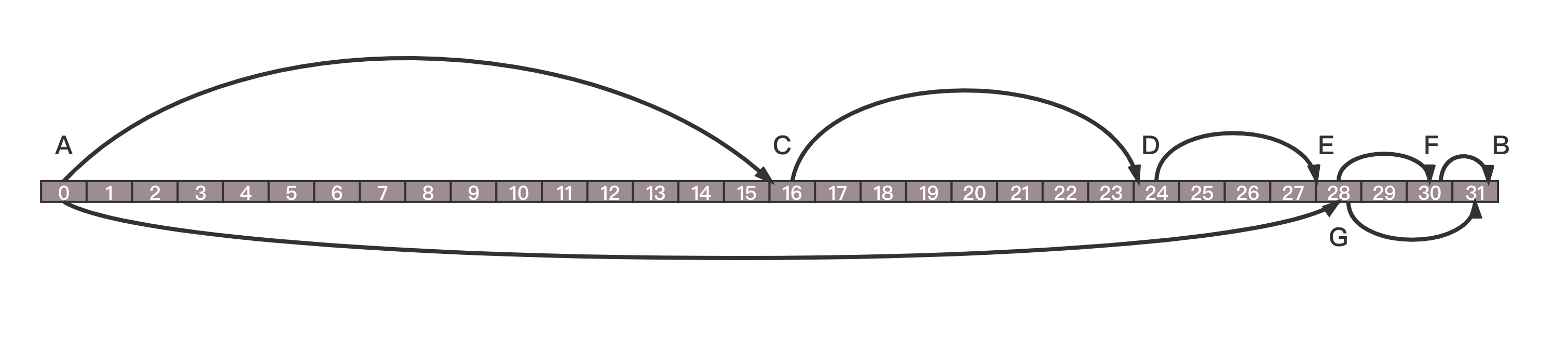
A 和 B 每一位都不一样,所以相差 31,A 找到的朋友 C,不巧正好在中间。和 A 的距离是 16,和 B 距离为 15,于是 C 去自己朋友圈找的时候,不巧找到 D,正好又在中间,距离 C 为 8,距离 B 为 7。于是 D 去自己朋友圈找的时候,不巧找到 E,正好又在中间,距离 D 为 4,距离 B 为 3,E 在朋友圈找到 F,距离 E 为 2,距离 B 为 1,最终在 F 的朋友圈距离 1 的地方找到 B。当然这是最最不巧的情况,每次找到的朋友都不远不近,正好在中间。如果碰巧了,在 A 的朋友圈里面有 G,距离 B 只有 3,然后在 G 的朋友圈里面一下子就找到了 B,两次就找到了。在 DHT 网络中,朋友之间怎么沟通呢?Kademlia 算法中,每个节点只有 4 个指令。
PING:测试一个节点是否在线,还活着没,相当于打个电话,看还能打通不。
STORE:要求一个节点存储一份数据,既然加入了组织,有义务保存一份数据。
FIND_NODE:根据节点 ID 查找一个节点,就是给一个 160 位的 ID,通过上面朋友圈的方式找到那个节点。
FIND_VALUE:根据 KEY 查找一个数据,实则上跟 FIND_NODE 非常类似。KEY 就是文件对应的 160 位的 ID,就是要找到保存了文件的节点。
DHT 网络中,朋友圈如何更新呢?
每个 bucket 里的节点,都按最后一次接触的时间倒序排列,这就相当于,朋友圈里面最近联系过的人往往是最熟的。每次执行四个指令中的任意一个都会触发更新。当一个节点与自己接触时,检查它是否已经在 k-bucket 中,也就是说是否已经在朋友圈。如果在,那么将它挪到 k-bucket 列表的最底,也就是最新的位置,刚联系过,就置顶一下,方便以后多联系;如果不在,新的联系人要不要加到通讯录里面呢?假设通讯录已满的情况,PING 一下列表最上面,也即最旧的一个节点。如果 PING 通了,将旧节点挪到列表最底,并丢弃新节点,老朋友还是留一下;如果 PING 不通,删除旧节点,并将新节点加入列表,这人联系不上了,删了吧。这个机制保证了任意节点加入和离开都不影响整体网络。
下载一个文件可以使用 HTTP 或 FTP,这两种都是集中下载的方式,而 P2P 则换了一种思路,采取非中心化下载的方式;P2P 也是有两种,一种是依赖于 tracker 的,也即元数据集中,文件数据分散;另一种是基于分布式的哈希算法,元数据和文件数据全部分散。
总结
以后关于数据中台系列的总结大部分来自Geek Time的课件,大家可以自行关键字搜索。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号