
VSCode在集群服务器上使用Jupyter Notebook
背景
最近出来实习,公司这里提供了一个16节点*8GPU的集群服务器可以用于跑实验,节点之间可互相通过ssh访问。然而由于节点资源紧张,序号靠前的节点基本上都被占满了,后面几个节点还有空余。我习惯使用Jupyter进行一些简单的预实验,同时也习惯于通过VSCode使用Jupyter,因为VSCode可以提供代码高亮和代码补全功能。
直接在VSCode中创建一个.ipynb文件,打开后选择一个Python环境作为内核源是一个我常用的方式。这种方式VSCode会自动创建一个Jupyter Server,之后的代码都会在这个VSCode创建的Server上运行。但对于一个多节点服务器的情况,VSCode创建的Jupyter Server只会部署在第一个节点上,无法直接选择让VSCode在其他节点上创建Server,这样就导致无法灵活使用其他节点上的空闲GPU。
方法思路
通过查找网络上的经验帖(知乎),以及阅读VSCode官方文档(Manage Jupyter Kernels in VS Code),整体解决思路如下:
- 在目标节点上启动一个Jupyter Server
- 通过ssh端口映射将目标节点上的Jupyter Server所监听的端口映射到第一个节点上
- 在VSCode中创建一个新的.ipynb文件
- 将这个.ipynb文件连接到Jupyter Server地址
具体操作
安装ipykernel以及jupyter
pip install ipykernel
pip install jupyter
(可选)将一个虚拟环境导入Jupyter kernel
如果使用了像Anaconda这种虚拟环境,可以先将环境导入Jupyter的kernel中:
# 导入虚拟环境(这里以conda为例,假设环境名为some_env)
python -m ipykernel install --user --name some_env --display-name "some_env"
其中--name后为虚拟环境名,--display-name后为进入Jupyter Server后看到的kernel名。
在目标节点上启动一个Jupyter Server
假设目标节点为node-i,通过ssh进入该节点后创建一个screen用于运行Jupyter Server:
# 进入节点node-i
ssh node-i
# (可选)如果是使用了conda环境,可以进入这个conda环境
conda activate <env-name>
# 创建并进入一个screen
screen -S jupyter
# 在这个screen里面启动一个Jupyter Server,监听端口8888
jupyter notebook --no-browser --port 8888
这里的--no-browser表示不自动在默认浏览器中打开页面。通过这个方法可以将一个Jupyter Server运行在后台,并且不会受到ssh连接被关闭的影响。查看控制台里的输出,并记录下这两个URL:
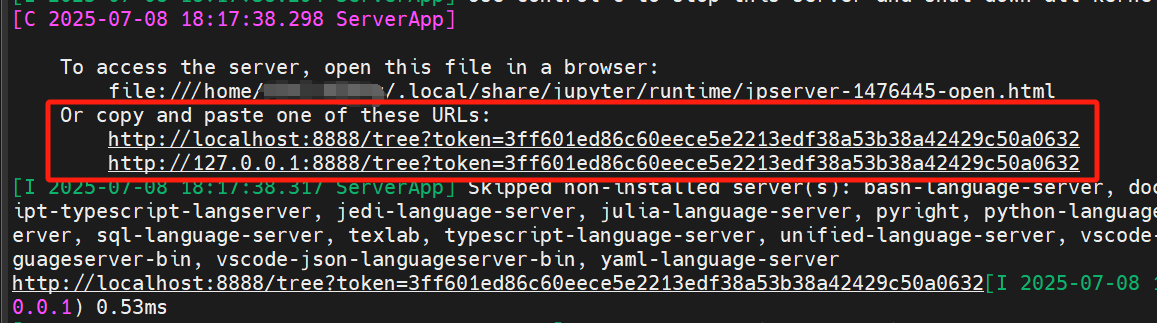
然后按下Ctrl+A+D退出与这个screen的连接,并输入exit关闭这个ssh连接。
通过ssh进行端口转发
将目标节点的8888端口转发到第一个节点的端口上(这里设置为同一个端口):
ssh -L 8888:localhost:8888 node-i
这里的ssh -L进行一个ssh连接,并且对端口进行转发,<target-port>:localhost:<local-port>表示将目标服务器的<target-port>端口转发到当前服务器的<local-port>端口。这里的<target-port>设置为8888是因为Jupyter Server根据启动时设置是监听在localhost:8888端口上。如果启动Jupyter Server的时候将其设置监听到其他端口,那么在这里进行端口转发的时候<target-port>需要设置为对应的端口。至此Jupyter Server的创建以及端口转发就完成了。
VSCode中的操作
创建一个新的.ipynb文件:

点击右上角“选择内核”,然后点击“选择其他内核”:

选择“现有Jupyter服务器”:

在弹出的输入框中输入刚才记录下的两个URL中的任意一个:

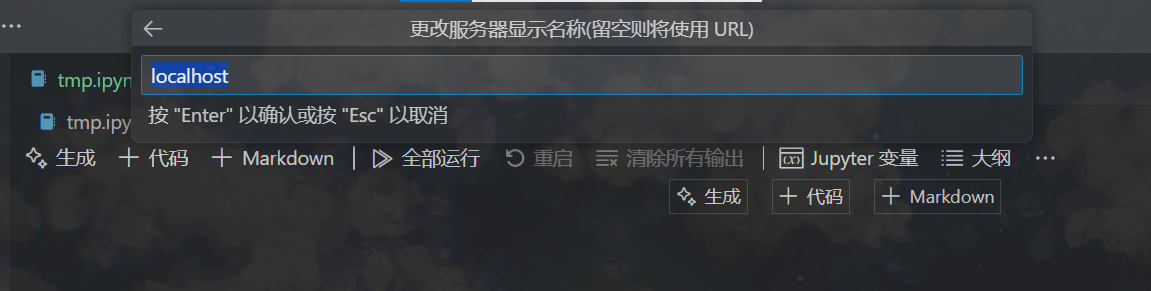
按下回车,然后可以选择在弹出的输入框中输入这个服务器的名称(我这里默认是localhost,可以不用改):
再按回车,会弹出一个从服务器中选择内核。如果刚才在kernel导入了自己的虚拟环境,那么此时这里会显示出刚才导入的虚拟环境的名字(例如我这里是dinov2):
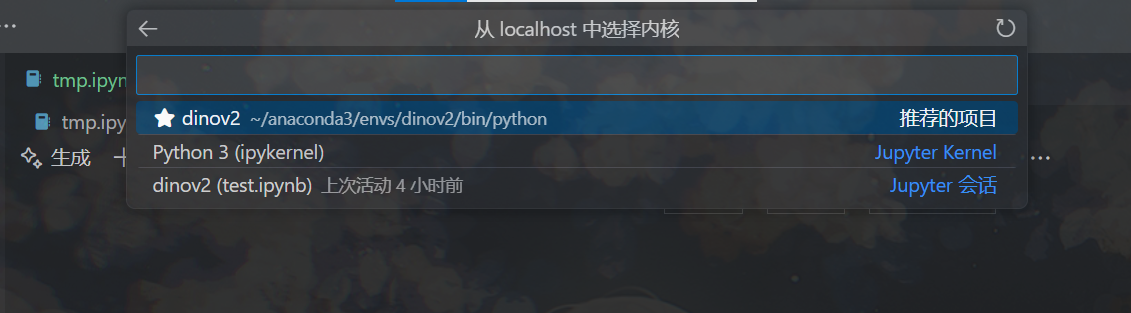
点击选择需要的内核,就完成了VSCode中的设置。
测试效果
目前这个.ipynb文件已经连上了目标节点上的Jupyter Server,那么此时在上面调用的GPU就应该是目标节点上的GPU。这里我写了两行代码测试一下使用的GPU是否是目标节点上的GPU:
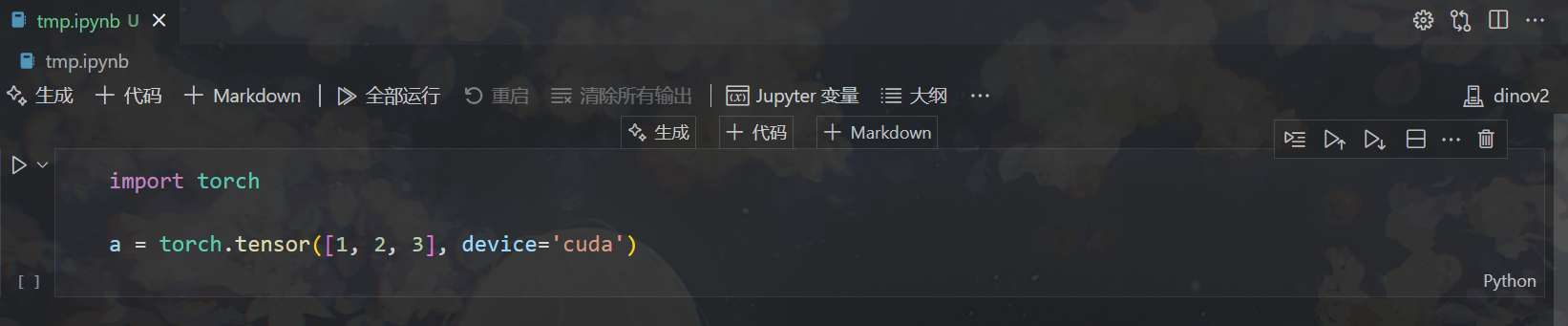
运行后在目标节点(我这里是gpu-node16)上查看GPU使用情况,可以看到当前运行的Jupyter程序:

后记
每个.ipynb的运行路径并不一定等于它文件所在的位置,而是取决于Jupyter服务器的启动位置。假设在~/路径下启动了一个Jupyter服务器,那么在连接到这个服务器的.ipynb中运行的默认路径就是~/。而有的时候需要对应路径下的package依赖,因此使用这种方法需要在.ipynb的开头添加一段魔法指令将路径调整到.ipynb所在的文件夹:

本文来自博客园,作者:蓝莓夹心奥利奥,转载请注明原文链接:https://www.cnblogs.com/blueberryoreo/p/18973527

 浙公网安备 33010602011771号
浙公网安备 33010602011771号