



爬虫学习笔记
爬虫学习
爬虫之前假期学了一部分,这个假期捡一捡,把它学完。B站视频
1.Request使用
这些库的安装挺简单,不写了
1.1get用法
import requests
url = "xxx.com"
resp = requests.get(url) #还有可选参数headers
print(resp.text) #获取页面源码
#headers是一个字典,有多个参数,例如"User-Agent","Cookie","Host","params"等
example
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36","Cookie": "token = eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6MTUyMzA0MSwiaWF0IjoxNjQ5MjQ5NjQ3LCJleHAiOjE2NTE4NDE2NDd9.5p2tK8zBflOq0SERGGIHY7DUtAy0ZOgthbGzJRsHjactoken.sig = lOiWSY5yON7F13XTdKmSOsqZjTMU_OBmwPKi_IUUGPw","Host": "www.yousuu.com"
}
params = {
"page" : "1"
}
resp.close() #关掉resp
1.2post用法
import requests
url = "xxx.com"
resp = requests.post(url,data = dat) #dat是要传入的数据,dat也是字典
print(resp.text)
post用法与get用法可从浏览器的抓包工具看到。
2.数据解析概述
常用的解析方式有:
- re解析
- bf4解析
- xpath解析
re干别的也好用,所以会复习一下。xpath解析简单方便,会详细写一下。bf4感觉没啥优点,不复习了。
2.1re正则表达式
形式语言讲过,软件构造也提过,这玩意真挺好用。
正则表达式语法就不写了,菜鸟教程讲的贼好。
直接就从python正则表达式的使用开始。
2.1.1python正则表达式的使用
string表示字符串
import re
obj = re.compile(r"xxx",re.S) #xxx式正则表达式,re.S表示略过空白符
it = obj.finditer(string) #返回迭代器,能得到所有匹配的字符串
obj.findall(string) #返回一个list,效率低
obj.search(string) #匹配到了就返回,结果的使用方法:i.group()
obj.match(string) #使用方法与search差不多,但是它必须从头开始匹配,如果第一个字符就不同,那么匹配失败。
#finditer使用方法
for i in it:
print(i.group())
2.1.2补充
".*?"很常用,它能匹配除空白字符串外的所有字符。
不过我还学了"[\s\S]"也能匹配所有字符,貌似更好用。
单独获取正则表达式匹配的字符串的内容,可以分组。
obj = re.compile(r"xxx(?p<name>xxx)",re.S)
print(i.get("name"))
2.2xpath解析
xpath感觉与html内容相关,正好这个暑假会稍微学学。
2.2.1xpath规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| . . | 选取当前节点的父节点 |
| @ | 选取属性 |
2.2.2etree的导入
这个etree贼坑,新版本好像没法from lxml import etree这么用。我之前学的时候在网上找了半天,也没找到好的办法只能自己换个方式导入使用。
from lxml import html
tree = html.etree
ans = tree.HTML(string)
print(ans.xpath("xxx/text()")) #xxx是xpath路径,可以从浏览器检查,复制xpath路径获得。
2.2.3xpath的使用
ans.xpath("xxx/*/a[@href='xxx']/text()") #"/"表示层级关系,text()拿取文本content,"*"表示任意节点,是通配符。"[@href='xxx']"这种方式指定某个标签的某个属性。
ans.xpath("xxx/*/a/@href) #/@href可以获取标签属性,比如url
路径要用"//"才能选取所有节点,否则只有当前节点。当自己写xpath路径时会出现['\r\n',"\n"]之类的结果,而没有想要的正文。"//*"能匹配所有节点。
3.Request深入
3.1session
为了处理cookie的问题,这是一个持续的请求,它会保存服务器发过来的cookie,这样能保证登录后,可以继续操作。等同于自己传入cookie。
session = requests.session()
resp = session.post("xxxx",data = dat) #dat里有账号密码,相当于登录成功,保存有cookie
print(resp.text)
3.2防盗链
就是referer参数,即这个页面的上个页面的url,一般可从抓包工具获得。这个参数也放到headers中。
终于复习完了,明天学新的。
4.多线程
进程与线程的概念详见csapp。
4.1if __name__ == "__main__":用法理解
学的时候看到if __name__ == "__main__":的用法,之前不太理解,顺便学一下。参考
作为解释性脚本语言,python程序并没有特定的main()主程序入口,一般就是自顶向下,逐行执行,一般python可以理解__name__ == "__main__"为程序的执行入口。
注:我才发现pycharm可以输入main,补全代码。
4.1.1__name__的理解
__name__方法是python中的一个内置函数,记录的值就是一个字符串。如果是在当前文件中执行,记录的值就是__main__。
情景一
执行代码:test.py
print("程序测试")
print(__name__)
结果:
程序测试
__main__ #说明是本文件执行
Process finished with exit code 0
情景二
执行代码:test2.py
import test #是的,只有一个导包代码
结果:
程序测试
test
Process finished with exit code 0
我之前是真不知道python这个特性,单独导个包,就会执行这个包中的程序。这样一看if __name__ == "__main__":的作用就很好理解了,不让被导入包中的程序运行。好吧,我又理解错了,它的意思是——在这个语句下的程序,只会在本程序中使用,而当其被别的程序引用时,此语句下的程序不执行。(也就是说这个语句是用在被引用的程序之中,而不是正在执行的程序当中)
4.1.2if __name__ == "__main__":的用法
情景三
我们对情景一(test.py)的代码进行很小的改动。真的很小,就加一行代码
if __name__ == "__main__":
print("程序测试")
print(__name__)
结果跟情景一结果是一样的,不变。
情景四
还是执行情景二一样的代码。
结果:
Process finished with exit code 0
对,没结果。两个print函数压根没执行,这就是if __name__ == "__main__":写法的用处。
情景五
对test.py再次进行修改。
a = 1
if __name__ == "__main__":
print("程序测试")
print(__name__)
b = 2
对于test2.py我们也要进行一定的修改
import test
print(test.a)
print(test.b)
结果:
1
Traceback (most recent call last):
File "F:\Python_Projects\多线程\test2.py", line 3, in <module>
print(test.b)
AttributeError: module 'test' has no attribute 'b'
Process finished with exit code 1
这里我们能看到a = 1的值是可以正常得到的,而b = 2的值是拿不到的。emmmm,我怎么感觉有点像c中的static或者说java中的private
4.2python中多线程的使用
我现在好像理解为什么爬虫视频中,老师要用这个语句了,为了防止程序被调用时产生多余的线程。
4.2.1使用方法一
from threading import Thread
def test():
for i in range(100):
print("thread", i)
if __name__ == "__main__":
t = Thread(target=test) #这块简直坑,一定时test而不是test(),千万别加括号,加了就成函数调用了。
t.start()
for i in range(100):
print("main", i)
结果
threadmain 0
thread 0
main 11
main 2
main 3
main 4
就列一部分了,多的就不列了,反正就是并发执行了。csapp有学,其实跟c语言的并发编程有点相似。
4.2.2使用方法二
from threading import Thread
class MyThread(Thread): #python的面向对象编程,有时间我可以学一学
def run(self): #重写run()方法
for i in range(100):
print("threadTwo", i)
if __name__ == "__main__":
t = MyThread()
t.start()
for i in range(100):
print("main", i)
结果
threadTwomain 0
threadTwo0
main 11
threadTwo
main 22
5.多进程
5.1使用方法
情景一
from multiprocessing import Process
def child():
for x in range(1000):
print("child", x)
if __name__ == "__main__":
p = Process(target=child)
p.start()
for i in range(1000):
print("main", i)
结果先输出完main,再输出完child。一开始我还以为出错了,因为学csapp的时候,说的是主进程与子进程是由cpu进行调度的,因而结果应该是和多线程类似。
网上查了一下,发现好像没问题,可能是python进行了优化?先运行主进程,再运行子进程。
情景二
from multiprocessing import Process
import time
def run():
print("子进程开启")
time.sleep(2)
print("子进程结束")
if __name__ == "__main__":
print("主进程启动")
p = Process(target=run)
p.start()
print("主进程结束")
结果:
主进程启动
主进程结束
子进程开启
子进程结束
Process finished with exit code 0
5.2测试
这里我又测试一下,确实是进行调度了,至于为什么情景一的结果是顺序的,可能是因为时间间隔太短了?参考
情景三
from multiprocessing import Process
import time
def child(name, n):
time.sleep(n)
print(name)
if __name__ == "__main__":
start = time.time()
p1 = Process(target=child, args=("child1", 3))
#这里顺便说一下传参的问题,传参只能用元组(),即使只有一个元素也要写成(xxx,)的形式
p2 = Process(target=child, args=("child2", 3))
p1.start()
p2.start()
p1.join()
p2.join()
end = time.time()
print(end - start)
结果:
child1
child2
3.2381458282470703
Process finished with exit code 0
很明显,两个子进程进行调度了,因为总时间是小于6s。
6.线程池与进程池
我的理解是,一次性创建多个线程/进程,由程序进行管理哪个线程执行我们的程序,省去自己处理的麻烦。
使用方法
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time
import random
def child(name, n):
time.sleep(n)
print(name)
if __name__ == "__main__":
start = time.time()
with ThreadPoolExecutor(50) as t:
for i in range(50):
#这里参数的传递是直接标明的,好像不用传元组
t.submit(child, name=f"thread{i}", n=random.randint(1, 2))
end = time.time()
print(end - start)
结果:
thread10thread17thread14
thread4
thread5
thread0
thread16
thread2
thread7
thread6thread11
thread34thread22thread24thread30
thread36thread44
thread26
thread31
thread38
thread42
thread20
thread21
thread37thread8thread45
thread49
thread39thread48thread33thread46thread25
thread47thread41thread13
thread32thread29thread1
thread23thread12
thread15thread9thread3
thread19
thread27
thread40
thread35
thread43
thread18
thread28
2.014227867126465
Process finished with exit code 0
快的离谱,两秒就完事了,单线程正常得50秒以上。
进程池的化,就把ThreadPoolExecutor(50)改成ProcessPoolExecutor(50)就行了。
7.协程
协程不是进程或线程,其执行过程更类似于子例程,或者说不带返回值的函数调用。一个程序可以包含多个协程,可以对比与一个进程包含多个线程,因而下面我们来比较协程和线程。我们知道多个线程相对独立,有自己的上下文,切换受系统控制;而协程也相对独立,有自己的上下文,但是其切换由自己控制,由当前协程切换到其他协程由当前协程来控制。
就我的理解,协程就是线程的再划分。一个线程可以有多个协程,协程之间可相互切换,当执行的任务(例如i/o操作)阻塞时,就可以切换到另一个任务。这样可以充分利用单线程的资源。
我又上网查了一下,这么说不是很准确。dalao的博客写的很好,我就直接扒下来了,这样看的方便。dalao博客地址
7.1协程概念
“协程”(Coroutine)概念最早由 Melvin Conway 于 1958 年提出。虽然被提出的时间很早,但是使用它的年限很短。尤其是最近几年,随着 Go、Lua 等语言的流行,把协程推向了一个新的高潮。
协程其实可以认为是比线程更小的执行单元。为啥说他是一个执行单元,因为他自带CPU上下文。这样只要在合适的时机,我们可以把一个协程 切换到 另一个协程。只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
协程可以理解为纯用户态的线程,其通过协作而不是抢占来进行切换。相对于进程或者线程,协程所有的操作都可以在用户态完成,创建和切换的消耗更低。总的来说,协程为协同任务提供了一种运行时抽象,这种抽象非常适合于协同多任务调度和数据流处理。在现代操作系统和编程语言中,因为用户态线程切换代价比内核态线程小,协程成为了一种轻量级的多任务模型。
从编程角度上看,协程的思想本质上就是控制流的主动让出(yield)和恢复(resume)机制,迭代器常被用来实现协程,所以大部分的语言实现的协程中都有 yield 关键字,比如 Python、Lua。但也有特殊比如 Go 就使用的是通道来通信。先来张图看看:
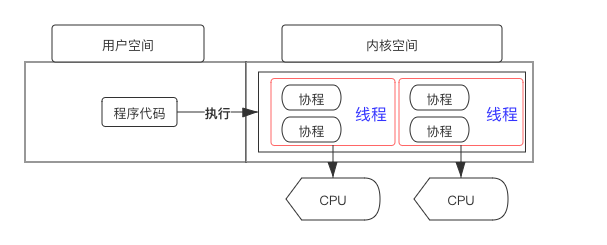
7.2协程和线程差异
那么这个过程看起来比线程差不多哇。其实不然 线程切换从系统层面远不止 保存和恢复 CPU上下文这么简单。操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
7.3协程的问题
但是协程有一个问题,就是系统并不感知,所以操作系统不会帮你做切换。那么谁来帮你做切换?让需要执行的协程更多的获得CPU时间才是问题的关键。
7.3.1协程目前主流设计
目前的协程框架一般都是设计成 1:N 模式。所谓 1:N 就是一个线程作为一个容器里面放置多个协程。那么谁来适时的切换这些协程?答案是有协程自己主动让出CPU,也就是每个协程池里面有一个调度器,这个调度器是被动调度的。意思就是他不会主动调度。而且当一个协程发现自己执行不下去了(比如异步等待网络的数据回来,但是当前还没有数据到),这个时候就可以由这个协程通知调度器,这个时候执行到调度器的代码,调度器根据事先设计好的调度算法找到当前最需要CPU的协程。切换这个协程的CPU上下文把CPU的运行权交个这个协程,直到这个协程出现执行不下去需要等等的情况,或者它调用主动让出CPU的API之类,触发下一次调度。对的没错就是类似于 领导人模式
7.3.2这个设计有问题吗?
其实是有问题的,假设这个线程中有一个协程是CPU密集型的且没有IO操作,也就是自己不会主动触发调度器调度的过程,那么就会出现其他协程得不到执行的情况,所以这种情况下需要程序员自己避免。这是一个问题,假设业务开发的人员并不懂这个原理的话就可能会出现问题。
7.3.3协程举例理解
在所有语言中都存在着层级调用,比如 A 调用 B,B 在执行过程中又调用了 C,C 执行完毕返回,B 执行完毕返回,最后是 A 执行完毕。这种方法、函数、子程序的调用方式都是通过 栈 实现的,一个线程就是执行一个子程序。子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
public void coroutineA() {
System.out.println("1");
System.out.println("2");
System.out.println("3");
}
public void coroutineB() {
System.out.println("a");
System.out.println("b");
System.out.println("c");
}
上面代码如果由协程来执行,那么在执行 coroutineA 的过程中,可以随时中断,去执行 coroutineB,coroutineB 也可能在执行过程中中断再去执行 coroutineA,所以,最终的结果可能是:
1
a
b
2
c
3
但是,在上面的代码中,并没有在 coroutineA 方法中调用 coroutineB。执行结果就像两个线程在并发执行。但其实,通过协程执行用的是一个线程,只不过这个线程看起来有点“到处乱跑”。
7.4协程优势
协程 vs 线程 比较有以下 3 个重要的优势:
1、减少了线程切换的成本。线程,不管是创建还是切换,都需要较高的成本。子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。这也就是说,协程的效率比较高
2、协程的第二大优势就是没有并发问题,不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多
3、协程更轻量级。创建一个线程栈大概需要 1M 左右,而协程栈大概只需要几 K 或者几十 K。
有优势也有劣势,因为前面的程序看起来在“上串下跳”,所以,协程看起来没那么好控制。
7.5协程认知注意
1、对于操作系统来说只有进程和线程,协程的控制由应用程序显式调度,非抢占式的
2、协程的执行最终靠的还是线程,应用程序来调度协程选择合适的线程来获取执行权
3、协程适合于 IO 密集型场景,这样能提高并发性,比如请求接口、Mysql、Redis 等的操作
4、协程并不是说替换异步,协程一样可以利用异步实现高并发。
5、协程要利用多核优势就需要比如通过调度器来实现多协程在多线程上运行,这时也就具有了并行的特性。如果多协程运行在单线程或单进程上也就只能说具有并发特性。
7.6协程在python中的使用
网课上讲的比较粗,我又查了一下await的用法。又又从dalao的博客扒了(>人<;),dalao写的太好,自己就懒得搞了。dalao博客地址。另外还有一个dalao写的很好,可以看看。博客地址
7.6.1await的使用
from time import sleep, time
def demo1():
"""
假设我们有三台洗衣机, 现在有三批衣服需要分别放到这三台洗衣机里面洗.
"""
def washing1():
sleep(3) # 第一台洗衣机, 需要洗3秒才能洗完 (只是打个比方)
print('washer1 finished') # 洗完的时候, 洗衣机会响一下, 告诉我们洗完了
def washing2():
sleep(2)
print('washer2 finished')
def washing3():
sleep(5)
print('washer3 finished')
washing1()
washing2()
washing3()
"""
这个还是很容易理解的, 运行 demo1(), 那么需要10秒钟才能把全部衣服洗完.
没错, 大部分时间都花在挨个地等洗衣机上了.
"""
def demo2():
"""
现在我们想要避免无谓的等待, 为了提高效率, 我们将使用 async.
washing1/2/3() 本是 "普通函数", 现在我们用 async 把它们升级为 "异步函数".
注: 一个异步的函数, 有个更标准的称呼, 我们叫它 "协程" (coroutine).
"""
async def washing1():
sleep(3)
print('washer1 finished')
async def washing2():
sleep(2)
print('washer2 finished')
async def washing3():
sleep(5)
print('washer3 finished')
washing1()
washing2()
washing3()
"""
从正常人的理解来看, 我们现在有了异步函数, 但是却忘了定义应该什么时候 "离开" 一台洗衣
机, 去看看另一个... 这就会导致, 现在的情况是我们一边看着第一台洗衣机, 一边着急地想着
"是不是该去开第二台洗衣机了呢?" 但又不敢去 (只是打个比方), 最终还是花了10秒的时间才
把衣服洗完.
PS: 其实 demo2() 是无法运行的, Python 会直接警告你:
RuntimeWarning: coroutine 'demo2.<locals>.washing1' was never awaited
RuntimeWarning: coroutine 'demo2.<locals>.washing2' was never awaited
RuntimeWarning: coroutine 'demo2.<locals>.washing3' was never awaited
"""
def demo3():
"""
现在我们吸取了上次的教训, 告诉自己洗衣服的过程是 "可等待的" (awaitable), 在它开始洗衣服
的时候, 我们可以去弄别的机器.
"""
async def washing1():
await sleep(3) # 注意这里加入了 await
print('washer1 finished')
async def washing2():
await sleep(2)
print('washer2 finished')
async def washing3():
await sleep(5)
print('washer3 finished')
washing1()
washing2()
washing3()
"""
尝试运行一下, 我们会发现还是会报错 (报错内容和 demo2 一样). 这里我说一下原因, 以及在
demo4 中会给出一个最终答案:
1. 第一个问题是, await 后面必须跟一个 awaitable 类型或者具有 __await__ 属性的
对象. 这个 awaitable, 并不是我们认为 sleep() 是 awaitable 就可以 await 了,
常见的 awaitable 对象应该是:
await asyncio.sleep(3) # asyncio 库的 sleep() 机制与 time.sleep() 不
同, 前者是 "假性睡眠", 后者是会导致线程阻塞的 "真性睡眠"
await an_async_function() # 一个异步的函数, 也是可等待的对象
以下是不可等待的:
await time.sleep(3)
x = await 'hello' # <class 'str'> doesn't define '__await__'
x = await 3 + 2 # <class 'int'> dosen't define '__await__'
x = await None # ...
x = await a_sync_function() # 普通的函数, 是不可等待的
2. 第二个问题是, 如果我们要执行异步函数, 不能用这样的调用方法:
washing1()
washing2()
washing3()
而应该用 asyncio 库中的事件循环机制来启动 (具体见 demo4 讲解).
"""
def demo4():
"""
这是最终我们想要的实现.
"""
import asyncio # 引入 asyncio 库
async def washing1():
await asyncio.sleep(3) # 使用 asyncio.sleep(), 它返回的是一个可等待的对象
print('washer1 finished')
async def washing2():
await asyncio.sleep(2)
print('washer2 finished')
async def washing3():
await asyncio.sleep(5)
print('washer3 finished')
"""
事件循环机制分为以下几步骤:
1. 创建一个事件循环
2. 将异步函数加入事件队列
3. 执行事件队列, 直到最晚的一个事件被处理完毕后结束
4. 最后建议用 close() 方法关闭事件循环, 以彻底清理 loop 对象防止误用
"""
# 1. 创建一个事件循环
loop = asyncio.get_event_loop()
# 2. 将异步函数加入事件队列
tasks = [
washing1(),
washing2(),
washing3(),
]
# 3. 执行事件队列, 直到最晚的一个事件被处理完毕后结束
loop.run_until_complete(asyncio.wait(tasks))
"""
PS: 如果不满意想要 "多洗几遍", 可以多写几句:
loop.run_until_complete(asyncio.wait(tasks))
loop.run_until_complete(asyncio.wait(tasks))
loop.run_until_complete(asyncio.wait(tasks))
...
"""
# 4. 如果不再使用 loop, 建议养成良好关闭的习惯
# (有点类似于文件读写结束时的 close() 操作)
loop.close()
"""
最终的打印效果:
washer2 finished
washer1 finished
washer3 finished
elapsed time = 5.126561641693115
(毕竟切换线程也要有点耗时的)
说句题外话, 我看有的博主的加入事件队列是这样写的:
tasks = [
loop.create_task(washing1()),
loop.create_task(washing2()),
loop.create_task(washing3()),
]
运行的效果是一样的, 暂不清楚为什么他们这样做.
"""
if __name__ == '__main__':
# 为验证是否真的缩短了时间, 我们计个时
start = time()
# demo1() # 需花费10秒
# demo2() # 会报错: RuntimeWarning: coroutine ... was never awaited
# demo3() # 会报错: RuntimeWarning: coroutine ... was never awaited
demo4() # 需花费5秒多一点点
end = time()
print('elapsed time = ' + str(end - start))
7.6.2爬虫的使用
dalao的写法跟老师讲的有一点点区别,这里也列一下用法。
import asyncio
import time
import random
async def test(t, n):
print("test", n,"begin")
await asyncio.sleep(t)
print("test end")
async def main():
tasks = []
for i in range(1, 5):
tasks.append(test(random.randint(2, 4), i))
await asyncio.wait(tasks)
if __name__ == '__main__':
t1 = time.time()
asyncio.run(main())
t2 = time.time()
print(t2 - t1)
结果:
C:\Users\戴明旺\AppData\Local\Programs\Python\Python39\python.exe F:/Python_Projects/多线程/test.py
F:\Python_Projects\多线程\test.py:16: DeprecationWarning: The explicit passing of coroutine objects to asyncio.wait() is deprecated since Python 3.8, and scheduled for removal in Python 3.11.
await asyncio.wait(tasks)
test 2 begin
test 4 begin
test 1 begin
test 3 begin
test end
test end
test end
test end
3.01310133934021
Process finished with exit code 0
从警告信息中得出在python3.8后直接把协程对象传给asyncio.wait()是不行的,必须封装成tasks对象传入。在python3.11后则是会报错。老师的是python3.7所以用的这个没报错,我们得改成另一种写法。
tasks.append(asyncio.create_task(test(random.randint(2, 4), i)))
7.6.3python异步常用包
aiohttp
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=header) as resp:
print(await resp.text())
注意 resp.text()前面也要加await
aiofiles
async with aiofiles.open("所有主页.csv", mode="a", newline='') as f:
writer = aiocsv.AsyncWriter(f)
顺便用了aiocsv
8.selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
对于爬虫也是很好用的工具。
8.1环境安装
-
pip install selenium -
安装浏览器驱动
因为我用edge,所以用edge的驱动。edge驱动官网。如果是别的浏览器,也可以安装对应的驱动。
安装的驱动要和浏览器的版本相对应。在edge浏览器的设置->关于edge中,可以看到浏览器版本。

下载好的驱动,解压放到python解释器的位置,python解释器的位置可以从python控制台中看到。

将exe文件放在C:\Users\xxx\AppData\Local\Programs\Python\Python39\Scripts处。
然后进行测试
from selenium.webdriver import Edge #记住一定要大写Edge、Chorme,否则edge、chorme找不到浏览器。 web = Edge() web.get("https://www.baidu.com/") #打开edge
8.2selenium使用
8.2.1所有情况需要的包
from selenium.webdriver import Edge #导入浏览器
from selenium.webdriver.common.by import By #find_elements的方式参数的包
import time
from selenium.webdriver.common.keys import Keys #输入按键的包
8.2.2点击页面
web = Edge()
web.get("https://www.1ppt.com/moban/ppt_moban_13.html")
time.sleep(5)
el = web.find_element(by=By.XPATH,value="/html/body/div[5]/dl/dd/ul/li[1]/a/img")
el.click()
终于学到点击的功能!注意不要尝试大网站——百度、B站之类的,它们的反爬措施会致使获取不到元素。除此之外,在爬取元素时,最好等待几秒,使网页完全加载出来。
8.2.3向文本框输入
web = Edge()
web.get("https://www.1ppt.com/moban/ppt_moban_13.html")
time.sleep(2)
el = web.find_element(by=By.XPATH,value="/html/body/div[2]/div[2]/div[2]/div[1]/div[1]/form/input[2]")
el.send_keys("test",Keys.ENTER) #输入文本,并输入enter。也可以使用点击的方式。
8.2.4切换窗口
web.switch_to.window(web.window_handles[-1]) #跳到最后一个窗口
进行测试
代码:
web = Edge()
web.get("https://www.1ppt.com/moban/ppt_moban_13.html")
time.sleep(2)
el = web.find_element(by=By.XPATH,value="/html/body/div[5]/dl/dd/ul/li[1]/a/img")
el.click()
time.sleep(1)
print("点击后页面:",web.title)
web.switch_to.window(web.window_handles[-1])
print("切换后页面:",web.title)
time.sleep(1)
web.close()
try:
print(web.title)
except:
print("关闭后页面:error!")
time.sleep(1)
web.switch_to.window(web.window_handles[0])
print("切换后页面:",web.title)
结果:
点击后页面: PPT模板下载_PPT模板免费下载 - 第一PPT
切换后页面: 卡通宇宙星球背景的太空主题PPT模板 - 第一PPT
关闭后页面:error!
切换后页面: PPT模板下载_PPT模板免费下载 - 第一PPT
Process finished with exit code 0
我一开始看打开的页面效果,以为是自行切换,试了一下,结果实际的页面是不切换的。。。
补充
iframe = web.find_element(by=By.XPATH,"XXX")
web.switch_to.frame(iframe) # 切到iframe
web.switch_to.default_content() #切到默认页面
切到iframe处,好像不是很常用。
8.2.5下拉列表的处理
from selenium.webdriver import Edge
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
web = Edge()
web.get("https://www.1ppt.com/moban/ppt_moban_13.html")
sel_el = web.find_element(by=By.XPATH,"XXXX")
sel = Select(sel_el) #对元素进行包装,包装成下拉列表。
for i in range(len(sel.options)): #i是下拉索引的位置
sel.select_by_index(i) #按照索引进行切换
print(web.title)
print(web.page_source)
web.close()
没找到好的网页例子,大概看下代码就行。
补充: web.page_source拿到的是页面代码elements(经过数据加载以及js执行后的html内容)
8.3无头浏览器
from selenium.webdriver import Edge
from selenium.webdriver.chrome.options import Options
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
caps = {"browserName": "MicrosoftEdge",
"version": "",
"platform": "WINDOWS",
"ms:edgeOptions": {
'extensions': [],
'args': ['--headless',
'--disable-gpu']}}
web = Edge(options=opt,capabilities=caps)
web.get("https://www.1ppt.com/moban/ppt_moban_13.html")
print(web.title)
web.close()
老师讲的只用一个options参数,但我使用会报错。网上查到的是用capabilities参数,用了,但仍然会打开浏览器。同时使用options与caps参数就没问题,不太清楚原因。
顺便说一下反爬参数
就是关掉那个自动化测试的标识。
from selenium.webdriver.chrome.options import Options
edge_options = Options()
# 开启开发者模式
edge_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用启用Blink运行时的功能
edge_options.add_argument('--disable-blink-features=AutomationControlled')
老师讲的比这个方法多了一种,是打开网页的时候,对于版本小于88的chorm浏览器,运行一段js代码,去除源码中的window.navigator.webdriver
web = Edge()
web.get("https://www.1ppt.com/moban/ppt_moban_13.html")
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{
"source":"""
navigator.webdriver = undefined
Object.defineProperty(navigator,'webdriver',{
get:() => undefined})
})
"""
})
我在网上还搜索了一下,还有一些其他的解决办法。这篇文章写的挺好。
8.4处理验证码
看了视频,感觉挺简单,就是从网上找一个api接口(视频用的是超级鹰),来进行图像识别。把识别结果进行输入即可。
这里补充一些用上的语句:
from selenium.webdriver.common.action_chains import ActionChains #导入事件链包
sel_el.screenshot_as_png() #截取屏幕
ActionChains.move_to_element_with_offset(sel_el,x,y).click().perform() #进行一系列的事件,最后一定要perform
类似的还有处理拖拽:
ActionChains.drag_and_drop_by_offset(el,x,y).perform()
找到拖拽的元素,并通过检查可以看到要拖拽的长度。
注意x是横向距离,y是纵向距离,一般y为0。
9.结语
哇,爬虫终于学完了,从上个学期开始学,断断续续_(:з」∠)_,到现在才学完。其实,那几个案例我还没做,有时间再补一补。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号