
Python从零开始写爬虫-1 使用Python发送http请求并获得网页源代码
写爬虫, 首先需要了解爬虫是什么?网络爬虫,是自动从网络下载自己需要的网页,进行处理并保存的工具.Python从零开始写爬虫将从零开始写爬虫,最终该爬虫能够从笔趣阁(http://www.biquger.com/)爬取小说.
竟然爬虫是自动下载自己需要的网页, 那么Python如何获取网页呢?Python通过发送http请求到网页服务器,从而获得网页的源码.python使用http请求主要有4种方式:
urllib
- Requests
- Octopus
- HTTPie
其中Request是目前最受欢迎的的http请求库. 本教程也将使用该库来进行http请求. Reustests不是Python自带的库, 所以需要通过pip进行安装, python 3 以及pip的安装请自行百度安装:
pip install requests
安装成功后:

这个时候, 就可以在python中使用Requests了.
首先导入Requests库
import requests
导入之后, 就可以使用其来发送http请求了.这里以获取Python的Api文档https://docs.python.org/zh-cn/3/library/index.html为例
r = requests.get('https://docs.python.org/zh-cn/3/library/index.html')
之后就可以输入获取到的网页了.
print(r.text)
输出之后,会发现出现许多乱码.
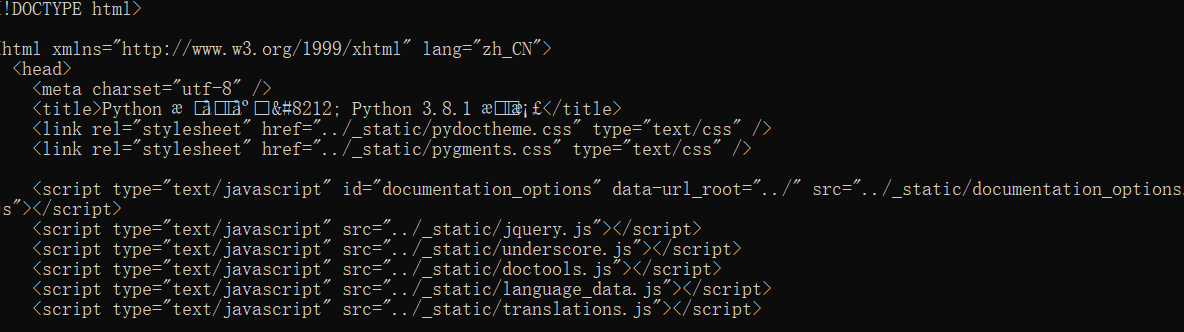
做过网页开发的人应该都知道这是应为编码的问题,获取Requests使用的网络编码:
print(r.encoding)

发现Requests使用的是ISO-8859-1编码, 而通过查看网页源码发现,该网页使用的是UTF-8编码.这应该就是造成乱码的原因,设置Request的编码:
r.encoding='utf-8'
之后在输出网页, 发现乱码消失了.
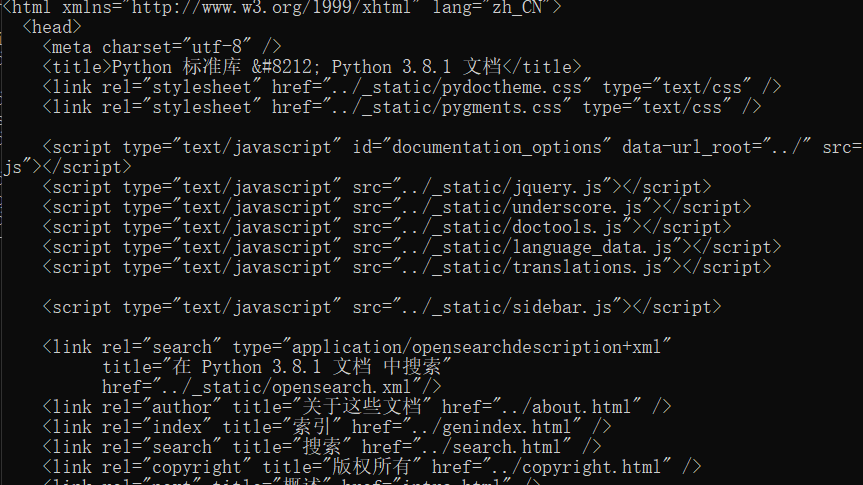
Python从零开始写爬虫第一步, 使用http请求后的网页源码就已经完成了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号