
scala的一些重点语法
case class
1. 初始化的时候可以不加new,这条基本没什么用
2. 默认实现了equals 和 hashCode方法。
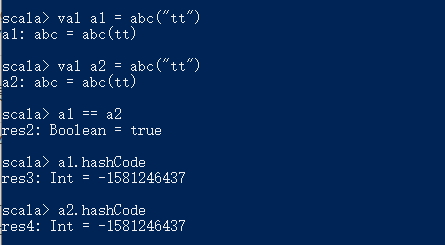
3. 默认是可以序列化的,也就是实现了Serializable

4. 自动从scala.Product中继承了一些函数。
5. case class 构造函数是public级别的,我们可以直接访问。

6. 支持模式匹配,应该算是最重要的属性。
DataFrame
可以将它看作一个数据表。有对应的spark sql API可供调用。
RegexTokenizer
RegexTokenizer允许基于正则的方式进行文档切分成单词组。默认情况下,使用参数“pattern”( regex, default: "\s+")作为分隔符来分割输入文本。或者,用户可以将参数“gaps”设置为false,指示正则表达式“pattern”表示“tokens”,而不是分割间隙,并查找所有匹配事件作为切分后的结果。
createDataFrame是SparkSession里面的方法。利用CreateDataFrame可以创建一个dataFrame对象,可以对其进行定义管道,继而进行TF统计,IDF统计,就可以将分词结果转换为tf-idf值了。
接下来就是代码中的tf-idf模型和逻辑斯蒂回归模型了。
首先代码中使用hashingtf来计算词频,dataframe中每一个行是一个词频计算的单位。并且使用hash函数将token映射到不同的桶中。这一步容易出现hash碰撞。接着使用spark中的IDF类进行idf处理。
相关的公式如下图:

截图中计算idf的log是自然对数。
package org.example import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer} import org.apache.spark.sql.SparkSession object ti { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf() .setAppName("logv_learning") .setMaster("local") .set("spark.driver.allowMultipleContexts", "true") .set("spark.executor.cores", "10") .set("spark.executor.memory", "30G") .set("spark.driver.memory", "30G") val sparkContext = new SparkContext(sparkConf) val sparkSession = SparkSession.builder() .master("127.0.0.1") .appName("logv_learning") .getOrCreate() val sentenceData = sparkSession.createDataFrame(Seq( (0, "Hi I heard about Spark"), (0, "I wish Java could use case classes"), (1, "Logistic regression models are neat") )).toDF("label", "sentence") val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words") val wordsData = tokenizer.transform(sentenceData) val hashingTF = new HashingTF() .setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(30) val featurizedData = hashingTF.transform(wordsData) featurizedData.select("words","rawFeatures").take(3).foreach(println) // CountVectorizer也可获取词频向量 val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features") val idfModel = idf.fit(featurizedData) val rescaledData = idfModel.transform(featurizedData) rescaledData.select("features", "label").take(3).foreach(println) } }
上面的代码是一个运行的例子。

这是运行结果,0.693147是通过1*ln(2)得到的。
至于逻辑斯蒂回归模型,本文研究的是二分类问题。其损失函数为:
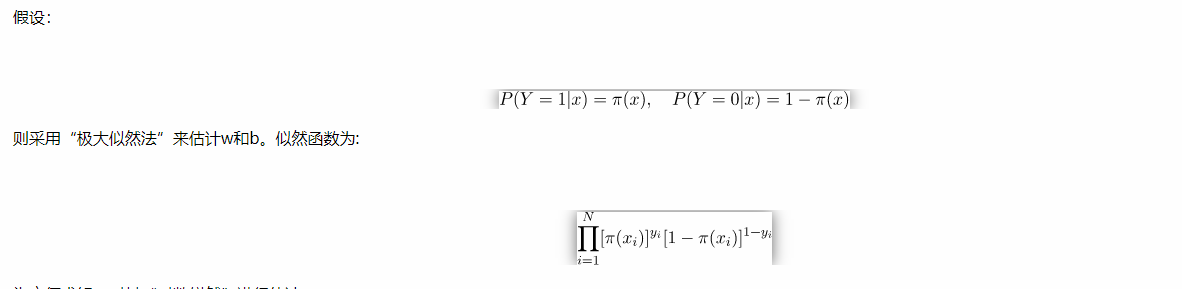
目的是使每个样本被估计的概率更大
然后通过求导,求梯度来更新损失函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号