
学习scala文档
首先先看一个helloworld程序:

和java很像,包含了一个main函数。main函数接受一个string数组作为输入,函数体调用了println函数。main函数没有返回值,因此它的返回值被声明为Unit。
和Java有点儿不一样的是object这个关键字。这个关键字代表这个类只能有一个实例。这个实例在第一次使用时按需创建。
和Java不一样的还有,main方法没有被static修饰,因为静态的方法和fields在scala中压根不存在。比起声明为静态成员(一个类中只有一份),scala更喜欢声明只有一个实例的类。
scala的一个特点是很容易和java交互,所有java.lang中的类可以默认导入scala.其他包需要显式导入。

这是一个导入其他包的例子。
导入的语句有点儿不同,同一个包下的类,可以通过大括号来进行批次导入。导入一个包中所有的类,采用_.不采用*,因为*在scala中是一个有意义的符号。
最后一句df format now 类似于df.format(now)
scala秉持的思想是Everything is an Object,不想Java还要特意区分boolean/int为引用类型。
因为Numbers也是object,它们应该有方法。+ - */就是它们的方法。
1 + 2 * 3 / x 类似于 1.+(2.*(3)./(x))
Functions are objects!!!
函数也是scala中的对象。因此可以将function作为参数。这种将函数作为值操作的想法是函数编程的基石之一。

上面就是将函数作为一个参数输入的例子。callback是参数名,() => Unit是参数类型,是一个输入为空,输出为空的函数。
我们还可以对上面的函数进行改进,可以使用匿名函数的功能。

匿名函数是没有名字的函数,=>将匿名函数分为参数表和函数体两部分。
scala中除了object关键字,还有class关键字。
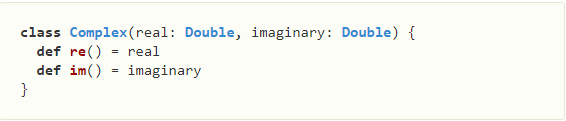
声明class可以带参数的。这好像就是将Java中的构造函数省略,直接将参数加到了class的声明上,函数体中的re,im是两个访问对应变量的方法。
上面的class还可以改变为下面的样子:

改变之后的re,im是根本没有参数的方法,和re(),im()这些空参数的方法是不同的。
scala中的所有class均是继承自一个super-class,可以像Java中那样对super-class中的方法进行重写。
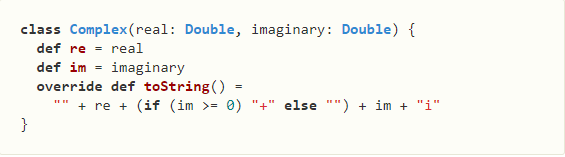
调用直接使用c.toString即可。
case class
case class有如下特点:
1. 创建实例时不需要用new
2. getter函数自动被定义,
3. equals和hashCode这种函数被默认被提供。
4.toString方法也默认被提供。
5. 这些类的实例可以通过模式匹配来分解。就像下面的例子一样,默认创建出来,如果不匹配就删了。
现在做一个小任务,做一个计算器,算式中包括+,数,变量。按照往常的习惯必定使用树结构来表示,先声明一个tree,接着声明一个Node.但是如果使用case class来表示的话就不是这种想法了。

接着想一下,变量的值怎么指定呢?可以使用一个string => int的函数来进行转换。

接着等式就可以表示为如下的形式:

这个函数,它首先检查t是不是Sum,如果是将树的左半部分赋值给l,右半部分赋值给r,分别调用eval函数。
如果t不是Sum,然后再判定t是不是Var,如果是将这个Var节点绑定到变量上,
如果两者都不是,t就是一个Const,那么就将在Const节点中的值绑定到变量v上,执行函数右边的部分。
最后如果都不匹配就声明一个错误。

下面是一个例子:

trait相当于Java中的接口。
下面写一个类似于comparable的一个接口:

接下来实现日期间比较的功能:

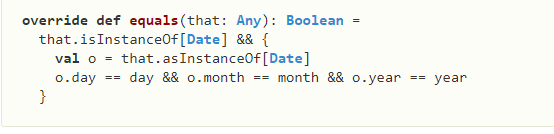
scala最后一个特点就是泛型,scala可以定义泛型类。

类Reference参数是一个类型,叫做T
下面是使用泛型类的例子:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号