RDD
\(\color{red}{RDD基础}\)
RDD是一个不可变的分布式对象集合。RDD可以包含Python,Java,Scala中任意类型的对象,甚至可以包含用户自定义的对象。
创建RDD方法:
1.读取外部数据集
2.分发对象集合
RDD支持两种类型的操作:
1.转化操作:由一个RDD生产一个新的RDD
2.行动操作:对RDD计算出一个结果
Spark只会惰性计算RDD。如:
lines = sc.textFile("README.MD")
pythonlines = lines.filter(lambda line:"Python" in line)
pythonlines.first()
Spark并不会读取进README.MD整个文件,它只会在必须计算(行动操作)的时候才会读取数据,此处,Sprak它只需要扫描文件直到找到第一个匹配就行,而不需读取整个文件
默认情况下,Spark的RDD并不会保留结果(每当我们调用一个新的行动操作时,整个RDD都会从头开始计算)。因此如果想重用同一个RDD,可以使用RDD.persist()让Spark把这个RDD缓存下来。
Spark程序或shell回话基本按如下方式工作
1.从外部数据创建出输入RDD
2.对RDD进行转化,以定义新的RDD
3.对需要被重用的中间结果RDD执行persist()操作
4.使用行动操作来触发一次并行计算,
\(\color{red}{创建RDD}\)
创建RDD方法:
1.读取外部数据集
2.在驱动器程序中对一个集合进行并行化
最简单的方法:把一个集合传给SprakContext的parallelize()方法,但该方法通常用于开发和测试中,因为这种方式需要把整个数据集放在一台机器的内存中
lines=sc.parallelize(["pandas","I like pandas"])
更常用的是从外部存储中读取数据来创建RDD。
lines = sc.textFile("README.MD")
\(\color{red}{RDD操作}\)
\(\color{maroon}{转化操作返回的是RDD,行动操作返回的是其他的数据类型}\)
\(\color{blue}{转化操作}\)
转化操作是惰性的。
转化操作可以操作任意数量的输入RDD
Spark使用谱系图来记录RDD之间的依赖关系。Spark根据谱系图在持久化的RDD丢失部分数据时恢复所丢失的数据。
\(\color{blue}{行动操作}\)
RDD.take(n)取RDD中的前n个元素
RDD.collect()获取整个RDD中的数据(加载到单台机器的内存中)
通常由于数据量太大不会用Collect方法,而是通过saveAsTextFile(),saveAsSequenceFile()等方法把数据写到如HDFS这样的分布式的存储系统中。
\(\color{blue}{惰性求值}\)
惰性求值:在被调用行动操作之前Spark不会开始计算。
Spark会在内部记录下所要求执行的操作的相关信息
\(\color{red}{向Spark传递函数}\)
在Python中,有三种方式来向Spark传递函数
1.lambda
2.顶层函数
3.局部函数
\(\color{red}{常见的转化操作和行动操作}\)
数字类型的RDD支持统计型函数操作
键值对形式的RDD则支持诸如根据键聚合数据的键值对操作
\(\color{blue}{基本RDD}\)
1,针对各个元素的转化操作
map,filter
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect()
对每个输入元素生成多个输出元素,实现该功能的操作叫做flatMap()
map返回的是由列表组成的RDD
flatMap返回的是各列表中的元素组成的RDD
看map与flatMap差别
lines = sc.parallelize(["hello world","hi"])
words = lines.flatMap(lambda line : line.split(" "))
mapwords = lines.map((lambda line : line.split(" ")))
2.伪集合操作
RDD支持许多数学上的集合操作
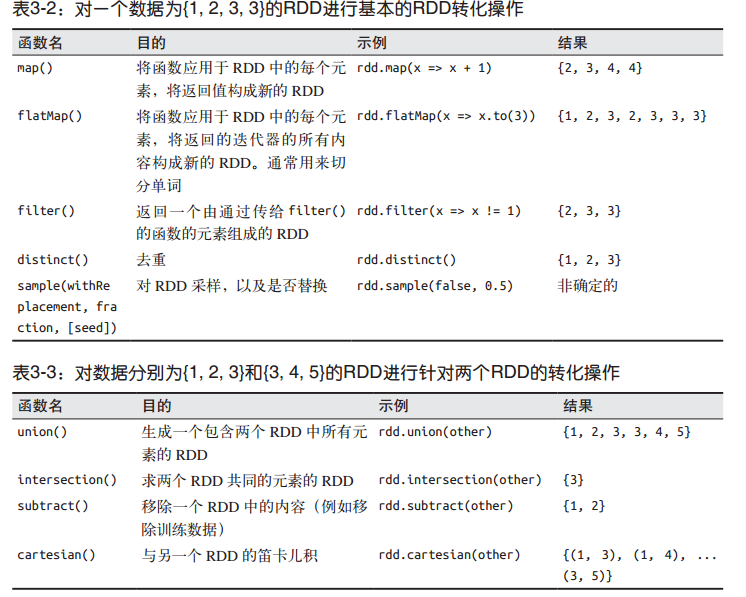
3.行动操作

\(\color{red}{持久化(缓存)}\)
如果要缓存的数据太多,Spark会自动利用最近最少利用的缓存策略把最老的分区从内存中移除。程序并不会因为缓存了太多数据而被打断。通常只会带来更多重算的时间开销。
unpersist(),调用该方法可以把持久化的RDD从缓存中移除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号