数据采集第五次作业
作业①
(1)、要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
编写爬虫程序
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
# # Initializing Chrome browser
#chrome_options = Options()
#chrome_options.add_argument('--headless')
#chrome_options.add_argument('--disable-gpu')
#self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver = webdriver.Chrome(r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
# Initializing variables
self.threads = []
self.No = 0
self.imgNo = 0
# Initializing database
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="root", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table curtains")
except:
pass
try:
# 建立新的表
sql = "create table curtains(mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
# Initializing images folder
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath) #返回指定的文件夹包含的文件或文件夹的名字的列表
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into curtains(mNo,mMark,mPrice,mNote,mFile)values (%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print(err)
def showDB(self):
try:
con = sqlite3.connect("curtains.db")
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from curtains order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
#currentPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='curr']").text
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
currentPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='curr']").text
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
输出信息
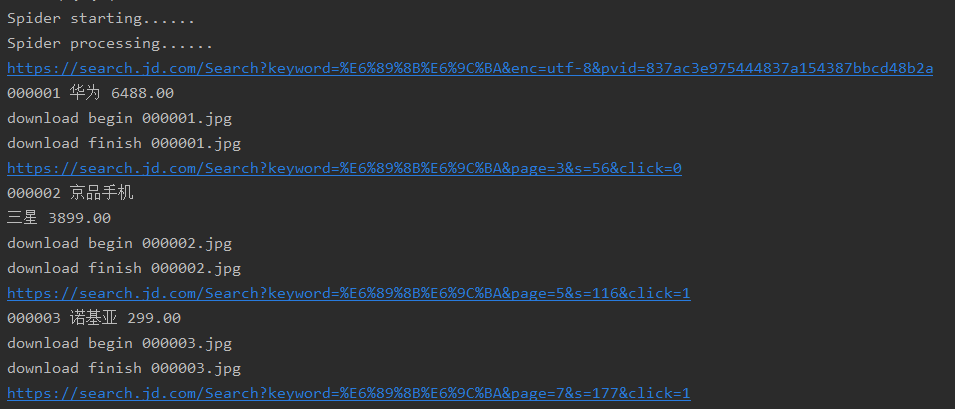
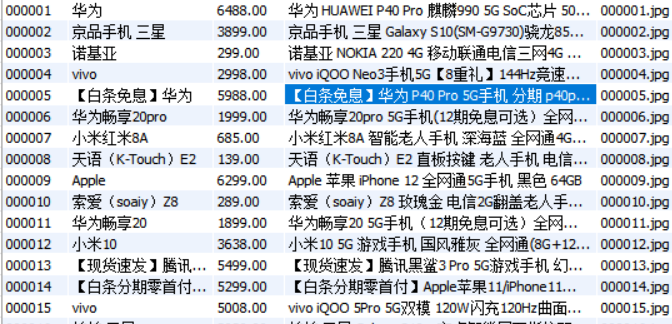

(2)、心得体会
照着代码打了一遍,对selenium的应用有了初步的理解
作业②
(1)、要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
编写爬虫程序
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import datetime
from selenium.webdriver.common.keys import Keys
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url,key):
# # Initializing Chrome browser
#chrome_options = Options()
#chrome_options.add_argument('--headless')
#chrome_options.add_argument('--disable-gpu')
#self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver = webdriver.Chrome(r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
self.driver.get(url)
# Initializing variables
self.bankuai = ["nav_hs_a_board", "nav_sh_a_board", "nav_sz_a_board"]
self.bankuai_id = 0; # 当前板块
# Initializing database
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="root", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table stocks2")
except Exception as err:
print(err)
try:
# 建立新的表
sql = "create table stocks2(序号 varchar(128),代码 varchar(128),名称 varchar(128),最新价格 varchar(128),涨跌额 varchar(128),涨跌幅 " \
"varchar(128),成交量 varchar(128),成交额 varchar(128),振幅 varchar(128)," \
"最高 varchar(128),最低 varchar(128),今开 varchar(128),昨收 varchar(128));"
self.cursor.execute(sql)
except Exception as err:
print(err)
except Exception as err:
print(err)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self,number,daima,name,new,zangfu,e,chengjiao,jiaoe,zhenfu,max,min,today,ye):
try:
sql = "insert into stocks2(序号,代码,名称,最新价格,涨跌额,涨跌幅,成交量,成交额,振幅,最高,最低,今开,昨收)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(number,daima,name,new,zangfu,e,chengjiao,jiaoe,zhenfu,max,min,today,ye))
except Exception as err:
print(err)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
trs = self.driver.find_elements_by_xpath("//table[@class='table_wrapper-table']/tbody/tr")
for tr in trs:
number = tr.find_elements_by_xpath("./td")[0].text
daima = tr.find_elements_by_xpath("./td")[1].text
name = tr.find_elements_by_xpath("./td")[2].text
new = tr.find_elements_by_xpath("./td")[4].text
zangfu = tr.find_elements_by_xpath("./td")[5].text
e = tr.find_elements_by_xpath("./td")[6].text
chengjiao = tr.find_elements_by_xpath("./td")[7].text
jiaoe = tr.find_elements_by_xpath("./td")[8].text
zhenfu = tr.find_elements_by_xpath("./td")[9].text
max = tr.find_elements_by_xpath("./td")[10].text
min = tr.find_elements_by_xpath("./td")[11].text
today = tr.find_elements_by_xpath("./td")[12].text
ye = tr.find_elements_by_xpath("./td")[13].text
try:
self.insertDB(number,daima,name,new,zangfu,e,chengjiao,jiaoe,zhenfu,max,min,today,ye)
except Exception as err:
print(err)
print("插入失败")
self.bankuai_id += 1
next = self.driver.find_element_by_xpath("//li[@id='"+self.bankuai[self.bankuai_id]+"']/a")
self.driver.execute_script("arguments[0].click();", next)
time.sleep(100)
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url ="http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = MySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executeSpider(url,"key")
elif s == "2":
break
输出信息
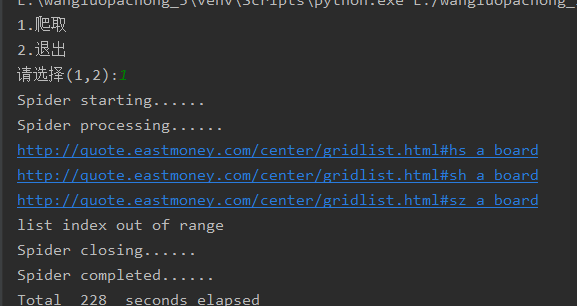
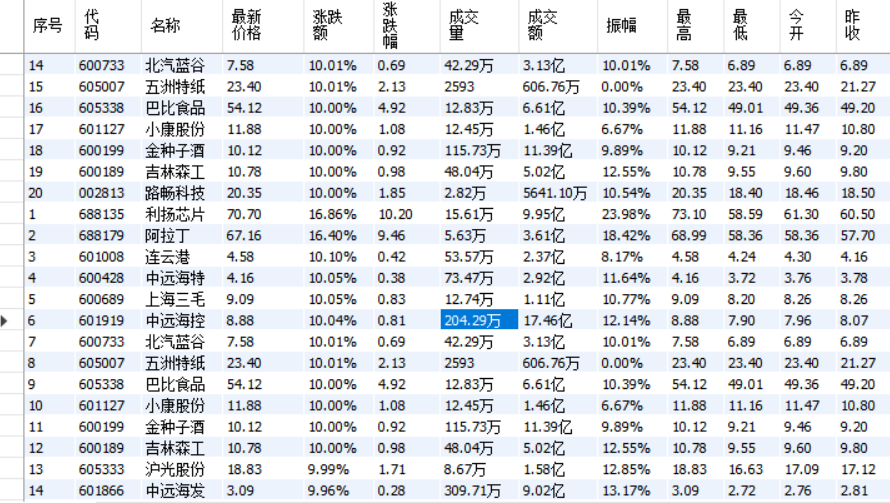
(2)、心得体会:
对selenium的使用更加熟练,本来想用scrapy框架的,但是在切换板块的时候遇到了困难,故放弃,对scrapy框架的掌握还不够
作业③
(1)、要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
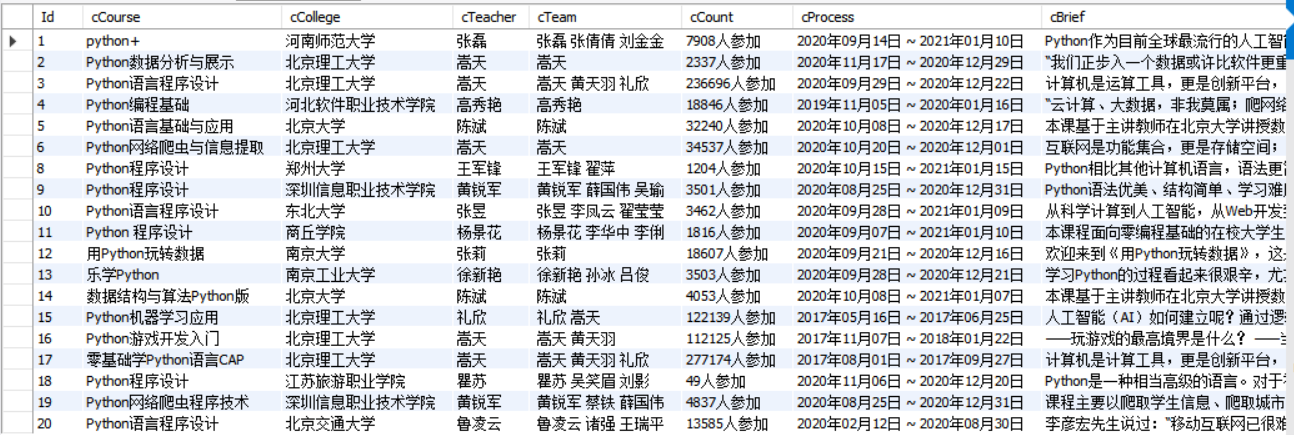
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
编写爬虫程序
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import datetime
from selenium.webdriver.common.keys import Keys
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
# # Initializing Chrome browser
#chrome_options = Options()
#chrome_options.add_argument('--headless')
#chrome_options.add_argument('--disable-gpu')
#self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver = webdriver.Chrome(r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
# Initializing variables
self.threads = []
self.count = 0
# Initializing database
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="root", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table courses")
except Exception as err:
print(err)
try:
# 建立新的表
sql = "create table courses(Id int,cCourse VARCHAR (32),cCollege VARCHAR(32),cTeacher VARCHAR(32),cTeam VARCHAR(32),cCount VARCHAR(32),cProcess VARCHAR(32),cBrief VARCHAR(512))"
self.cursor.execute(sql)
except Exception as err:
print(err)
except Exception as err:
print(err)
# Initializing images folder
self.driver.get(url)
keyInput = self.driver.find_element_by_xpath("//div[@class='u-baseinputui']//input")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, id, ccourse, ccollege, cteacher, cTeam, ccount, cprocess, cbrief):
try:
sql = "insert into courses(id,ccourse,ccollege,cteacher,cTeam,ccount,cprocess,cbrief)values(%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(id,ccourse,ccollege,cteacher,cTeam,ccount,cprocess,cbrief))
except Exception as err:
print(err)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
divs = self.driver.find_elements_by_xpath("//div[@class='m-course-list']//div[@class='g-mn1']")
for div in divs:
try:
ccourse = div.find_element_by_xpath(".//span[@class=' u-course-name f-thide']").text
ccollege = div.find_element_by_xpath(".//a[@class='t21 f-fc9']").text
cteacher = div.find_element_by_xpath(".//a[@class='f-fc9']").text
ccount = div.find_element_by_xpath(".//span[@class='hot']").text
except Exception as err:
print(err)
print("爬取失败1")
try:
self.driver.execute_script("arguments[0].click();",div.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']"))
# 新打开课程详情页面
self.driver.switch_to.window(self.driver.window_handles[-1])
time.sleep(2)
cprocess = self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']/span[2]").text
cbrief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
cteam = self.driver.find_elements_by_xpath("//h3[@class='f-fc3']")
cTeam = ""
for t in cteam:
cTeam += " " + t.text
# 关闭新页面,返回原来的页面
self.driver.close()
self.driver.switch_to.window(self.driver.window_handles[0])
self.count += 1
id = self.count
try:
self.insertDB(id, ccourse, ccollege, cteacher, cTeam, ccount, cprocess, cbrief)
except Exception as err:
print(err)
print("插入失败")
except Exception as err:
print(err)
print("爬取失败2")
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/"
spider = MySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executeSpider(url, "python")
elif s == "2":
break
输出信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号