


详细介绍:【计算机毕业设计选题推荐】基于Hadoop+Spark的国内旅游景点游客数据分析系统完整实现 毕业设计 选题推荐 毕设选题 数据分析
✍✍计算机毕设指导师**
⭐⭐个人介绍:自己特别喜欢研究技术问题!专业做Java、Python、小软件、安卓、大数据、爬虫、Golang、大屏等实战项目。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
通过⚡⚡有什么问题能够在主页上或文末下联系咨询博客~~
⚡⚡Java、Python、小程序、大数据实战工程集](https://blog.csdn.net/2301_80395604/category_12487856.html)
⚡⚡文末获取源码
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
国内旅游景点游客数据分析系统-简介
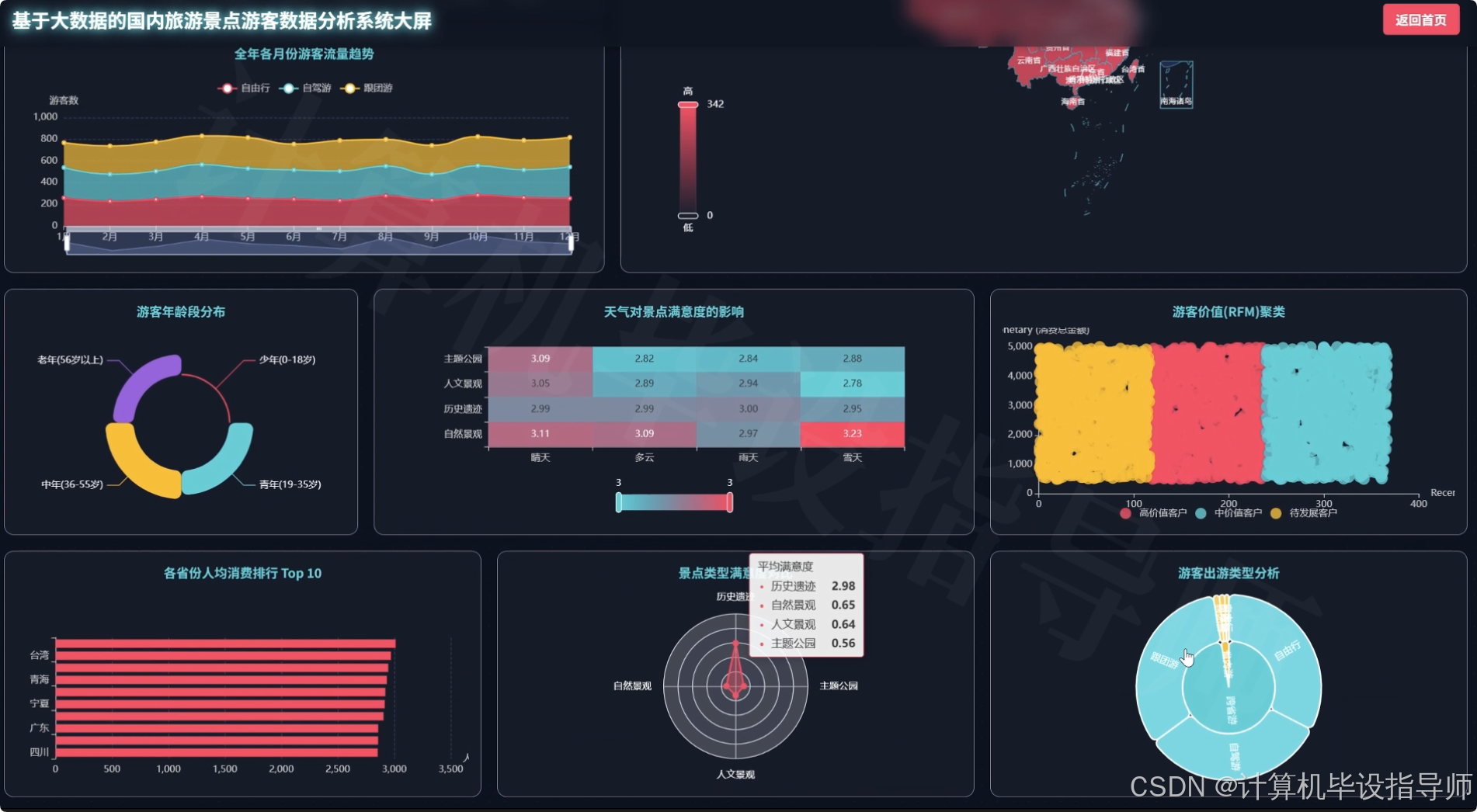
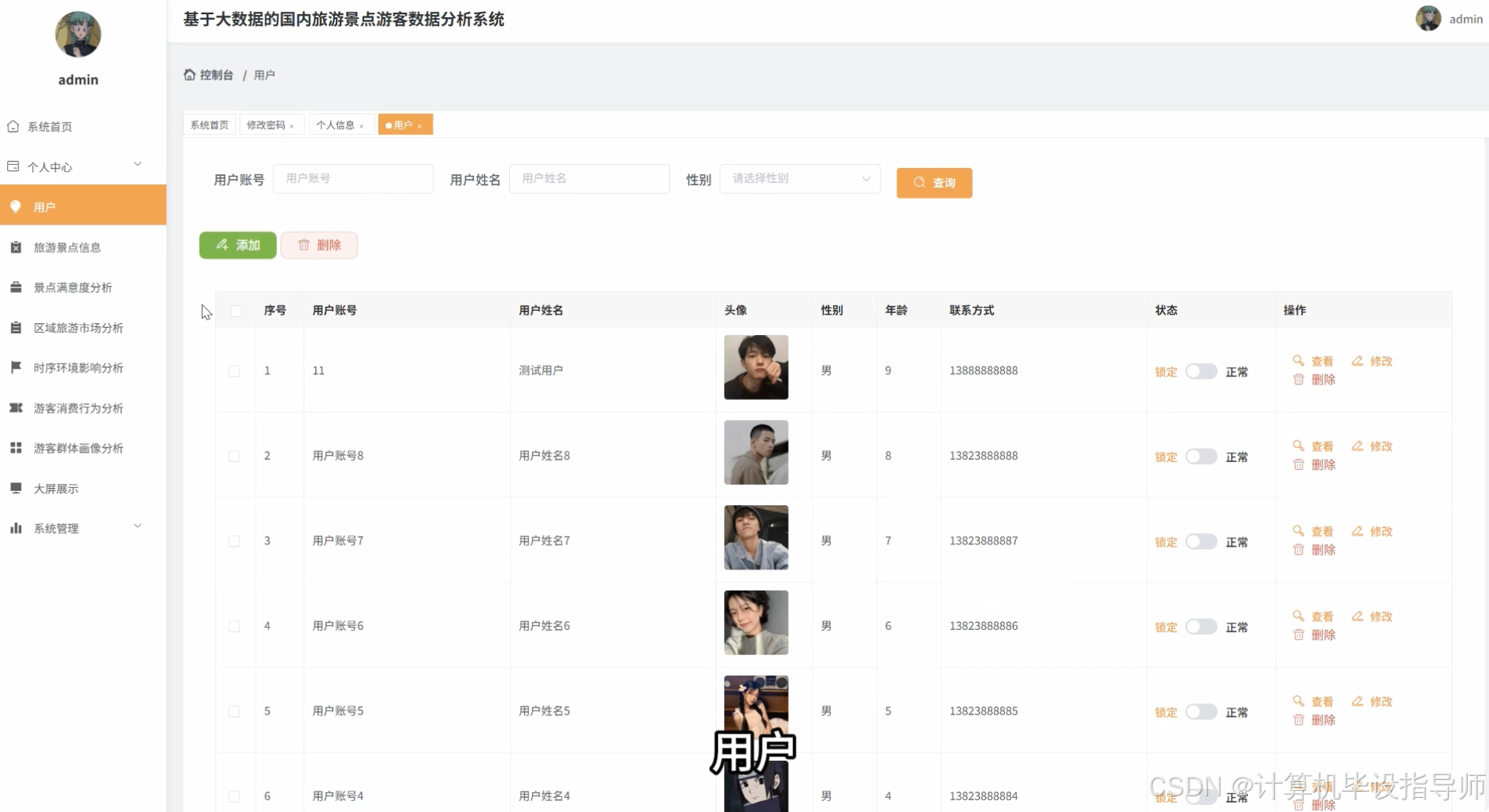
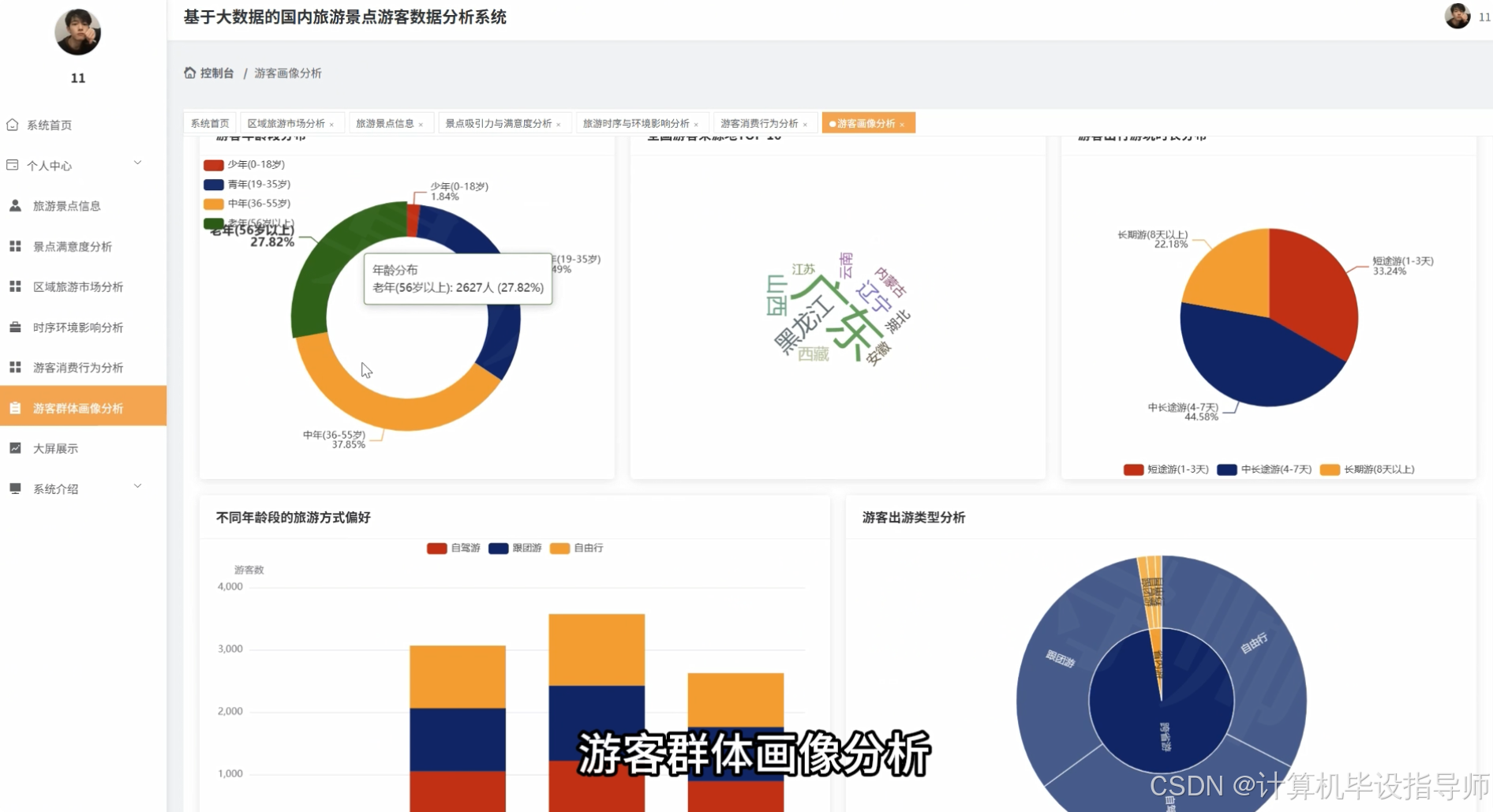
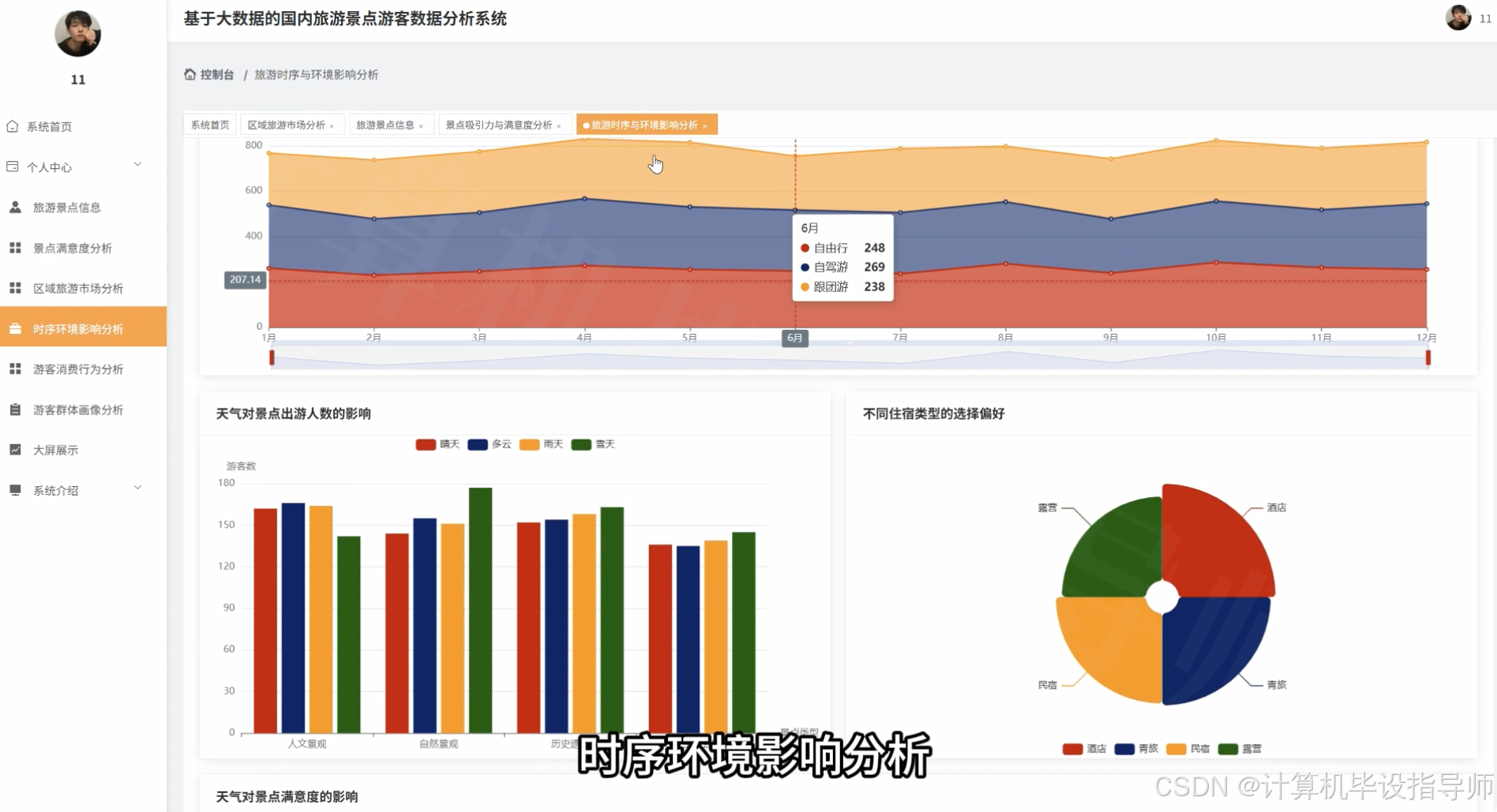
本系统是一套面向国内旅游行业的大数据分析平台,采用Hadoop分布式存储框架结合Django Web开发框架构建而成。系统通过HDFS存储海量旅游景点游客数据,利用Spark和Spark SQL进行高效的数据清洗、转换和分析计算,前端采用Vue+ElementUI+Echarts技术栈实现数据可视化呈现。系统核心功能涵盖游客多维画像分析、旅游消费行为分析、景点吸引力与满意度分析、旅游时序与环境影响分析以及全国区域旅游市场格局分析五大模块,共计23项具体分析维度。通过对游客年龄段、性别、客源地、旅游方式、消费水平、景点类型、满意度评分、天气状况、住宿类型等多维度资料进行深度挖掘,系统能够生成游客来源地TOP10排行、热门景点销量榜单、各省份旅游热力图、月度游客流量趋势、游客价值聚类等30余种可视化图表,为旅游管理部门、景区运营方和旅游企业提供全面的数据决策支持,帮助其优化资源配置、制定精准营销策略和提升服务质量。
国内旅游景点游客数据分析系统-技术
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
创建语言:Python+Java(两个版本都协助)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
数据库:MySQL
国内旅游景点游客数据分析系统-背景
选题背景
本平台开发的现实需求所在。就是近年来国内旅游产业快速发展,各类旅游景点每年接待的游客数量呈现持续增长态势,随之产生的游客行为数据、消费数据、评价内容也呈现出爆发式增长的特点。这些数据蕴含着游客的出行偏好、消费习惯、满意度反馈等宝贵信息,但传统的数据库系统在面对TB级甚至PB级的海量旅游数据时,往往会遇到存储瓶颈和计算性能不足的挑战。与此同时,旅游管理部门和景区运营方迫切需要从这些庞杂的数据中挖掘出有价值的信息,比如哪些地区是核心客源市场、不同年龄段游客的消费能力差异、哪些景点类型更受欢迎、天气变化对游客出行的影响程度等,用于指导旅游产品设计、营销渠道选择和服务质量改进。在这样的背景下,如何利用大数据科技高效地存储、处理和分析海量旅游数据,并将分析结果以直观的可视化形式呈现出来,成为旅游行业信息化建设的重要课题,也
选题意义
本系统的开发具有多方面的实际意义。从技术层面来看,系统经过引入Hadoop分布式存储框架和Spark计算引擎,能够较好地解决传统单机数据库在处理大规模旅游内容时的性能瓶颈,通过HDFS实现资料的分布式存储,利用Spark SQL进行并行化的数据分析计算,为海量数据的高效处理提供了一种可行的技能方案。从应用层面来讲,系统设计的23项数据分析维度覆盖了游客画像、消费行为、景点评价、时间规律、区域分布等多个方面,能够帮助旅游从业者更全面地了解市场现状和游客需求。比如借助分析客源地分布可以明确重点营销区域,依据对比不同年龄段的旅游方式偏好许可设计更有针对性的旅游产品,通过监测各月份游客流量趋势可以提前做好淡旺季的资源调配。另外,框架采用Vue+Echarts实现的数据可视化效果,能够将复杂的分析结果转化为直观易懂的图表形式,降低了数据解读的门槛。作为一个毕业设计方案,本系统的开发也是对大数据技术栈的一次实践应用,能够加深对Hadoop生态组件、Spark分布式计算、Django Web开发等技术的理解和掌握。
国内旅游景点游客数据分析系统-视频展示
【普通数据库vs大内容框架】国内旅游景点游客数据分析系统用Hadoop+Django轻松拿优 毕业设计 选题推荐 毕设选题 数据分析
国内旅游景点游客数据分析系统-图片展示








国内旅游景点游客数据分析系统-代码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, sum, when, dense_rank, desc, year, month, dayofmonth
from pyspark.sql.window import Window
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
from django.http import JsonResponse
from django.views import View
spark = SparkSession.builder.appName("TourismDataAnalysis").master("local[*]").config("spark.sql.shuffle.partitions", "4").config("spark.driver.memory", "2g").getOrCreate()
class VisitorSourceAnalysisView(View):
def get(self, request):
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/tourism_db").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "visitor_records").option("user", "root").option("password", "123456").load()
df.createOrReplaceTempView("visitor_data")
province_stats = spark.sql("SELECT source_province, COUNT(*) as visitor_count, AVG(consumption_amount) as avg_consumption FROM visitor_data GROUP BY source_province ORDER BY visitor_count DESC LIMIT 10")
province_list = province_stats.collect()
result_data = []
for row in province_list:
province_name = row['source_province']
visitor_num = row['visitor_count']
avg_consume = round(row['avg_consumption'], 2)
result_data.append({'province': province_name, 'count': visitor_num, 'avgConsumption': avg_consume})
gender_analysis = df.groupBy('source_province').agg(count(when(col('visitor_gender') == '男', 1)).alias('male_count'),count(when(col('visitor_gender') == '女', 1)).alias('female_count'))
gender_list = gender_analysis.collect()
gender_ratio_data = []
for item in gender_list:
total = item['male_count'] + item['female_count']
if total > 0:
male_ratio = round((item['male_count'] / total) * 100, 2)
female_ratio = round((item['female_count'] / total) * 100, 2)
gender_ratio_data.append({'province': item['source_province'],'maleRatio': male_ratio,'femaleRatio': female_ratio})
age_distribution = df.withColumn('age_group',when(col('visitor_age') < 25, '青年').when((col('visitor_age') >= 25) & (col('visitor_age') < 45), '中年').otherwise('老年'))
age_stats = age_distribution.groupBy('age_group').agg(count('*').alias('count'),avg('consumption_amount').alias('avg_consumption'))
age_result = age_stats.collect()
age_data = []
for age_row in age_result:
age_data.append({'ageGroup': age_row['age_group'],'count': age_row['count'],'avgConsumption': round(age_row['avg_consumption'], 2)})
return JsonResponse({'status': 'success','provinceRank': result_data,'genderRatio': gender_ratio_data,'ageDistribution': age_data})
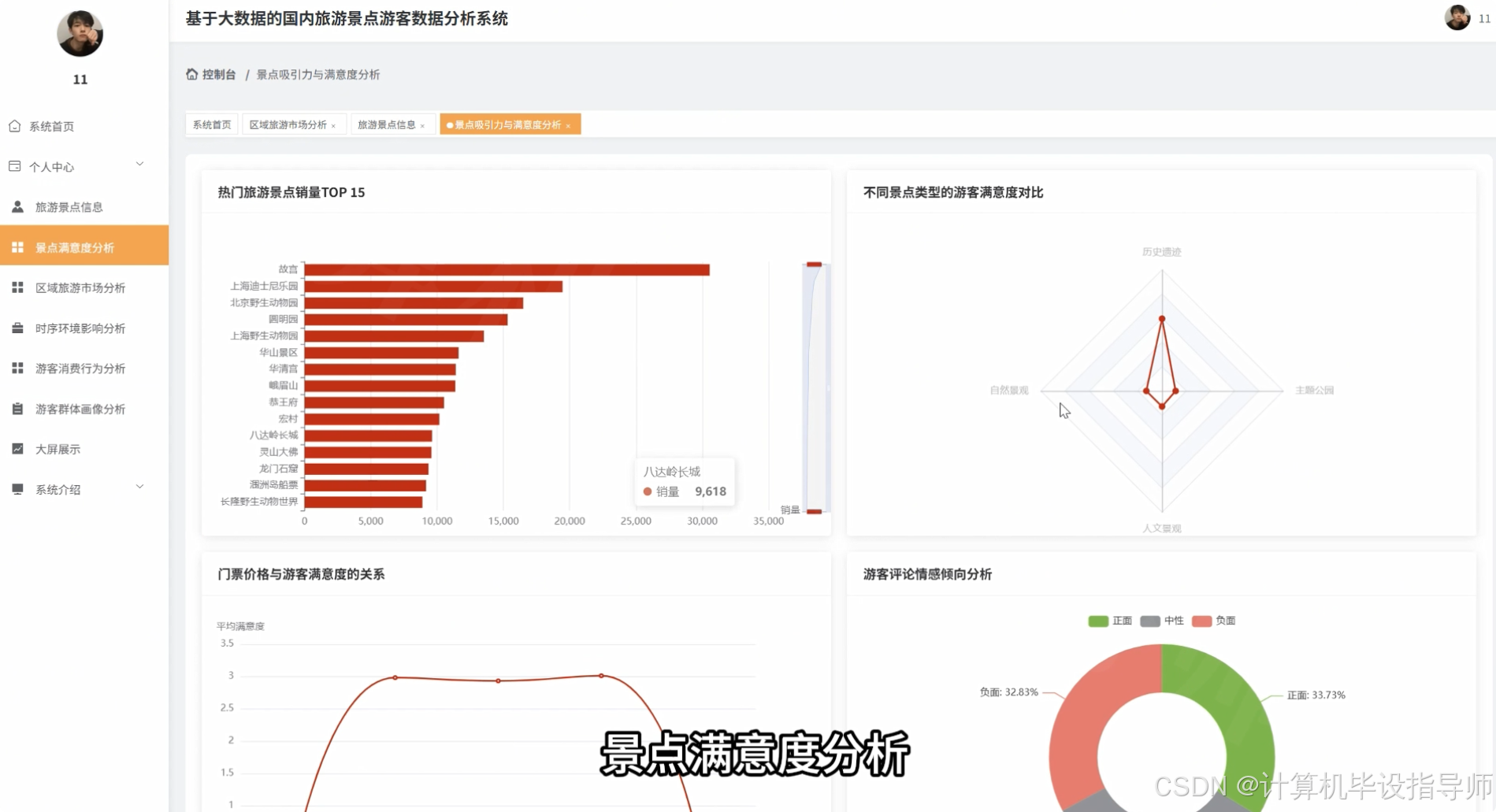
class AttractionSatisfactionAnalysisView(View):
def get(self, request):
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/tourism_db").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "visitor_records").option("user", "root").option("password", "123456").load()
df.createOrReplaceTempView("attraction_data")
sales_ranking = spark.sql("SELECT attraction_name, attraction_type, SUM(attraction_sales) as total_sales, AVG(satisfaction_score) as avg_score FROM attraction_data GROUP BY attraction_name, attraction_type ORDER BY total_sales DESC LIMIT 15")
sales_list = sales_ranking.collect()
sales_result = []
for rank_idx, sales_row in enumerate(sales_list, 1):
sales_result.append({'rank': rank_idx,'attractionName': sales_row['attraction_name'],'attractionType': sales_row['attraction_type'],'totalSales': sales_row['total_sales'],'avgScore': round(sales_row['avg_score'], 2)})
type_satisfaction = df.groupBy('attraction_type').agg(avg('satisfaction_score').alias('avg_satisfaction'),count('*').alias('visitor_count'))
type_list = type_satisfaction.collect()
type_result = []
for type_row in type_list:
type_result.append({'type': type_row['attraction_type'],'avgSatisfaction': round(type_row['avg_satisfaction'], 2),'visitorCount': type_row['visitor_count']})
price_satisfaction_df = df.select('ticket_price', 'satisfaction_score').filter(col('ticket_price').isNotNull())
price_satisfaction_df = price_satisfaction_df.withColumn('price_level',when(col('ticket_price') < 50, '低价').when((col('ticket_price') >= 50) & (col('ticket_price') < 150), '中价').otherwise('高价'))
price_stats = price_satisfaction_df.groupBy('price_level').agg(avg('satisfaction_score').alias('avg_score'),count('*').alias('count'))
price_list = price_stats.collect()
price_result = []
for price_row in price_list:
price_result.append({'priceLevel': price_row['price_level'],'avgScore': round(price_row['avg_score'], 2),'count': price_row['count']})
rating_satisfaction = df.groupBy('attraction_rating').agg(avg('satisfaction_score').alias('avg_satisfaction'),count('*').alias('count')).orderBy(desc('attraction_rating'))
rating_list = rating_satisfaction.collect()
rating_result = []
for rating_row in rating_list:
rating_result.append({'rating': rating_row['attraction_rating'],'avgSatisfaction': round(rating_row['avg_satisfaction'], 2),'count': rating_row['count']})
sentiment_distribution = df.groupBy('sentiment_polarity').agg(count('*').alias('count'))
sentiment_list = sentiment_distribution.collect()
sentiment_result = []
total_sentiment = sum([s['count'] for s in sentiment_list])
for sentiment_row in sentiment_list:
percentage = round((sentiment_row['count'] / total_sentiment) * 100, 2)
sentiment_result.append({'sentiment': sentiment_row['sentiment_polarity'],'count': sentiment_row['count'],'percentage': percentage})
return JsonResponse({'status': 'success','salesRanking': sales_result,'typeSatisfaction': type_result,'priceSatisfaction': price_result,'ratingSatisfaction': rating_result,'sentimentDistribution': sentiment_result})
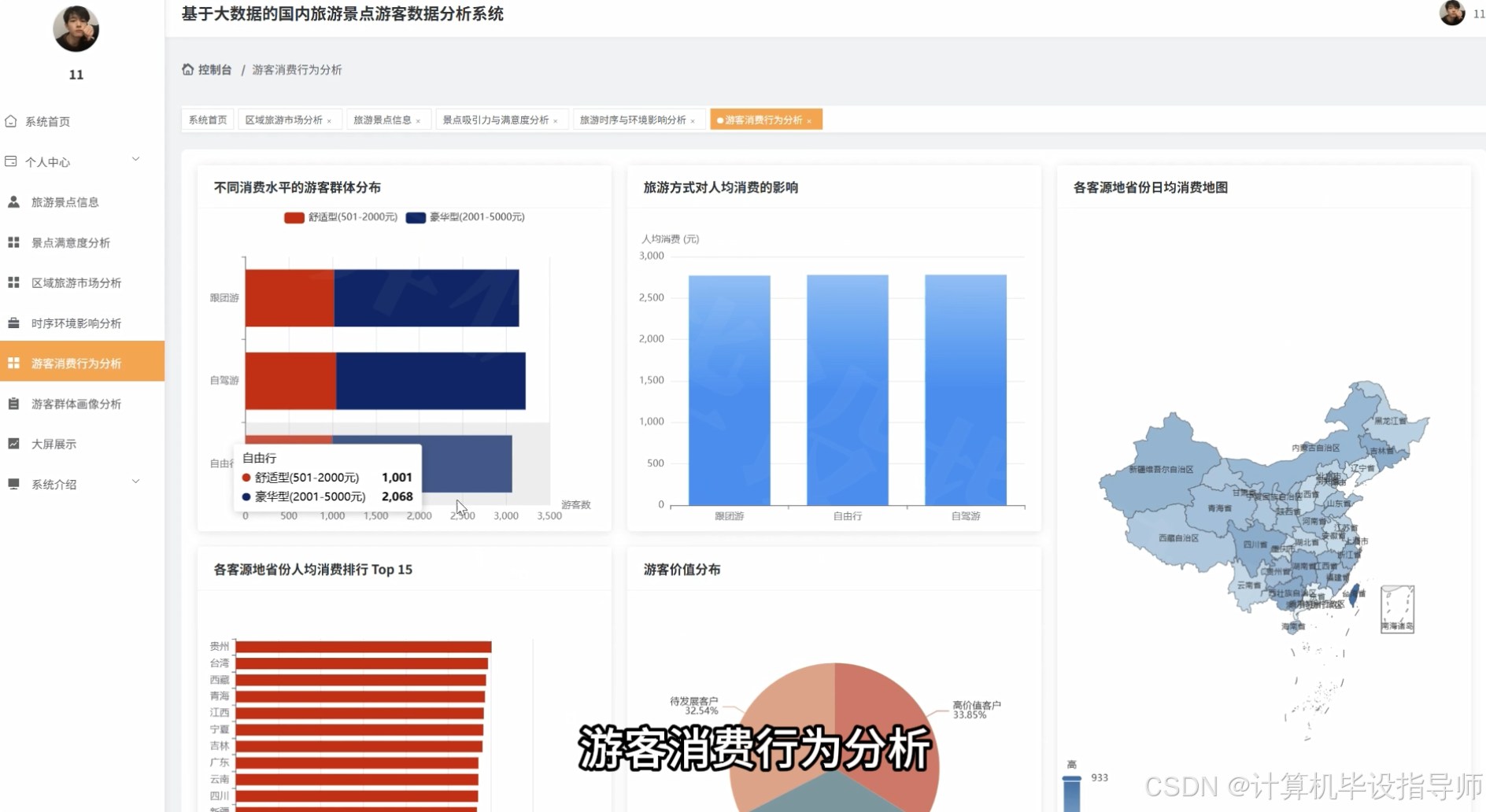
class VisitorValueClusteringView(View):
def post(self, request):
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/tourism_db").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "visitor_records").option("user", "root").option("password", "123456").load()
df.createOrReplaceTempView("clustering_data")
rfm_df = spark.sql("SELECT visitor_id, MAX(play_date) as last_visit, COUNT(*) as frequency, SUM(consumption_amount) as monetary FROM clustering_data GROUP BY visitor_id")
from datetime import datetime
current_date = datetime.now()
rfm_pandas = rfm_df.toPandas()
rfm_pandas['last_visit'] = pd.to_datetime(rfm_pandas['last_visit'])
rfm_pandas['recency'] = (current_date - rfm_pandas['last_visit']).dt.days
rfm_features = rfm_pandas[['recency', 'frequency', 'monetary']].fillna(0)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
rfm_scaled = scaler.fit_transform(rfm_features)
kmeans = KMeans(n_clusters=3, random_state=42, max_iter=300)
rfm_pandas['cluster'] = kmeans.fit_predict(rfm_scaled)
cluster_analysis = rfm_pandas.groupby('cluster').agg({'visitor_id': 'count','recency': 'mean','frequency': 'mean','monetary': 'mean'}).reset_index()
cluster_analysis.columns = ['cluster', 'visitor_count', 'avg_recency', 'avg_frequency', 'avg_monetary']
cluster_analysis['avg_recency'] = cluster_analysis['avg_recency'].round(2)
cluster_analysis['avg_frequency'] = cluster_analysis['avg_frequency'].round(2)
cluster_analysis['avg_monetary'] = cluster_analysis['avg_monetary'].round(2)
cluster_result = []
for idx, row in cluster_analysis.iterrows():
if row['avg_monetary'] > cluster_analysis['avg_monetary'].mean() and row['avg_frequency'] > cluster_analysis['avg_frequency'].mean():
cluster_label = '高价值客户'
elif row['avg_monetary'] < cluster_analysis['avg_monetary'].mean() and row['avg_frequency'] < cluster_analysis['avg_frequency'].mean():
cluster_label = '低价值客户'
else:
cluster_label = '中价值客户'
cluster_result.append({'cluster': int(row['cluster']),'label': cluster_label,'visitorCount': int(row['visitor_count']),'avgRecency': float(row['avg_recency']),'avgFrequency': float(row['avg_frequency']),'avgMonetary': float(row['avg_monetary'])})
visitor_detail = rfm_pandas[['visitor_id', 'cluster', 'recency', 'frequency', 'monetary']].to_dict('records')
for visitor in visitor_detail:
cluster_id = visitor['cluster']
matching_cluster = next((c for c in cluster_result if c['cluster'] == cluster_id), None)
if matching_cluster:
visitor['clusterLabel'] = matching_cluster['label']
return JsonResponse({'status': 'success','clusterAnalysis': cluster_result,'visitorDetail': visitor_detail[:100]})国内旅游景点游客数据分析系统-结语
2026年85%导师认可的大数据毕设:基于Hadoop+Spark的国内旅游景点游客数据分析系统
还在为大数据毕设发愁?Hadoop+Django建立国内旅游景点游客数据分析系统全套源码拯救你
大学导师最推荐的大数据毕设:基于Hadoop+Spark的国内旅游景点游客数据分析系统详解
感谢大家点赞、收藏、投币+关注,如果遇到有技术挑战或者获取源代码,欢迎在评论区一起交流探讨!
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡如果遇到具体的技巧问题或其他需求,你也可能问我,我会尽力帮你分析和解决问题所在,支持我记得一键三连,再点个关注,学习不迷路!~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号