生成器、自定义range方法、模块介绍
 学习内容总结
学习内容总结
今日学习内容总结
在昨日的学习中,我们通过对迭代器,迭代器对象,可迭代对象的了解,加长异常处理的实际操作。成功理解了for循环的本质。今天就让我们来学习生成器,以及模块的导入与使用。
生成器对象
生成器对象,本质还是迭代器。生成器函数是指在函数体中使用yield表达式仅返回结果的函数。yield表达式仅在定义生成器函数时使用,因此只能用在函数定义的主体中。在函数体中使用yield表达式会使该函数成为生成器函数。当生成器函数被调用时,它返回一个称为生成器的迭代器,该迭代器由python自动生成。然后,生成器控制了生成器函数的执行。因为返回的生成器是一个迭代器,所以生成器函数的执行结果也就可以被循环。当生成器的的__next__方法被调用时,生成器函数的函数体内的语句开始执行,执行进行到第一个yield表达式时,立即将yield表达式的结果返回给生成器的调用者,同时将生成器函数内部的状态挂起。即保持生成器函数的执行进度,和生成器函数内的局部状态:包括局部变量的当前绑定,指令指针,内部计算栈和任何异常处理的状态。当生成器的再次调用__next__方法来时,生成器函数恢复执行,并再次执行到yield表达式返回结果再保持状态,直到无法再执行到yield表达式。此时生成器自动抛出StopIteration异常。
# 我们先定义一个简单生成器函数,函数功能返回数字0-9的平方数
def squares():
for i in range(10):
yield i ** 2
g = squares()
print(squares) # <function squares at 0x000001B034A51EA0>
print(g) # <generator object squares at 0x000001B034B90CA8>
# 从上面可以看出变量squares是函数类型,变量g是generator类型对象,generator从字面的理解上就是生成器类型。
for i in g:
print(i)
# 这就实现了我们0-9的平方数的功能
生成器对象也是节省存储空间的,特性与迭代器对象一致。但是在其没有调用前,就是一个普通的函数。如果函数体代码中含有多个yield关键字,执行一次__next__返回后面的值并且让代码停留在yield位置,再次执行__next__基于上次的位置继续往后执行到下一个yield关键字处,如果没有了再执行也会报错StopIteration
自定义range方法
range方法其实是一个可迭代对象。课堂练习:
# 通过生成器模拟range方法
def my_rangge(i, j = None, x = 1):
if not j:
j = i
i = 0
while i < j:
yield i
i += x
for i in my_rangge(1, 10, 2):
print(i)
# 写代码的时候一定要记住鸡哥说的写代码不要想太多,先搭建主体功能,之后再考虑其他情况。
yield关键字作用
yield关键字作用:1.在函数体代码中出现,可以将函数变成生成器。2.在执行过程中,可以将后面的值返回出去,类似于return。3.可以暂停代码的运行。4.可以接收外界的传值。
# yield 的使用和 return 很像,不同的是 yield 会返回一个生成器。
def squares():
a = range(3)
for i in a:
yield i*i
res = squares()
print(res) # <generator object squares at 0x000001EC183B0CA8>
for i in res:
print(i) # 0 1 4
上面例子中,调用 squares() 返回的是一个生成器,需要对生成器 res进行遍历,才能得到值。对生成器进行第一遍遍历时,会执行 squares() 函数中的代码直到 yield i*i,这时会返回第一个值,紧接着第二遍遍历会返回第二个值,直到生成器为空。
生成器表达式
生成器表达的作用式也是为了节省存储空间。在后期做代码优化时考虑使用。
res = (i for i in 'jason')
print(res) # <generator object <genexpr> at 0x000002440A5B0CA8>
print(res.__next__()) # j
print(res.__next__()) # a
print(res.__next__()) # s
生成器内部的代码只有在调用__next__迭代取值的时候才会执行
模块
模块简介
模块,简而言之,在python中,一个文件(以“.py”为后缀名的文件)就叫做一个模块,每一个模块在python里都被看做是一个独立的文件。模块让你能够有逻辑地组织你的 Python 代码段。把相关的代码分配到一个模块里能让你的代码更好用,更易懂。模块能定义函数,类和变量,模块里也能包含可执行的代码。一个模块编写完毕之后,其他模块直接调用,不用再从零开始写代码了,节约了工作时间;避免函数名称和变量名称重复,在不同的模块中可以存在相同名字的函数名和变量名,但是,切记,不要和系统内置的模块名称重复。
而python之所以牛逼,并且适用于各个行业,很大程度上就是因为模块。很多大佬写了很多非常牛逼的模块 供python工程师直接使用,而我们在未来需要一个非常复杂的功能需要实现的时候,那么第一时间不是想着如何去写,而是去网上找有没有相应的python模块!!!
模块的三种来源:1.内置的(python解释器自带)。2.第三方的(别人写的)。3.自定义的(我们自己写的)。
模块的四种表现形式:1.使用python编写的py文件(也就意味着py文件也可以称之为模块:一个py文件也可以称之为一个模块)。2.已被编译为共享库或DLL的C或C++扩展。3.把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py文件,该文件夹称之为包)包:一系列py文件的结合体。4.使用C编写并连接到python解释器的内置模块。
使用模块的原因:1.用别人写好的模块(内置的,第三方的):典型的拿来主义,极大的提高开发效率。2.使用自己写的模块(自定义的):当程序比较庞大的时候,你的项目不可能只在一个py中那么当多个文件中都需要使用相同的方法的时候 可以将该公共的方法写到一个py文件中其他的文件以模块的形式导过去直接调用即可。
模块的导入方式
要想使用模块,必须先导入。而我们导入模块的方式有两种:
导入方式一
# import + 句式
在研究模块的时候,一定要分清楚谁是执行文件 谁是被导入文件(模块)。
import句式的特点:1.可以通过import后面的模块名点的方式,使用模块中所有的名字。2.并且不会与当前名称空间中的名字冲突(指名道姓)。
import a # a里面有一个money=1
money = 666
a.change()
print(money) # 666

由上图知,我们a.py和b.py中都有方法1,但是并不会冲突,而我们在b中运行模块a后,会产生这个文件的全局名称空间,执行import句式就会执行a.py里面的代码,指向这个文件对应的名称空间。而我们通过a.方法的方式,就可以使用模块名称空间中的名字。
导入方式二
# from ... import ...
from a import money
print(money) # 1
money = 666
print(money) # 666
print(name) # 报错 from a import money 只使用模块中的money名字
from...import的句式会产生名字冲突的问题,在使用的时候 一定要避免名字冲突。使用from...import的句式,只能使用import后面出现的名字。
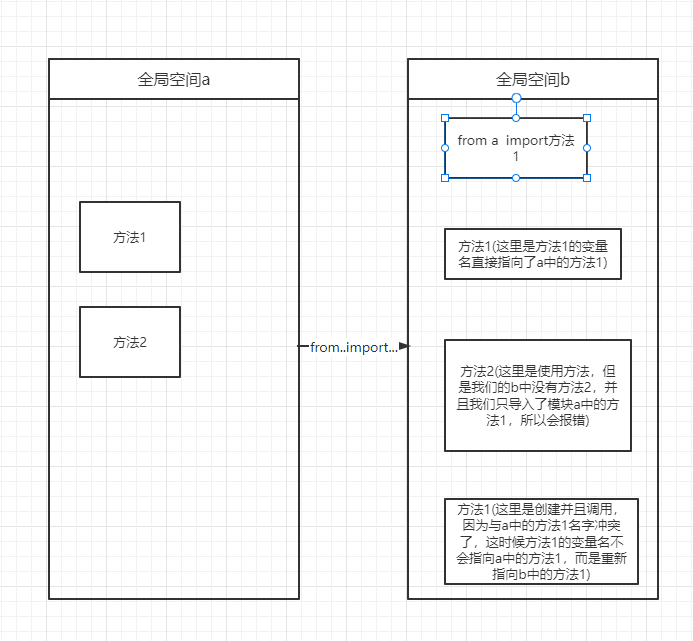
图中详细说明了from方法的使用原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号