薪资预测模型
一、选题背景:
本题通过对职员薪资信息读取和可视化来展现职员薪资情况,并建立模型预测分析。
二、数据说明:
基于BOSS直聘上海地区岗位信息,利用爬虫对数据进行爬取和存储后,对其进行自然语言分析。
三、实施过程及代码:
#读取数据import pandas as pd from pandas import Series data_analysis = pd.read_csv('./data_to_be_analysed/data_analysis_with_skills.csv') data_mining = pd.read_csv('./data_to_be_analysed/data_mining_with_skills.csv') machine_learning = pd.read_csv('./data_to_be_analysed/machine_learning_with_skills.csv') business_analysis = pd.read_csv('./data_to_be_analysed/business_analysis_with_skills.csv') data_analysis.shape

#添加薪资均值
import re # 均值函数 def average(job_salary): # 取薪资均值---------------- pattern = re.compile('\d+') salary = job_salary try: res = re.findall(pattern, salary) avg_salary = 0 sum = 0 for i in res: a = int(i) sum = sum + a avg_salary = sum / 2 except Exception: avg_salary = 0 # 函数返回值 return avg_salary salary_list = [] for i in range(0,data_analysis.shape[0]): avg_sal = average(data_analysis['职位薪资'][i]) salary_list.append(avg_sal) sal = Series(salary_list) data_analysis.insert(9,'salary',sal) salary_list = [] for i in range(0,data_mining.shape[0]): avg_sal = average(data_mining['职位薪资'][i]) salary_list.append(avg_sal) sal = Series(salary_list) data_mining.insert(9,'salary',sal) salary_list = [] for i in range(0,machine_learning.shape[0]): avg_sal = average(machine_learning['职位薪资'][i]) salary_list.append(avg_sal) sal = Series(salary_list) machine_learning.insert(9,'salary',sal) salary_list = [] for i in range(0,business_analysis.shape[0]): avg_sal = average(business_analysis['职位薪资'][i]) salary_list.append(avg_sal) sal = Series(salary_list) business_analysis.insert(9,'salary',sal)
#薪资分布探索data_analysis.salary.describe()

ata_analysis.columns

%matplotlib inline import matplotlib.pyplot as plt data_analysis.salary.hist(bins=50, figsize=(8,5)) plt.show()
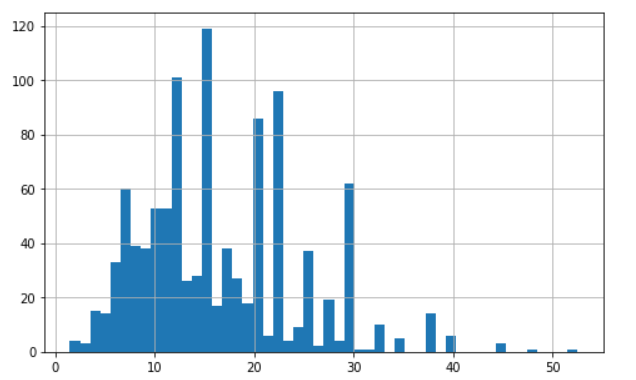
- 薪资主要分布在5k-30k之间
data_analysis[data_analysis.salary>30].shape

data_analysis[data_analysis.salary<5].shape

data_analysis = data_analysis[data_analysis['salary']<30] data_analysis = data_analysis[data_analysis['salary']>5]
data_analysis.head(2)
data_analysis = data_analysis.drop(['Unnamed: 0','Keyword','职位描述','职位薪资'],axis=1) data_mining = data_mining.drop(['Unnamed: 0','Keyword','职位描述','职位薪资'],axis=1) machine_learning = machine_learning.drop(['Unnamed: 0','Keyword','职位描述','职位薪资'],axis=1) business_analysis = business_analysis.drop(['Unnamed: 0','Keyword','职位描述','职位薪资'],axis=1)
#掌握的软件技能对薪资的影响关系
corr_matrix = data_analysis.corr() corr_matrix["salary"].sort_values(ascending=False)
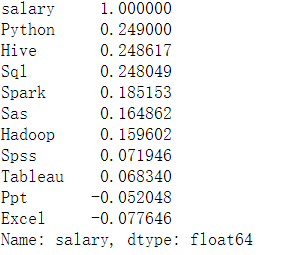
Data Analysis的职位中,Hive,Spark,Hadoop大数据应用方面的软件是薪资的加分项。同时,Python,SQL,SAS,Tableau,SPSS等统计分析软件与可视化软件也是数据分析师区别于低薪分析专员的因素。PPT,Excel作为必须的软件技能,对薪资变化并没有太大的影响,甚至仅仅会Excel的职位沦落为专员,会是一个减分项。结论:在数据分析领域,拥有大数据软件技能并且懂得Python这一编程语言的分析师的待遇较好。
corr_matrix = data_mining.corr() corr_matrix["salary"].sort_values(ascending=False)

Data Mining的职位中,Hive,Spark,Hadoop大数据方面的软件是薪资极大的加分项。Java,C,Python等编程语言对数据挖掘的工作有很大帮助因此也体现在了对薪资的正面影响上。分析结论:具备数据挖掘算法与编码能力且具备大数据方面分析技能的数据挖掘工程师的待遇较好。
corr_matrix = machine_learning.corr() corr_matrix["salary"].sort_values(ascending=False)

Machine Learning的职位中,没有特别突出的技能加分项,列表中的软件技能基本都是入职必备的技能。Hive,Spark,Hadoop等大数据方面的技能会对薪资有一定程度的提升,不过影响较小。分析结论:机器学习工程师入门难度稍高,需要掌握具备的软件技能也较多,没有特别突出的薪资加分项。
corr_matrix = business_analysis.corr() corr_matrix["salary"].sort_values(ascending=False)

Business Analysis的职位中,编程语言是极大的薪资加分项。如C,Python,Java。Excel,PPT,SPSS等软件是这个职位的必备技能,因此对职位薪资没有太大的影响。结论:在商业分析领域,拥有商业分析思维并且具有编程能力的分析师的待遇较好。
#准备数据
data_analysis.head(2)

from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(data_analysis, test_size=0.2, random_state=42) data_train = train_set.copy() data_test = test_set.copy() data_train.shape
data_test.shape

from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import Imputer from sklearn.compose import ColumnTransformer from sklearn.preprocessing import OneHotEncoder data_analysis.head(1)

data_analysis_num = data_analysis.drop(['公司名称','公司规模','地区','学历要求','工作经验','职位名称','融资情况','salary'], axis=1) num_attribs = list(data_analysis_num) cat_attribs = ['公司规模','学历要求','工作经验'] num_pipeline = Pipeline([ ('std_scaler', StandardScaler()), ]) full_pipeline = ColumnTransformer([ ("num", num_pipeline, num_attribs), ("cat", OneHotEncoder(), cat_attribs), ]) data_analysis_prepared = full_pipeline.fit_transform(data_train) data_analysis_test = full_pipeline.transform(data_test)
data_analysis_prepared[:1]

data_train.head(1)

data_analysis_labels = data_train.salary.values
test_labels = data_test.salary.values
#训练模型线性回归
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(data_analysis_prepared, data_analysis_labels)

from sklearn.metrics import mean_squared_error import numpy as np salary_predictions = lin_reg.predict(data_analysis_prepared) lin_mse = mean_squared_error(data_analysis_labels, salary_predictions) lin_rmse = np.sqrt(lin_mse) lin_rmse

#测试集
y_test = lin_reg.predict(data_analysis_test) y_test[:10]

test_labels[:10]

lin_mse = mean_squared_error(test_labels, y_test) lin_rmse = np.sqrt(lin_mse) lin_rmse

测试集上误差约为4.25
#变量重要性
feature_importances = grid_search.best_estimator_.feature_importances_ num_attribs = list(data_analysis_num) cat_attribs = ['公司规模','学历要求','工作经验'] # 变量重要性排序 attributes = num_attribs + cat_attribs sorted(zip(feature_importances, attributes), reverse=True)

公司规模对薪资的影响相比之下比较小。
#薪资预测final_predictions = final_model.predict(data_analysis_test) salary_test_series = Series(final_predictions,index=data_test.index) data_test_prediction = data_test.copy() data_test_prediction.insert(7,'prediction',salary_test_series) data_test_prediction.sample(3)
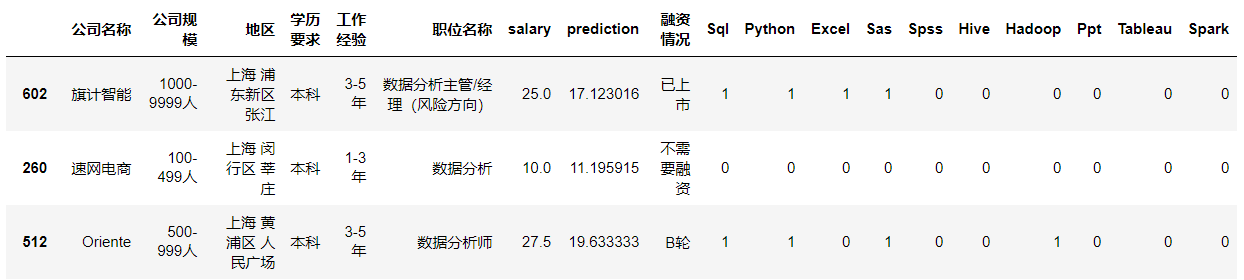
#预测函数接口data_test.head(1)

from pandas import DataFrame
#预测功能函数def prediction_function(scale,degree,experience,v_skills): predict_X = { '公司规模':[scale], '学历要求':[degree], '工作经验':[experience], 'Sql':[v_skills[0]], 'Python':[v_skills[1]], 'Excel':[v_skills[2]], 'Sas':[v_skills[3]], 'Spss':[v_skills[4]], 'Hive':[v_skills[5]], 'Hadoop':[v_skills[6]], 'Ppt':[v_skills[7]], 'Tableau':[v_skills[8]], 'Spark':[v_skills[9]], } predict_tmp = pd.DataFrame(predict_X) X_predict = full_pipeline.transform(predict_tmp) return X_predict
#技能转换函数def skills_switch(skill_list): tmp_list = [] skills = ['Sql','Python','Excel','Sas','Spss','Hive','Hadoop','Ppt','Tableau','Spark'] for skill in skills: # 大小写转换 if skill in skill_list: tmp_list.append(1) else: tmp_list.append(0) return tmp_list
#预测主函数def predict(scale,degree,experience,v_skills): X_predict = prediction_function(scale,degree,experience,v_skills) Y_predict = final_model.predict(X_predict) print('预测薪资为:',Y_predict[0],'k/month')

#预测函数#-----------设置变量 scale = '10000人以上' degree = '本科' experience = '1-3年' # ------------------ # --------设置所掌握的技能(顺序无关) mastered_skills = ['Sql','Python','Excel','Spss','Ppt'] v_skills = skills_switch(mastered_skills) # ----------------------------------- predict(scale,degree,experience,v_skills)
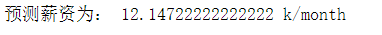
experiences = ['应届生','1年以内', '1-3年','3-5年', '5-10年' ] for exp in experiences: print(scale,'|',degree,'|',exp,'|',",".join(mastered_skills)) predict(scale,degree,exp,v_skills) print('-'*60)

#总结编写过程还有许多漏洞是自己无法解决处理的的,代码没有达到要求,也查不到问题所在通过这次作业才发现自己原来有这么多不足,知识点不全面,还有很大的提升空间,只有多写多看多用才能做到真正的掌握,有不懂的地方要及时解决虚心求教。
基于BOSS直聘上海地区岗位信息,利用爬虫对数据进行爬取和存储后,对其进行自然语言分析。提取“职位描述”中的软件技能,并建模预测分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号