万字Java进阶笔记总结
JavaApi
字符串
String
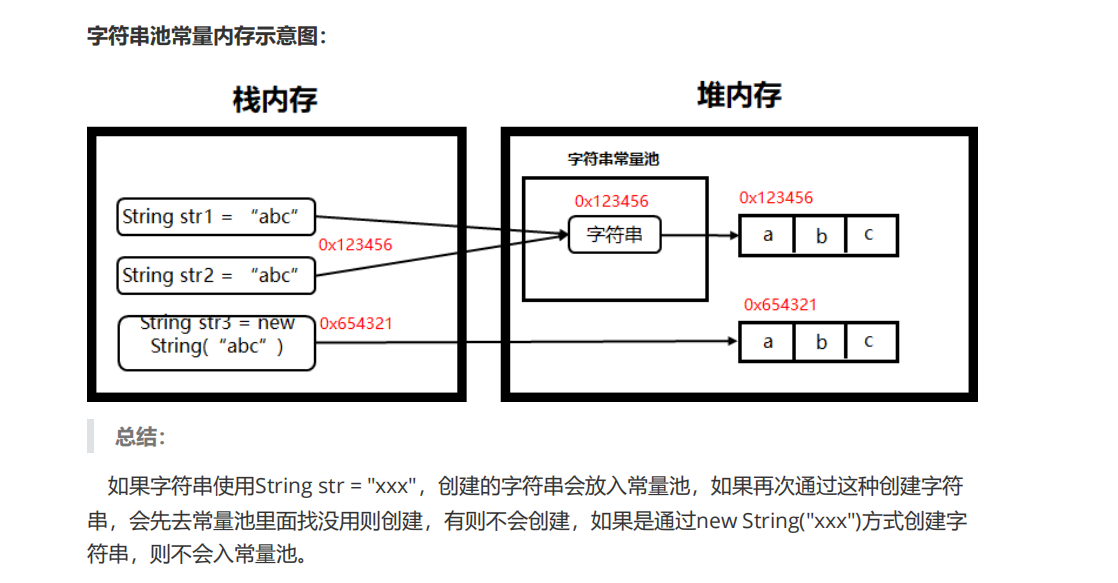
注意:Java中“==”操作符的作用:
- 基本数据类型:比较的是内容。
- 引用数据类型比较的是对象的内存地址。
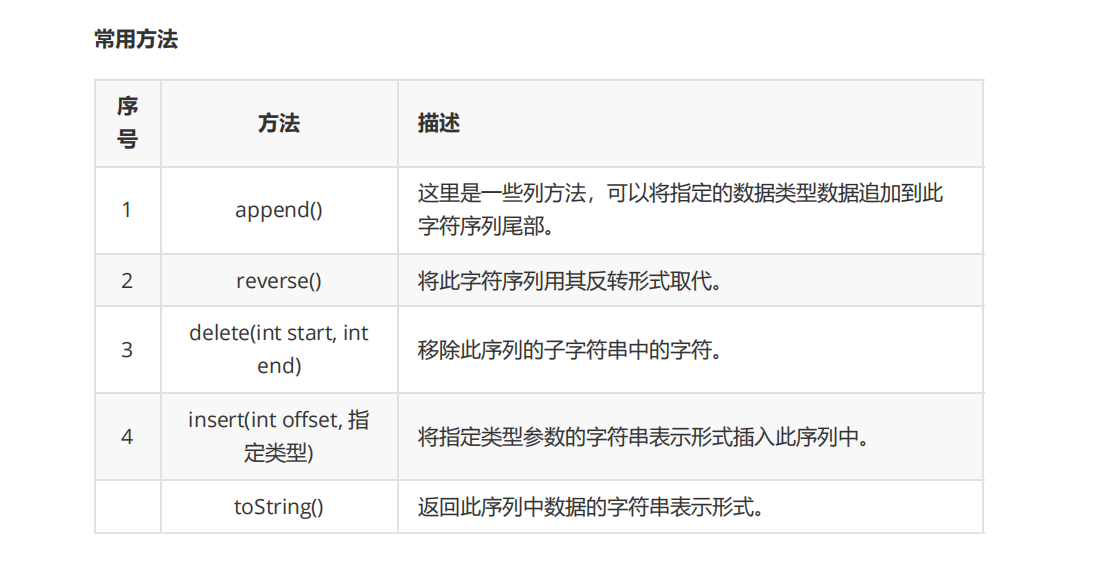
StringBuffer/StringBuilder
由于String是字符串是常量,它们的值在创建之后不能更改。如果我们使用这个String频繁进行操作,会有性能问题,这个时候就需要使用 StringBuffer 和 StringBuilder 类。
StringBuilder和StringBuffer之间的最大不同在于StringBuilder的方法不是线程安全的,
常用方法:
String/StringBuffer/StringBuilder的区别及效率
1、String、StringBuffer是JDK1里面就已经提供了,而StringBuilder是JDK1.5才提供。
2、String实现的是CharSequence接口,StringBuffer、StringBuilder不仅仅实现了CharSequence接口,还实现了Appendable接口。
3、String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,这样不仅效率低下,而且大量浪费有限的内存空间。如果频繁对字符串修改推荐使用StringBuffer 和StringBuilder 类。
4、StringBuffer是线程安全的,而StringBuilder是线程不安全的。在不考虑线程安全的情况下StringBuilder的运行效率比StringBuffer要高。
正则表达式
校验密码
密码规则为:6~12任意非空白字符
String regex = "^\\S{6,12}$";
测试年龄
年龄规则为:1,3位的数字
String regex = "^\\d{1,3}$";
或者
String regex = "^\\+?\\d{1,3}$";// 这里考虑前面加一个“+”的情况
测试手机号码
手机号码规则:以1开头长度为11位的数字
String regex = "^1\\d{10}$";
测试汉字
汉字的规则:汉字就是Unicode的一个范围。
String regex = "^[\u4E00-\u9FA5]+$";
测试EMAIL
email規則為:xx.xx@xx.xx
String regex = "^(\\w+\\.)?\\w+@\\w+\\.\\w+$";
时间与日期
Date
DateFormat
进阶
集合容器
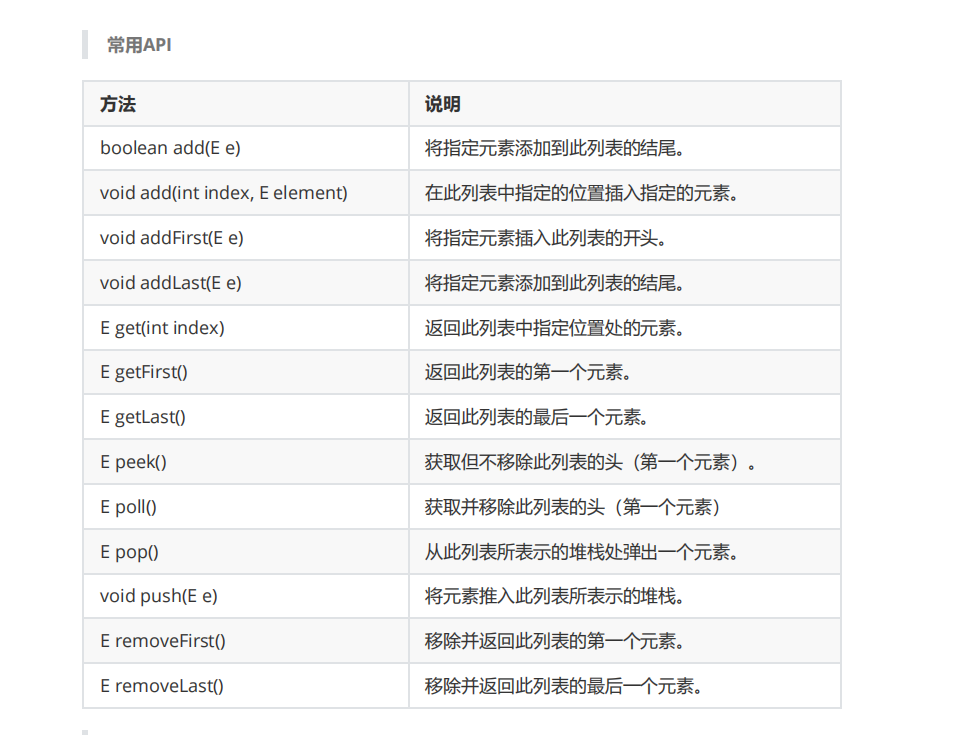
List
特点
-
有序: List中每个元素都有索引(下标)。可以根据元素的索引(在List中的位置)访问元素
-
可重复: List允许加入重复的元素。更确切地讲,List通常允许满足 a.equals(b) 的元素重复
加入容器
与顺序相关的方法
| 方法 | 说明 |
|---|---|
| void add(int index, element) | 在列表的指定位置插入指定元素,以前的元素全部后退一E位。 |
| E set(int index, E element) | 用指定元素替换列表中指定位置的元素 |
| E get(int index) | 返回列表中指定位置的元素。 |
| int indexOf(Object o) | 返回第一个匹配的元素,没用返回-1 |
| int lastIndexOf(Object o) | 返回最后一个匹配的元素,没用返回-1 |
与集合之间操作的方法:
| 方法 | 说明 |
|---|---|
| boolean addAll(Collection c) | 添加指定 collection 中的所有元素到此列表的结尾 |
| boolean removeAll(Collection) | 从列表中移除指定 collection 中包含的其所有元素。 |
| boolean retainAll(Collection c) | 仅在列表中保留指定 collection 中所包含的元素(可选操作)。换句话说,该方法从列表中移除未包含在指定 collection 中的所 |
ArrayList
特点
- 底层是数组实现的,但是他可以随时扩容
- 数组的访问效率高, 但是增删效率低
- 线程不安全
Vector
采用synchronized锁加了同步检测,线程安全
但效率低于arraylist
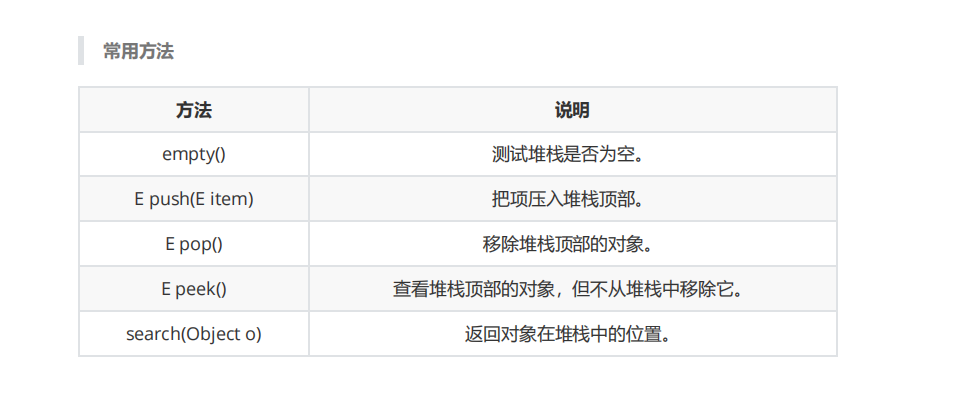
stack
LinkedList
底层用双向链表实现的存储
特点:查询效率低,但是增删效率高,然后就是线程不安全。
总结:
ArrayList、LinkedLis、Vector怎么选择
- t多用ArrayList(使用率最高)。
- 不存在线程安全问题时,增加或删除元素较多用LinkedList。
- 如果程序需要线程安全时,用Vector。
Set
Set容器特点:无序、不可重复。无序指Set不像List那样可以根据索引找到对应的元素,我们只能遍历查找;不可重复指不允许加入重复的元素。更确切地讲,新元素如果和Set中某个元素通过equals()方法对比为true,则不能加入;甚至,Set中也只能存入一个null元素。
HashSet
HashSet是采用哈希算法实现,底层实际是用HashMap实现的(HashSet本质就是一个简化版的HashMap),因此,查询效率和增删效率都比较高。或者这么说:“HashSet其实就是使用HashMap的键来实现对的。”
Map
HashMap
特点
-
HashMap 是一个散列表,它存储的内容是
键值对(key-value)映射。 -
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,
最多允许一条记录的键为null,不支持线程同步。 -
HashMap 是
无序的,即不会记录插入的顺序。 -
HashMap
继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。 -
HashMap与HashSet的渊源:
- HashSet的底层使用HashMap实现。HashSet的add()使用的是
- HashMap的key来进行保存的。
常用方法
方法 |
功能 |
|---|---|
| get(key) | 获取key对应的value |
| put() | 添加键值对 |
| remove(key) | 删除key对应的键值对 |
| clear() | 删除所有的键值对 |
| size() | 计算HashMap中的元素数量 |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
更多方法: 传送门
迭代方式
public class HashMapTest {
public static void main(String[] args) {
Map<String, Integer> mapTest = new HashMap<>();
mapTest.put("foo", 1);
mapTest.put("bar", 2);
mapTest.put("baz", 3);
mapTest.put("asd", 4);
mapTest.put("add", 5);
}
// iterateUsingEntrySet 使用entrySet()方法会返回一个包含map中所有键值对的集合视图,每个键值对都是Map.Entry类的对象。可以使用for-each循环遍历这个集合,然后用entry.getKey()和entry.getValue()分别获取键和值。例如:
public static void iterateUsingEntrySet(Map<String, Integer> map) {
for (Map.Entry<String, Integer> test : map.entrySet() ) {
System.out.println(test.getKey()+" --> "+test.getValue());
}
}
// iterateUsingKeySet 使用keySet()方法会返回一个包含map中所有键的集合视图。可以使用for-each循环遍历这个集合,然后用map.get(key)根据键获取对应的值。例如:
public static void iterateUsingKeySet(Map<String, Integer> map) {
for (String test : map.keySet()) {
System.out.println(test+" --> "+map.get(test));
}
}
// iterateUsingIteratorAndEntryWhile 使用Iterator对象来遍历map中的键值对,这样可以在迭代过程中删除元素,避免出现并发修改异常。你可以用entrySet().iterator()或者keySet().iterator()来获取Iterator对象,然后用hasNext()和next()方法来进行迭代。例如:
public static void iterateUsingIteratorAndEntryWhile(Map<String, Integer> map) {
Iterator<Map.Entry<String, Integer>> test = map.entrySet().iterator();
while (test.hasNext()) {
Map.Entry<String, Integer> temp = test.next();
System.out.println(temp.getKey() +"--> "+ temp.getValue());
}
}
// iterateUsingIteratorAndEntryFor
public static void iterateUsingIteratorAndEntryFor(Map<String, Integer> map) {
for (Iterator<Map.Entry<String, Integer>> test = map.entrySet().iterator(); test.hasNext();) {
Map.Entry<String, Integer> temp = test.next();
System.out.println(temp.getKey()+" --> "+ temp.getValue());
// test.remove()来删除当前元素
}
}
}
HashTable
Hashtable 键和值都不能为空,这一点与HashMap是不一样的。
TreeMap
有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意SortedMap是接口,它的实现类是TreeMap。SortedMap保证遍历时以Key的顺序来进行排序。例如,放入的Key是"apple"、"pear"、"orange",遍历的顺序一定是"apple"、"orange"、"pear",因为String默认按字母排序:
TreeMap<String, String> treeMap = new TreeMap<String, String>();
//
treeMap.put("z", "zhangsan");
treeMap.put("x", "lisi");
treeMap.put("a", "wangwu");
treeMap.put("c", "zhaoliu");
treeMap.put("h", "tianqi");
System.out.println(treeMap);
// {a=wangwu, c=zhaoliu, h=tianqi, x=lisi, z=zhangsan}
总结区别
- HashMap : 线程不安全,效率高, 允许key或value为Null
- HashTable : 线程安全,效率低, 不允许key或value为Null
- TreeMap : 线程不安全,根据键排序, key不可为空但值可以
IO流
File
常用方法
| 方法 | 描述 |
|---|---|
| isAbsolute() | 判断是否为绝对路径 |
| isFile() | 判断是否为标准文件 |
| isDirectory() | 判断是否为一个目录 |
| isHidden() | 判断是否为一个隐藏文件 |
| length() | 获取文件大小,如果是目录则不准确 |
| exists() | 判断文件或目录是否存在 |
| mkdir(), mkdirs() | 创建指定的目录 |
| delete() | 删除文件或目录,若是目录则只能为空时才能删除 |
| listFiles() | 返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件 |
| createNewFile() | 创建一个空的新文件 |
注意:mkdir()和mkdirs()创建的都是目录,但是mkdir()的是单极目录,mkdirs()则可以多级也更为推荐
具体来说,使用mkdir时,若它的上级目录未被创建就无法创建给定路径的目录,而mkdirs是可以的
FilenameFilter/FileFilter接口
可以实现对目录的过滤,如找出一个目录下的某一类型的文件
示例:
public class Filter {
public static void main(String[] args) {
String path = "C:\\Users\\ONEFOX\\Desktop\\gotoexec\\grpcapi";
filterMethods(path);
filterNamesMethod(path);
}
public static void filterMethods(String path) {
File f = new File(path);
// 使用匿名内部类来过滤, 注释的是idea推荐的写法
// File[] files = f.listFiles(pathname -> pathname.getName().endsWith(".go"));
File[] files = f.listFiles(new FileFilter() {
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(".go");
}
});
for (File file : files) {
System.out.println(file.getName());
}
}
public static void filterNamesMethod(String path) {
File f = new File(path);
// String[] files = f.list(new FilenameFilter() {
// @Override
// public boolean accept(File dir, String name) {
// return name.endsWith(".go");
// }
// });
String[] files = f.list((dir, name) -> name.endsWith(".go"));
for (String file : files) {
System.out.println(file);
}
}
}
字节流
数据流
数据流是指DataInputStream,DataOutputStream提供了读写各种基本类型数据以及String对象的读写方法,DataOutputStream怎么写的DataInputStream就必须怎么读,必须按照顺序来,不然会错位。
示例
public static void write() {
String path = "D:\\test.txt"
DataOutputStream dos = new DataOutputStream(new FileOutputStream(new File(path)));
dos.writeInt(77);
dos.writeLong(10001);
dos.writeChar('test');
dos.writeUTF("test file");
dos.close();
}
// 读取文件
public static void read() {
String path = "D:\\test.txt"
DataInputStream dros = new DataInputStream(new FileInputStream(new File(path)));
System.out.println(dros.readInt());
System.out.println(dros.readLong());
System.out.println(dros.readChar());
System.out.println(dros.readUTF());
dros.close();
}
字符流
InputStream,OutputStream类处理的是字节流,数据流中最小的单位是一个字节,但是读
写字符文本的时候不方便,java采用的Unicode字符编码,对于每个字符,java中分配两个字节
的内存,为了方便读写各种字符编码字符,java.io包中提供了Reader/Writer类,分别代表字符
输入流/字符输出流
java.io里面有四大抽象类:InputStream、OutputStream / Reader、Writer
转换流
InputStreamReader/OutputStreamWriter类是从字节流到字符流的桥接器,它使用指定的字符集读/写取字节并将它们解码为字符。为了获得最高效率,请考虑BufferedReader/BufferWriter中包装InputStreamReader/OutputStreamWriter,这样可以提高效率。
构造方法如下:
// 创建一个使用默认字符集的 InputStreamReader。
public InputStreamReader(InputStream in)
// 创建使用指定字符集的 InputStreamReader。
public InputStreamReader(InputStream in, String charsetName) throws
UnsupportedEncodingException
// 创建使用默认字符编码的 OutputStreamWriter。
public OutputStreamWriter(OutputStream out)
// 创建使用指定字符集的 OutputStreamWriter。
public OutputStreamWriter(OutputStream out, String charsetName) throws
UnsupportedEncodingException
写入文件带缓冲示例
public class demo {
public static void test1() {
String path = "D:\\test.txt";
String output ="";
InputStreamReader isr = new InputStreamReader(new FileInputStream(path1));
OutStreamWrite osr = new OutputStreamWriter(new FileOutputStream(path2));
}
public static void main([]String args) {
}
}
缓冲流
最佳的文件操作示例就是
import java.nio.charset.StandardCharsets;
public class FileOperation {
// 复制文件
public static void copyFile(File src, File des) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(src), "UTF-8"));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(des), "UTF-8"));
// 也可以这样:
// BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(src), StandardCharsets.UTF_8));
// BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(des), StandardCharsets.UTF_8));
String line = "";
while ((line = br.readLine()) != null) {
bw.write(line + "\n");
}
br.close();
bw.close();
}
// 复制文件夹
public static void copyFolder(File src, File des) throws IOException {
if (!src.exists() || !src.isDirectory()) {
throw new IllegalArgumentException("提供的文件夹不存在或者不是文件夹!");
}
if (!des.exists()) {
System.out.println("目标文件夹不存在,创建文件中...");
des.mkdirs();
}
File[] files = src.listFiles();
for (File file : files) {
if (file.isFile()) {
copyFile(file, new File(des, file.getName()));
} else {
File newDir = new File(des, file.getName());
newDir.mkdirs();
copyFolder(file, newDir);
}
}
}
// 剪切文件夹
public static void cutFolder(File src, File des) throws IOException {
copyFolder(src, des);
deleteFolder(src);
}
// 删除文件夹
public static void deleteFolder(File src) {
File[] files = src.listFiles();
for (File file : files) {
if (file.isFile()) {
file.delete();
} else {
deleteFolder(file);
}
}
src.delete();
}
}
压缩流
序列化,反序列化
网络编程-socket
tcp
udp
特点:UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输 (因为这种数据传输丢失一点数据不会对整体有影响)。由于UDP的面向无连接性,不能保证数 据的完整性,因此在传输重要数据时不建议使用UDP协议。
发送数据的示例:
package cn.com.main
public class UpdSender{
public staic void main(String[] args){
String msg = "hi";
String host = "127.0.0.1";
int port = 9999;
DatagramSocket ds = new DatagramSocket();
DatagramPacket dp = new DatagramPacket(ds.getBytes(), ds.getBytes.getLength(), InetAddress.getByName(host), port);
ds.send(dp);
ds.close();
}
}
反射
