
排序算法---冒泡排序
冒泡排序算法原理
1、进行比较相邻的元素,如果第一个元素比第二个元素大,swap(a1,a2);
2、对每一对相邻元素做相同的工作(一共做n - 1次),从最开始的一对到结尾的一对。
每次循环都会找出最后n - 1 - i个元素位的最大值元素。
3、重复上述步骤,直到所有的元素都进行比较完毕,结束循环。
算法流程图: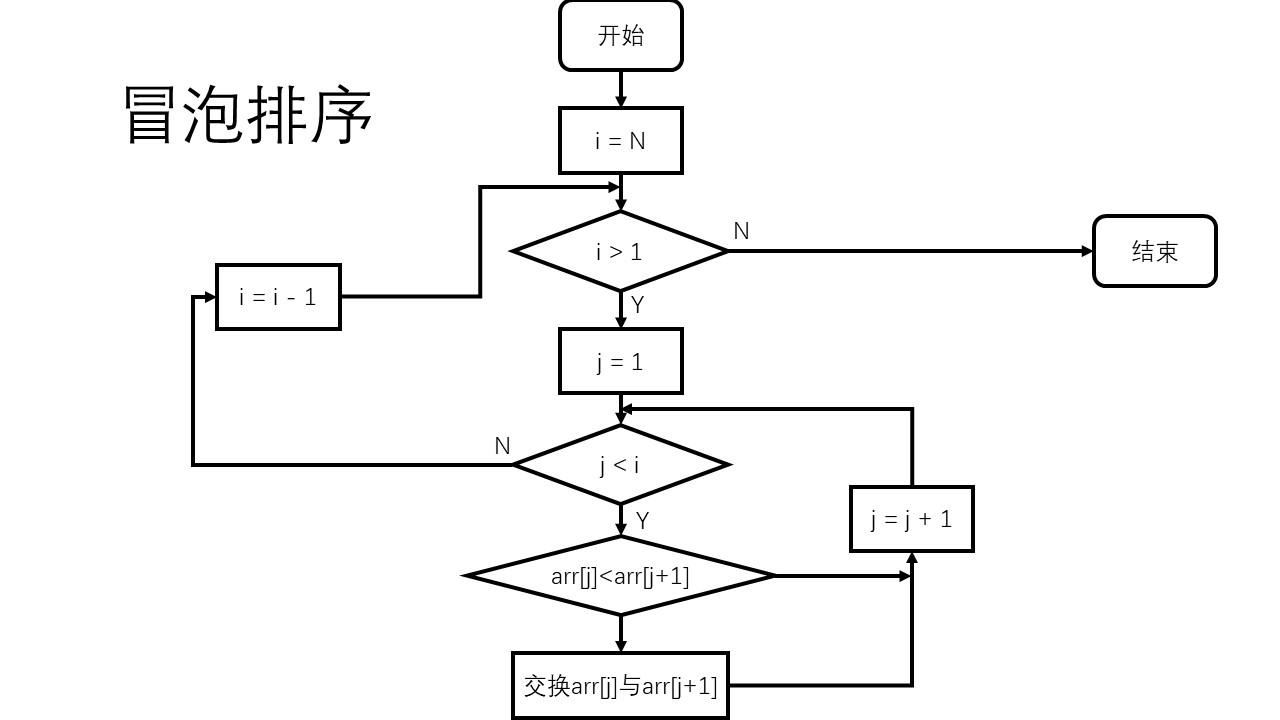
源代码:
#include<stdio.h> int main(){ int arr[10] = {9,5,2,7,3,1,6,4,0,8}; int i = 0, j = 0; // 冒泡排序 // 第一层循环表示数组需要重复[1,2]步骤的次数,即(n - 1)次 for(; i < sizeof(arr) / sizeof(arr[0]) - 1; i++){ // 第二层循环表示每次[1, 2]步骤中每组元素进行比较的次数 for(; j < sizeof(arr) / sizeof(arr[0] - 1 - i); j++){ if(arr[j] > arr[j + 1]){ int temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } // 打印arr数组元素 for(i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){ printf("%d ",arr[i]); } printf("\n"); return 0; }
arr数组

实现步骤简单叙述:
第一次 cmp<9,5> => [5,9 ...]
cmp<9,2> => [5,2,9 ...]
cmp<9,7> => [5,2,7,9 ...]
......
cmp<9,8> => [5,2,7,3,1,6,4,0,8,9] 第一次冒泡完成
......
最后第二次完成后的arr数组[1,0,2,3,4,5,6,7,8,9]
最后一次 cmp<0,1,2,3,4,5,6,7,8,9>
至此,冒泡排序全部完成。
冒泡排序优化
这样的代码,当面对一个已经排好序的数组时将会做很多的无效操作。 排序过程中,当某次遍历中没有进行数据交换,则代表数组已经排好序了
// 就是在源代码的基础上进行一些简单修改 // 冒泡排序法 for (int i = 0; i < sizeof(test) / sizeof(test[0]) - 1; i++) { int index = 1; // 假设冒泡排序已经完成 for (int j = 0; j < sizeof(test) / sizeof(test[0]) - 1 - i; j++) { if (test[j] > test[j + 1]) { int temp = test[j]; test[j] = test[j + 1]; test[j + 1] = temp; index = 0; } if (index == 1) { break; } } }
复杂度分析
最好情况,排序本身已经是有序的,比较次数为 n - 1,时间复杂度为O(n)
最坏情况,排序本身是逆序的,比较次数为 n(n-1) / 2,并作等数量级的记录移动
所以总的时间复杂度为O(n^2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号