

简学Python第一章__进入PY的世界
Python第一章__进入Python的世界
欢迎加入Linux_Python学习群
 群号:478616847
群号:478616847
目录:
-
什么是Python
-
Python开发环境安装
-
第一个程序 HelloWord!
-
初识数据类型
-
初识条件语句
-
Pass continue break
一、什么是Python
刚接触Python的我们第一个问题肯定就是到底什么是Python?Python能做什么?为什么Python现在这么火?
来大家看 这货就是Python,在看的观众肯定要骂了,你就给我看着个?哈哈,没错这个就是Python的代言人。
这货就是Python,在看的观众肯定要骂了,你就给我看着个?哈哈,没错这个就是Python的代言人。
其实Python有很多优秀的特点:
(1)Python 是一门简明并强大的面向对象编程的语言、
(2)简单易学适合快速开发各种程序
(3)Python在WEB开发,软件开发,科学运算,大数据分析,自动化运维等方面得到了广泛的应用
Python的创始人为 吉多·范罗苏姆 1989年的圣诞节期间,他为了打发时间,决心开发一个新的脚本解释程序作为ABC语言的一种集成,
这门语言结合了JAVA和Shell的优势特性,并且属于解释型语言的它在可移植性、可扩展性、可嵌入性都有独特的优势。那么有人要问什么是解释型语言?
解释型语言与编译型语言的区别
编译型:
优点:编译器一般会有预编译的过程对代码进行优化,因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高,可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译,编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就好有问题,需要根据运行的操作
系统环境编译不同的可执行文件。
解释型:
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码直接修改即可,无需再次编译,快速部署无需停机维护
缺点:性能方面不如编译型语言
Python的种类
- Cpython
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。 - Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。 - IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似) - PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。
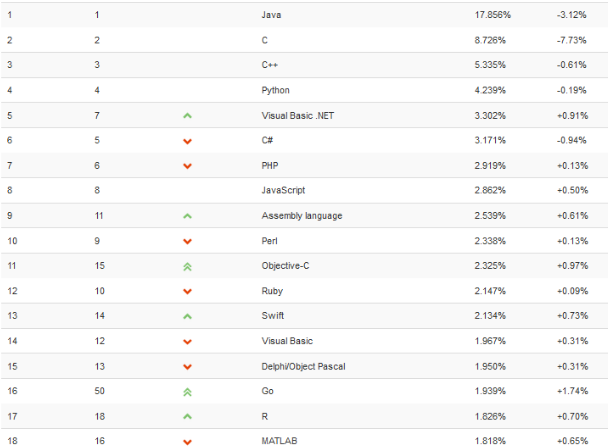
Python在热门语言中的排名:
下面的图片就是今年Python跟各大热门语言对比的排名,我们的Python现在处于第四位,并且同JAVA/C/C++/一起成为程序员最热爱的四大语言之一。
总而言之用一句话总结Python,就是学的快,用的多。
二、Python开发环境安装
下面我们开始安装我们的Python环境,首先我们去Python官网下载安装包,官方下载地址https://www.python.org/downloads/ 选择对应的版本下载即可,安装非常傻瓜式,
下一步下一步即可,Linux自带Python2.6,我们可以使用yum 和apt进行安装其它版本。
(1)配置windows 命令行运行python2.7,和3.5环境
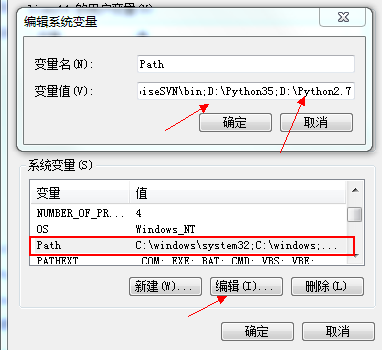
右键计算机-选择管理-选择高级系统设置-选择高级-选择环境变量-选择系统变量中的Path-选择编辑,如下图添加python3.5和2.7的安装路径即可,记住分隔符是分号“;”
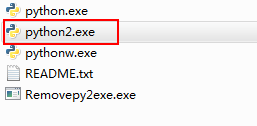
进入到最后添加版本的安装目录中复制python.exe,粘贴,并更改名称3.5改成python3.exe,2.7改成python2.exe,记住更改的是在Path变量中添加到最后Pthon版本的执行文件
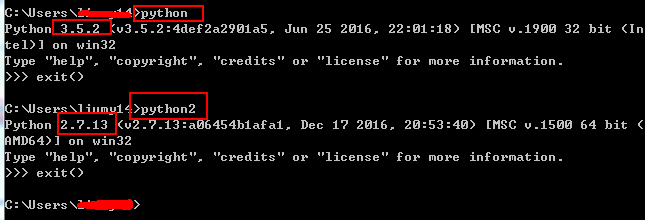
结果
三、第一个程序 HelloWorld!
(1) 第一句代码,print("Hello World"),在python3.5环境中输入print("Hello World")注意中英文字符,此时我们看到下面返回了Hello World,那么 print()就是python中的输出语句

了解一下Python内部的执行过程(无需深究):

(2)解释器
我们会shell的童鞋都知道在linux中执行shell文件都需要指定解释器,那么我们执行python文件的时候也需要加上解释器,就跟shell脚本一样,我们用vim创建一个hello.py
的文件,给他执行的权限,写入如下内容,写入后就可以像shell一样执行python文件了。


1 #!/usr/bin/env python
2
3 print "hello,world"
(3)编码
我们知道在我们的计算机中使用的是二进制,所以在Python解释器加载.py 文件中的代码时,会对内容进行编码(默认ascill)ASCII(American Standard Code for InformationInterchange,
美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示
256 个符号。我们来看下对应关系表
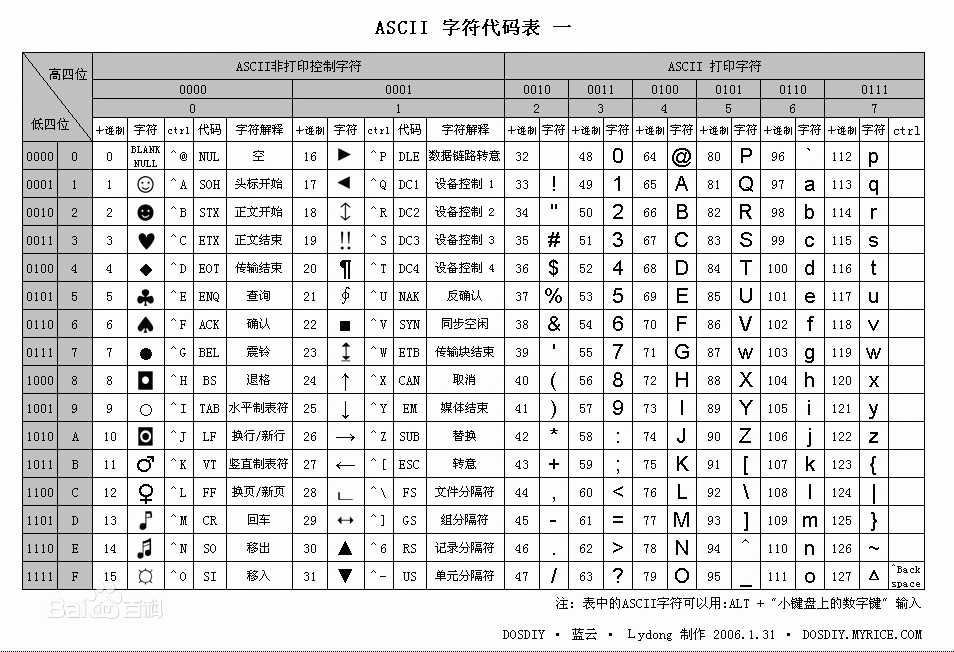
我们从这张表中可以看到,没有中文,那中国人写中国字怎么办,等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒
智慧的中国人民,我们不客 气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一
个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊
的 字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符
了。 中国人民看到这样很不错,于是就把这种汉字方案叫做 "GB2312"。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。于是我们不得不继续把 GB2312 没有用到的码位找出来老实不
客气地用上。 后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不 是扩展字符集里的内
容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
那么其他国家也是像中国一样增加自己国家的编码这样弄得非常乱,后来出现了标准组织,将全球的文字都收录了进去,推出了Ubicode编码格式,此编码中规定,所有字符最少用16位表
示,也就是两个字节,那么对于使用字母的国家很显然占用了更高的空间所以UTF-8推出,它就是对Unicode编码压缩和优化,其中规定了 ascii码中的内容用1个字节保存,欧洲字符用两
个字节保存,东亚的字符韩文中文一类的用三个字节保存。
所以!在Python3以前我们要打印中文就需要增加另一行注释,如下但是在Python3中不需要加,因为python3默认是Unicode编码。
1 #!/usr/bin/env python
2 # -*- coding: utf-8 –*-
3
4 print("你好 世界")、
变量
- 变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if',
'import', 'in', 'is', 'lambda', 'not', 'or', 'pass','print', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释:单行注视:# 被注释内容 多行注释:""" 被注释内容 """
四、初识数据类型
字符串(str)
什么是字符串,字符串就是由0个或多个字符组成的有限序列,上面所打印的“Hello World”就是一个字符串,通常以串作为操作的整体。
单引号,双引号,和转义
在一般的时候 ‘Hello,world!’ 和 “Hello,world!” 是没有什么区别的,那么为什么会两个都可以用呢?是因为在某些情况下,他们会派上用处
1 >>> "Hellow,world" 2 'Hellow,world' 3 >>> 'Hellow,world' 4 'Hellow,world'
在下面的代码中,第一段字符串包含了单引号,所以呢整体就不能用单引号包括起来,如果这样做的话,解释器就会抱怨(它这么做也是对的)
>>> "Let's go!" "Let's go!"
>>> 'Ler's go!' SyntaxError: invalid syntax
虽然上面的代码,用双引号执行时成功的,但是我们不一定要这么来去做,这里就涉及到转义(\),这样做Python就会明白其中一个单引号是一个字符
>>> 'Ler\'s go!'
"Ler's go!"
字符串拼接
在很多的时候我们都会用到字符串拼接,因为在输出一句话的时候往往需要调用多个变量的值,那么拼接的方法也有很多
1 #第一种 2 3 >>> a="Hello" 4 >>> b="World" 5 >>> print(a,b) 6 Hello World 7 8 #第二种 9 >>> a+b 10 'HelloWorld'
注!python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,
万恶的+号每出现一次就会在内从中重新开辟一块空间。
我们可以发现上面的两种方法都不方便,因为加入我要输出一段很长很长的话,中间需要调用变量的时候怎么办?别担心我们还有第三种方法,下面就是字符串格式化,格式
化有两大中方式,第一种不受位置的影响,也就是说.format(two=b,one=a)也是可以的,但是第二种方法必须按照位置进行排序,而且%s和%d代表着接受不同的替换字符类型,
1 >>>a = "Hello" 2 >>>b = "World" 3 4 >>> print("{one},{two}".format(one=a,two=b)) 5 Hello,World 6 7 >>> print("%s,%s,%d"%(a,b,11)) 8 Hello,World,11 9 10 %s 字符串 (采用str()的显示) 11 12 %r 字符串 (采用repr()的显示) 13 14 %c 单个字符 15 16 %b 二进制整数 17 18 %d 十进制整数 19 20 %i 十进制整数 21 22 %o 八进制整数 23 24 %x 十六进制整数 25 26 %e 指数 (基底写为e) 27 28 %E 指数 (基底写为E) 29 30 %f 浮点数 31 32 %F 浮点数,与上相同 33 34 %g 指数(e)或浮点数 (根据显示长度) 35 36 %G 指数(E)或浮点数 (根据显示长度)
字符串内置方法
在python中有一句经典的话,一切接对象,举个例子比如我们有一个尺子,还有一只笔,那么尺子是用来测量东西的,笔是用来写东西画东西的,那么他们都有不同的功能,
我们换句话来说尺子这类东西有量东西的功能,笔这类东西有鞋写东西的功能,那么回到python,字符串这类东西也有很多功能:python中把字符串称之为str
1 字母处理 2 3 全部大写:str.upper() 4 全部小写:str.lower() 5 大小写互换:str.swapcase() 6 首字母大写,其余小写:str.capitalize() 7 首字母大写:str.title() 8 9 >>> a = "hello" 10 >>> b = "Hello" 11 >>> a.upper() 12 'HELLO' 13 >>> b.lower() 14 'hello' 15 >>> b.swapcase() 16 'hELLO' 17 >>> a.capitalize() 18 'Hello' 19 >>> c = "hello world" 20 >>> c.title() 21 'Hello World' 22 23 格式化相关 24 25 获取固定长度,右对齐,左边不够用空格补齐:str.ljust(width) 26 获取固定长度,左对齐,右边不够用空格补齐:str.rjust(width) 27 获取固定长度,中间对齐,两边不够用空格补齐:str.center(width) 28 获取固定长度,右对齐,左边不足用0补齐str.zfill(width) 29 30 >>> a.ljust(15) 31 'hello ' 32 >>> a.rjust(15) 33 ' hello' 34 >>> a.center(15) 35 ' hello ' 36 37 >>> a.zfill(15) 38 '0000000000hello' 39 40 字符串搜索相关 41 搜索指定字符串,没有返回-1:str.find('t') 42 指定起始位置搜索:str.find('t',start) 43 指定起始及结束位置搜索:str.find('t',start,end) 44 从右边开始查找:str.rfind('t') 45 搜索到多少个指定字符串:str.count('t') 46 上面所有方法都可用index代替,不同的是使用index查找不到会抛异常,而find返回-1 47 48 字符串替换相关 49 替换old为new:str.replace('old','new') 50 替换指定次数的old为new:str.replace('old','new',maxReplaceTimes) 51 52 字符串去空格及去指定字符 53 去两边空格:str.strip() 54 去左空格:str.lstrip() 55 去右空格:str.rstrip() 56 去两边字符串:str.strip('d'),相应的也有lstrip,rstrip 57 58 字符串判断相关(这里涉及到布尔值(也就是条件成立为真True不成立为假False)请看下面的内容) 59 是否以start开头:str.startswith('start') 60 是否以end结尾:str.endswith('end') 61 是否全为字母或数字:str.isalnum() 62 是否全字母:str.isalpha() 63 是否全数字:str.isdigit() 64 是否全小写:str.islower() 65 是否全大写:str.isupper()
数字(int)
其中数字类型的内置方法参考http://www.cnblogs.com/bj-xy/p/5184952.html
数字类型分为
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
运算
在数字类型中也涉及到数学中的加减乘除等运算,这些运算在日常编程中经常被用到,所以请熟知。
请参考http://www.runoob.com/python/python-operators.html
用户输入
在用户输入的操作中,python2里面存在 input和raw_input,然而在python3中就只有input了,下面的例子中可以使用type()来输出你的变量的类型
下面是python2中测试的,可以看到raw_input输出的类型是str那么str就是字符串,input输出的是int类型那么就是数字,在python3中的input输出的
只是字符串,不会像2中那样分开
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 userin_str = raw_input("请输入一串字符串:") 5 6 userin_int = input("请输入一个数字") 7 8 print(type(userin_str)) 9 10 print(type(userin_int))
那么为什么python3把输入数字给取消了,其实原因很简单,当你在2中使用input输入字符串的时候就会报错,那么在使用中还要对它进行处理,这样的
操作还不如让输入的类型都是str,然后针对str进行操作,是数字的可以转换成数字类型,是字符串的那么就直接使用就好了
五、初识条件语句
什么是条件语句?熟悉其他语言的同学肯定很清楚,条件语句就是通过条件来判断是否执行某些语句模块
例子:
你去A超市打个酱油
如果A超市关门
你在B超市打酱油
否则
你在A超市打酱油
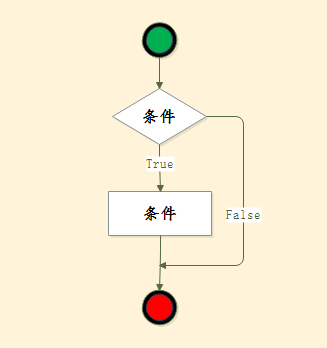
可以看到,在上面的例子中,可以让一件事情有两个执行过程,那么控制这个过程的有两个关键字 如果,否则!如果后面是条件的判断,否则则是条件失败的时候执行的操作
我们把上面的汉语转换成python语言中的if语句
if判断
布尔值
布尔表达式就是判断真假,也就是True和False,计算机的机器代码由1和0来表示所以,1表示有也表示真,0表示无也表示假。
1 >>> a = 1 2 >>> a == 3 3 False 4 >>> a == 1 5 True 6 >>> True 7 True 8 >>> False 9 False 10 >>> True == 1 11 True 12 >>> False == 0 13 True
if 语句也就是运用真与假来进行判断
if
else 子句当条件为假的时候执行什么操作
elif 子句当要检查多个条件的时候使用
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 #if 表示 如果条件成立则输出正确的输出 5 userin_str = input("请输入一个数字:") 6 if "userin_str" == "11": 7 print("恭喜你猜对了") 8 9 #if else 表示 如果条件成立则输出正确的输出 否则输出错误的输出 10 userin_str = input("请输入一个数字:") 11 if "userin_str" == "11": 12 print("恭喜你猜对了") 13 else: 14 print("不好意思你猜错了") 15 16 #if elif else 表示 如果条件成立则输出正确的输出 或者第二个条件成立则输出正确输出 否则输出错误输出 17 userin_str = input("请输入一个数字:") 18 if "userin_str" == "1": 19 print("恭喜你猜对了") 20 elif "userin_str" == "2": 21 print("猜到这个数也算你对") 22 else: 23 print("不好意思你猜错了")
三元运算
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
例子中表示 如果 a>b 则result 等于 a-b 否则等于a+b
1 a = 5 2 b = 6 3 result = a-b if a>b else a+b 4 print(result)
while 循环
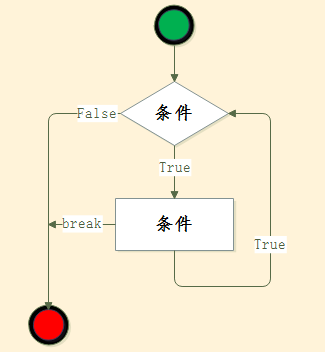
如果有一个需求,让你打印1-100这些数字,按照常理我们可能就会print(1) print(2) ........ print(100) 小伙伴们或说什么鬼,单单打印就要100行
当然要真的是这样那么也不用学python了,要实现这个需求我们可以借助while循环来做,并结合计数器
1 counter = 0 2 while True: 3 counter +=1 4 print(counter)
上面是一个死循环,那么它一直会打印,打印,无法退出,在写程序中应该避免并且这个显然不符合我们的需求,那么我们需要让他打印到100 就退出
1 结合if语句 2 #方法1 3 counter = 0 4 while True: 5 counter +=1 6 print(counter) 7 if counter == 100: 8 break 9 10 #方法2 11 counter = 0 12 judge = True 13 while judge: 14 counter +=1 15 print(counter) 16 if counter == 100: 17 judge = False
在上面代码中我们看到了“break”,这个代码的功能就是退出当前循环,下面有详细介绍
While循环有两个条件可以退出,一就是当匹配某个条件break退出的,二就是当循环条件等于False的时候
for循环
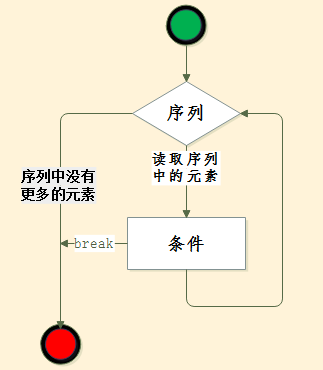
在使用中发现while循环并不能符合一些场景需求,比如我想竖着打印一个字符串,还有上面打印1到100的代码能不能简单点
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 5 #分别打印字符串中每一个元素 6 for_str = "ABCDEFG" 7 for i in for_str: 8 print("我是字母:%s"%(i)) 9 10 11 #for版本打印1到100,借助range()功能 12 for i in range(1,101): 13 print(i)
在for循环中有两种情况可以退出循环,一种for循环序列中没有原始了,另外一种就是条件成立后break退出
range()内建函数是生成一个范围的列表,range(1,101)生成1到100的数字,并且它是通过起始位置1,生成到后面位置减1的数字
缩进
python不同于其它语言,其它语言中,每个语言都有一个大括号或者其它方式来区分哪些代码属于这个条件语句的
在python中统一的缩进就代表着属于一个条件语句,正因为这样python不需要用括号的方式来区分代码块,
在缩进里面,有人喜欢打四个空格,有人喜欢打tab键,据说这两种人碰到一起回擦出不一样的火花!
六、 Pass continue break
在上面我们接触到了break语句,在python中还有其它的语句
break:退出当前循环,打破当前层的for或while循环。
continue:跳槽本次循环
pass:不做任何事情,一般用做占位语句
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 #continue,当i等于C则触发continue,直接返回下一次for循环,下面print不会执行 5 for_str = "ABCDEFG" 6 for i in for_str: 7 if i == "C": 8 continue 9 print("我是字母:%s"%(i)) 10 11 #pass,当i等于C则触发pass,print不会执行 12 for i in for_str: 13 if i == "C": 14 pass 15 else: 16 print("我是字母:%s"%(i)) 17 18 #break 当匹配i等于C的时候就会break,退出当前层的循环 19 for i in for_str: 20 if i == "C": 21 break 22 else: 23 print("我是字母:%s"%(i))
作者:北京小远
出处:http://www.cnblogs.com/bj-xy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号