
基于现有的Kubernetes集群部署Prometheus监控
前言:
Prometheus官网提供了很多安装方式https://prometheus.io/docs/prometheus/latest/installation/
在这里我选择通过Kube-Prometheus Stack技术站栈进行安装
Kube-Prometheus项目地址:https://github.com/prometheus-operator/kube-prometheus/
Prometheus架构图
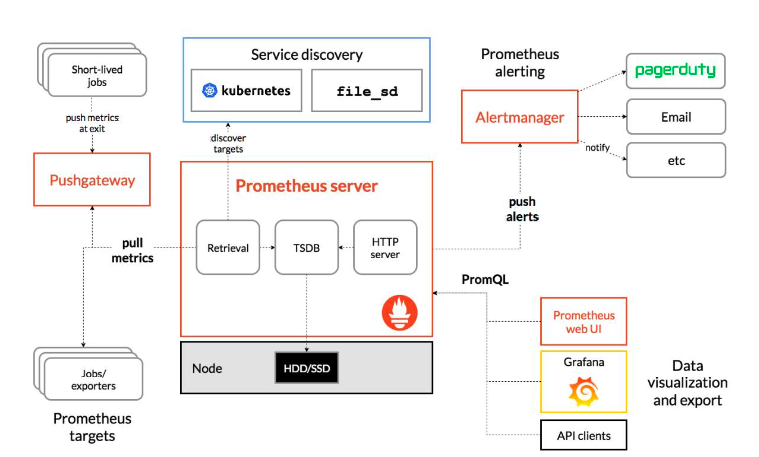
组件解析:
- Prometheus Server: prometheus生态最重要的组件,主要用于抓取和存储时间序列数据,同时提供数据的查询和告警策略的配置管理
- Alertmanager: Prometheus生态用于告警的组件,Prometheus Server会将告警发送AlertManager,随后Alertmanager根据路由配置,将告警信息发送给指定的人或者组,AlertManager支持邮件、webhook、微信、钉钉、短信等媒介进行告警通知
- Grafana: 用于展示数据,便于数据的查询和观测
- Push Gateway:Prometheus本身是通过Pull的方式拉取数据,但有些数据是短期的,如果没有采集数据可能会出现丢失,Push Gateway可以用于解决此类问题。可以用来数据接收,也就是客户端可以通过Push的方式将数据推送到Push Gateway,之后Prometheus可以通过Pull拉取该数据
- Exportes: 主要用来采集监控数据,比如主机的监控数据可可以通过node_exportes采集,MySql的监控数据可以通过mysql_exportes采集,之后Exportes 暴露一个接口,比如/metrics, Prometheus可以通过该接口采集到数据
- PromQL: promQL其实不算Prometheus的组建,它是用来查询数据的一种语法,比如查询数据库的数据,可以通过SQL数据,查询Loki的数据,可以通过LogQL,查询Prometheus的数据叫PromQL
- Service Discovery:用来发现监控目标的自动发现,常用的有基于Kubernetes、Consul、Eureka、文件的自动发现等
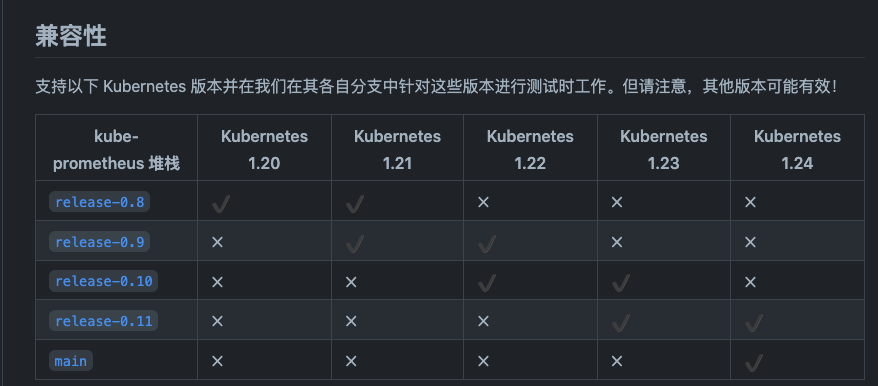
通过该地址找到与自己Kubernetes版本相对应的Kube Prometheus Satck版本
克隆kube-prometheus仓库
[root@k8s-master01 prometheus]# git clone -b release-0.8 https://github.com/prometheus-operator/kube-prometheus.git 正克隆到 'kube-prometheus'... ^[remote: Enumerating objects: 16466, done. remote: Counting objects: 100% (387/387), done. remote: Compressing objects: 100% (149/149), done. remote: Total 16466 (delta 272), reused 292 (delta 222), pack-reused 16079 接收对象中: 100% (16466/16466), 8.22 MiB | 86.00 KiB/s, done. 处理 delta 中: 100% (10602/10602), done. [root@k8s-master01 prometheus]# cd kube-prometheus/manifests/ [root@k8s-master01 manifests]# kubectl apply -f setup/ namespace/monitoring created customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com configured customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com configured customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com configured customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com configured Warning: resource customresourcedefinitions/prometheuses.monitoring.coreos.com is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically. customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com configured customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com configured customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com configured customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com configured clusterrole.rbac.authorization.k8s.io/prometheus-operator created clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created service/prometheus-operator created serviceaccount/prometheus-operator created
查看Operator容器状态
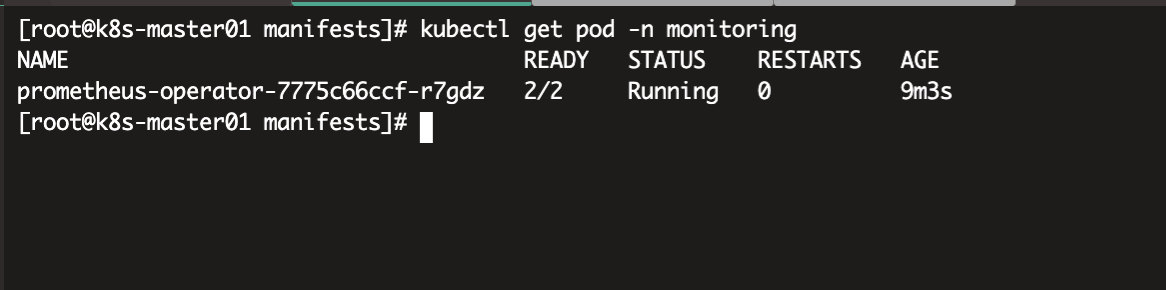
Operator容器启动之后,接下来安装Prometheus Stack技术栈
[root@k8s-master01 manifests]# vim alertmanager-alertmanager.yaml
apiVersion: monitoring.coreos.com/v1 kind: Alertmanager metadata: labels: alertmanager: main app.kubernetes.io/component: alert-router app.kubernetes.io/name: alertmanager app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 0.21.0 name: main namespace: monitoring spec: image: quay.io/prometheus/alertmanager:v0.21.0 nodeSelector: kubernetes.io/os: linux podMetadata: labels: app.kubernetes.io/component: alert-router app.kubernetes.io/name: alertmanager app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 0.21.0 replicas: 1 #这里只为做演示使用,减少系统资源消耗,我们将该副本数改成1,也就是单节点,在生产环境中我们可以设置为3 resources: limits: cpu: 100m memory: 100Mi requests: cpu: 4m memory: 100Mi securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 serviceAccountName: alertmanager-main version: 0.21.0
[root@k8s-master01 manifests]# vim prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: labels: app.kubernetes.io/component: prometheus app.kubernetes.io/name: prometheus app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 2.26.0 prometheus: k8s name: k8s namespace: monitoring spec: alerting: #告警配置 alertmanagers: - apiVersion: v2 name: alertmanager-main #alertmanagers的service名称 namespace: monitoring port: web externalLabels: {} image: quay.io/prometheus/prometheus:v2.26.0 nodeSelector: kubernetes.io/os: linux podMetadata: labels: app.kubernetes.io/component: prometheus app.kubernetes.io/name: prometheus app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 2.26.0 podMonitorNamespaceSelector: {} podMonitorSelector: {} probeNamespaceSelector: {} probeSelector: {} replicas: 2 #高可用节点,默认设置为2 resources: requests: memory: 400Mi ruleSelector: matchLabels: prometheus: k8s role: alert-rules securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 serviceAccountName: prometheus-k8s serviceMonitorNamespaceSelector: {} serviceMonitorSelector: {} version: 2.26.0
修改metrics镜像源地址
[root@k8s-master01 manifests]# vim kube-state-metrics-deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: labels: app.kubernetes.io/component: exporter app.kubernetes.io/name: kube-state-metrics app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 2.0.0 name: kube-state-metrics namespace: monitoring spec: replicas: 1 selector: matchLabels: app.kubernetes.io/component: exporter app.kubernetes.io/name: kube-state-metrics app.kubernetes.io/part-of: kube-prometheus template: metadata: annotations: kubectl.kubernetes.io/default-container: kube-state-metrics labels: app.kubernetes.io/component: exporter app.kubernetes.io/name: kube-state-metrics app.kubernetes.io/part-of: kube-prometheus app.kubernetes.io/version: 2.0.0 spec: containers: - args: - --host=127.0.0.1 - --port=8081 - --telemetry-host=127.0.0.1 - --telemetry-port=8082 #image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0 image: bitnami/kube-state-metrics:2.0.0 #因为默认是gcr国外镜像,一般情况下是无法正常下载的,因此我们需要在hub.docker镜像官网上进行相应版本下载 name: kube-state-metrics resources: limits: cpu: 100m memory: 250Mi requests: cpu: 10m memory: 190Mi securityContext: runAsUser: 65534 - args: - --logtostderr - --secure-listen-address=:8443 - --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH _CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305 - --upstream=http://127.0.0.1:8081/ image: quay.io/brancz/kube-rbac-proxy:v0.8.0 name: kube-rbac-proxy-main ports: - containerPort: 8443 name: https-main resources: limits: cpu: 40m memory: 40Mi requests: cpu: 20m memory: 20Mi securityContext: runAsGroup: 65532 runAsNonRoot: true runAsUser: 65532 - args: - --logtostderr - --secure-listen-address=:9443 - --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305 - --upstream=http://127.0.0.1:8082/ image: quay.io/brancz/kube-rbac-proxy:v0.8.0 name: kube-rbac-proxy-self ports: - containerPort: 9443 name: https-self resources: limits: cpu: 20m memory: 40Mi requests: cpu: 10m memory: 20Mi securityContext: runAsGroup: 65532 runAsNonRoot: true runAsUser: 65532 nodeSelector: kubernetes.io/os: linux serviceAccountName: kube-state-metrics
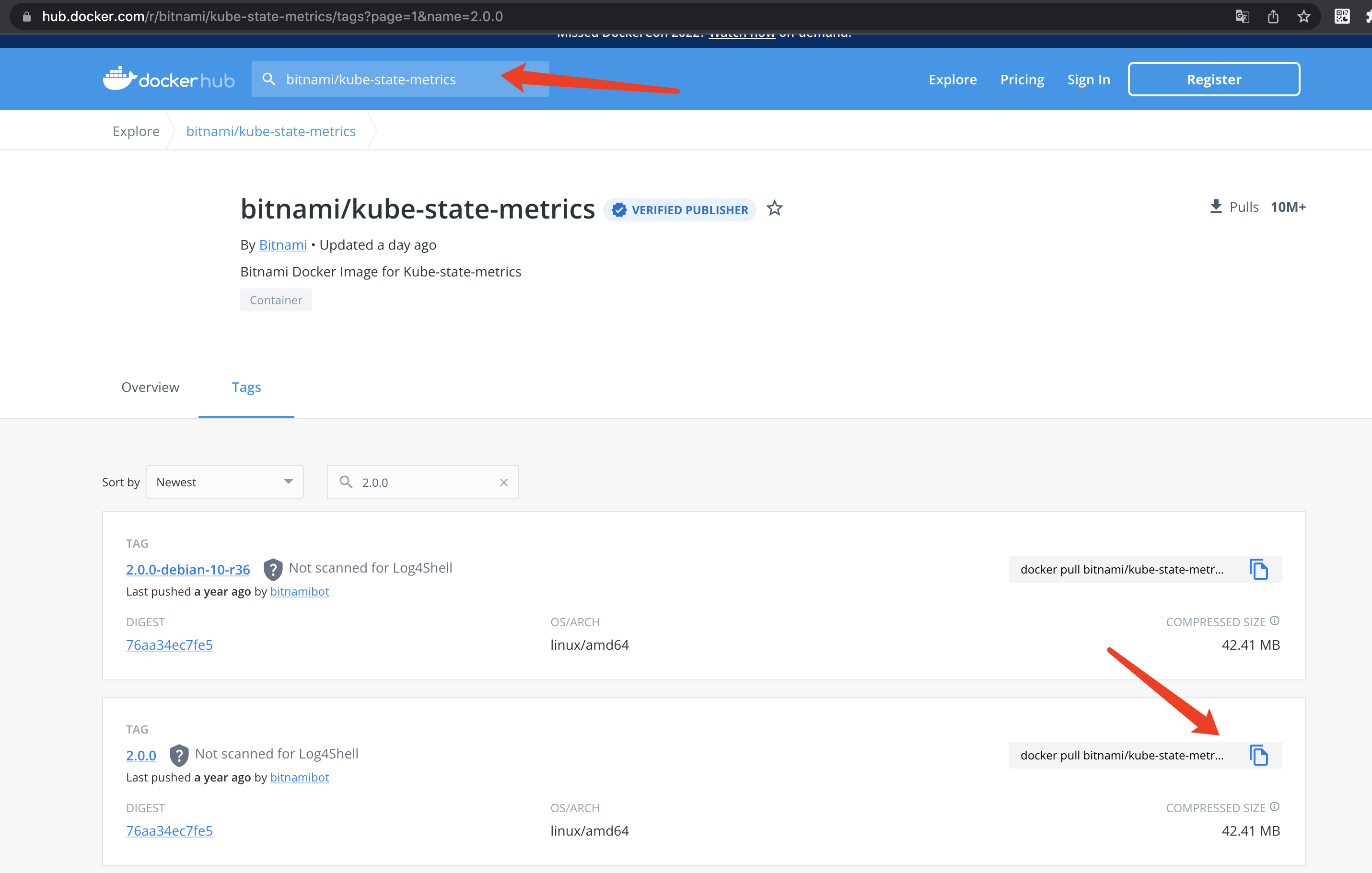
#获取kube-state-metrics镜像
https://hub.docker.com/r/bitnami/kube-state-metrics/tags?page=1&name=2.0.0
相关yaml配置调整之后,直接apply创建即可
[root@k8s-master01 manifests]# kubectl get -f .
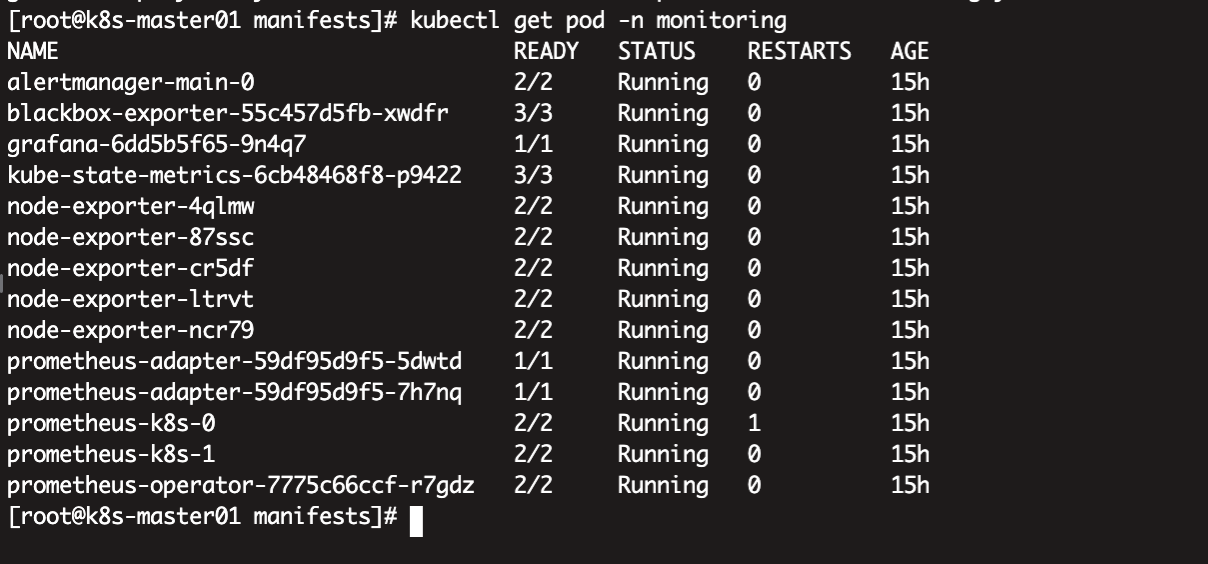
[root@k8s-master01 manifests]# kubectl get pod -n monitoring
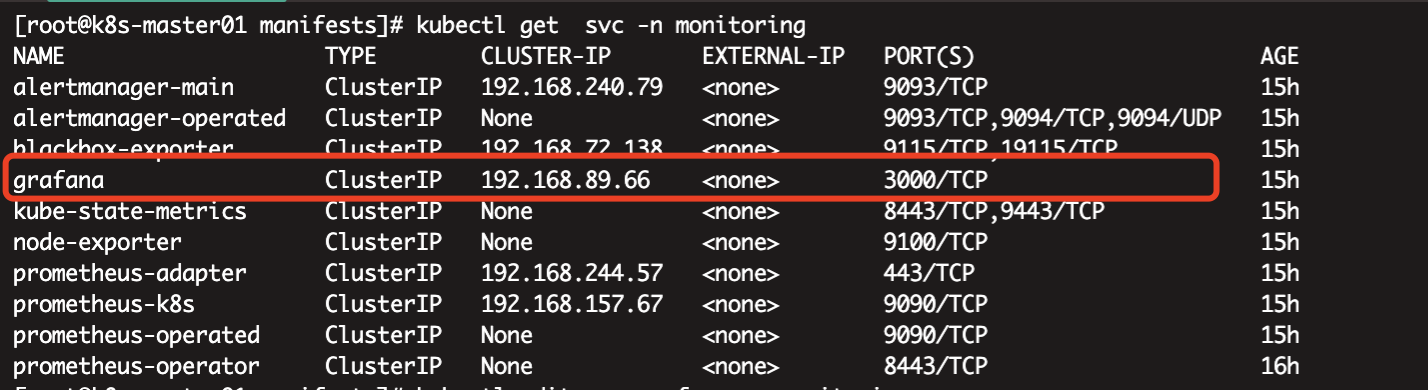
[root@k8s-master01 manifests]# kubectl get svc -n monitoring #查看monitoring命名空间下的Grafana service
[root@k8s-master01 manifests]# kubectl edit svc grafana -n monitoring #通过edit修改成NodePort模式,允许外部访问

root@k8s-master01 manifests]# kubectl get svc -n monitoring #修改完毕之后查看grafana service 所暴露出来的随机IP地址,便于测试访问 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main ClusterIP 192.168.240.79 <none> 9093/TCP 15h alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 15h blackbox-exporter ClusterIP 192.168.72.138 <none> 9115/TCP,19115/TCP 15h grafana NodePort 192.168.89.66 <none> 3000:32621/TCP 15h kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 15h node-exporter ClusterIP None <none> 9100/TCP 15h prometheus-adapter ClusterIP 192.168.244.57 <none> 443/TCP 15h prometheus-k8s ClusterIP 192.168.157.67 <none> 9090/TCP 15h prometheus-operated ClusterIP None <none> 9090/TCP 15h prometheus-operator ClusterIP None <none> 8443/TCP 16h
之后可以通过一个安装了kube-proxy服务节点IP(或者keepalived+Haproxy的VIP)+32621端口即可访问到Grafana页面
Grafana默认登录的账号密码为admin/admin。然后相同的方式更改Prometheus的Service为 NodePort:
[root@k8s-master01 manifests]# kubectl edit svc prometheus-k8s -n monitoring
service/prometheus-k8s edited

[root@k8s-master01 manifests]# kubectl get svc -n monitoring #查看prometheus所暴露的出来的外部访问端口 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main ClusterIP 192.168.240.79 <none> 9093/TCP 16h alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 16h blackbox-exporter ClusterIP 192.168.72.138 <none> 9115/TCP,19115/TCP 16h grafana NodePort 192.168.89.66 <none> 3000:32621/TCP 16h kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 16h node-exporter ClusterIP None <none> 9100/TCP 16h prometheus-adapter ClusterIP 192.168.244.57 <none> 443/TCP 16h prometheus-k8s NodePort 192.168.157.67 <none> 9090:30311/TCP 16h prometheus-operated ClusterIP None <none> 9090/TCP 16h prometheus-operator ClusterIP None <none> 8443/TCP 16h
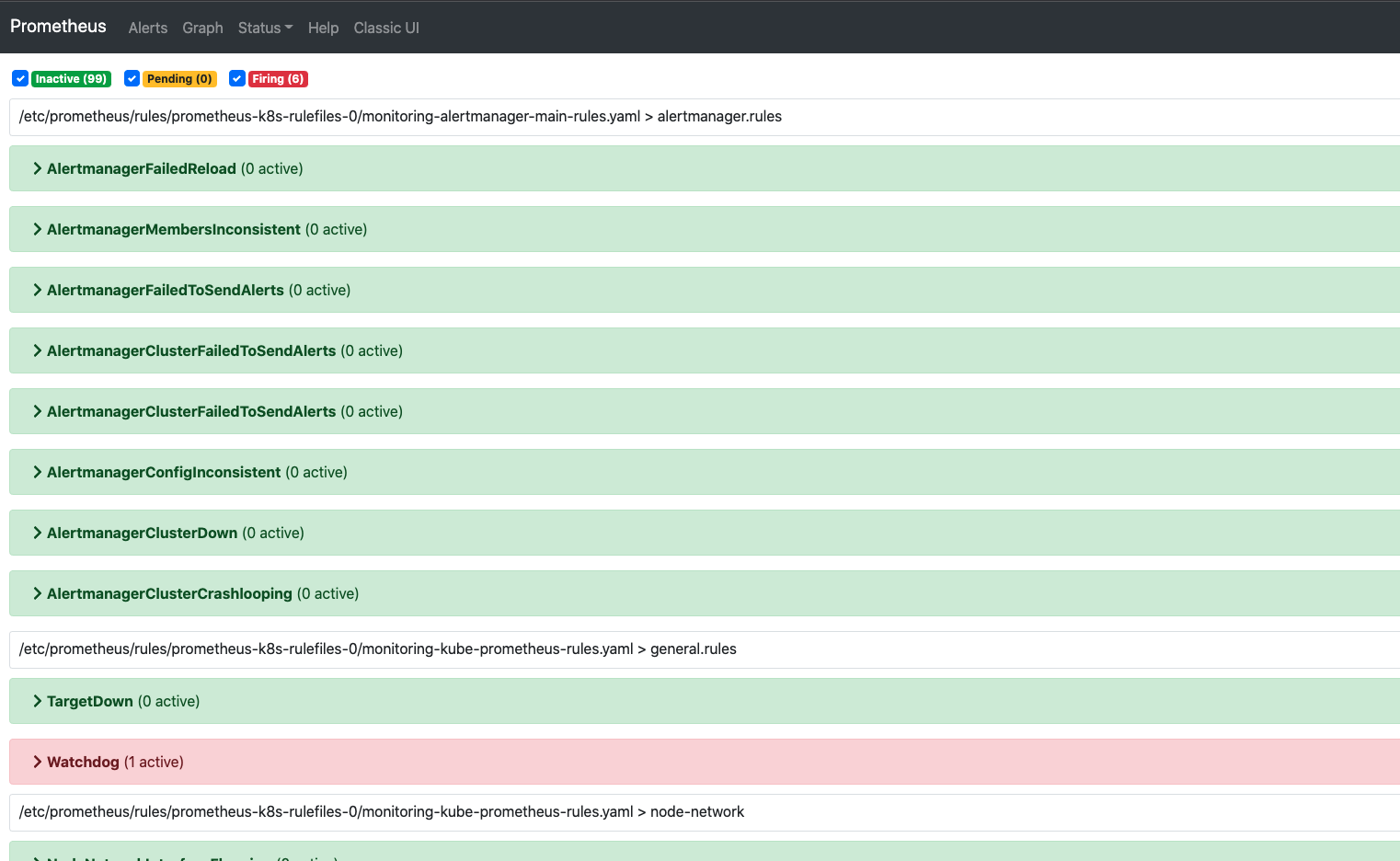
点击Alerts部分出现告警信息暂且忽略。后续可调试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号