论文笔记-巧妙的验证码攻击
论文题目:Yet Another Text Captcha Solver A Generative Adversarial Network Based Approach
论文原作者:GuixinYe,ZhanyongTang∗,DingyiFang,ZhanxingZhu,YansongFeng, Pengfei Xu, Xiaojiang Chen, and Zheng Wang
原文会议或期刊: CCS’18, October 15-19, 2018, Toronto, ON, Canada
原文链接:https://dl.acm.org/citation.cfm?doid=3243734.3243754
原文主要内容:基于生成对抗网络方法,构建了一个合成验证码的模型和一个消除验证码干扰特征的模型,利用CNN(扩展的LeNet-5方法)识别消除干扰特征的验证码,最终实现验证码识别准确率的较大提升
作者:苦瓜@DAS
0 动机
某晚师兄在群里转发了一篇微信文章,介绍我国西北大学教授在验证码识别领域的研究成果,因其在验证码识别领域有较大突破,论文发表在ACM CCS-18上,并获得了最佳论文提名,甚至被国外一些媒体进行了报道,文章写道:“该项研究比2017年发表在Science上的研究成果平均高出20%”。当时我就震惊了,这么🐮🍺的🐎?于是花了两天时间读完了这篇文章,发现:💉💧🐮🍺!
1 一个自信的摘要和引言
原文作者(以下均简称作者)在摘要部分开门见山,指出这次的识别模型与前人工作不同,不需要人工收集大量数据并打标签,使用极小的数据集就能达到非常好的表现,而且一块桌面级的GPU即可在0.05s以内准确秒杀文本验证码,最后希望作者的研究结果能激励社会重新设计和实施文本验证码策略。
而后作者在引言(Introuduction)部分主要介绍了
-
本次使用的验证码来源——Alexa评出的2018年最受欢迎的50个网站中的32个使用文本验证码的网站,这些网站有不同的验证码安全方案。
-
文本验证码在当今普遍使用,近年来也有很多这方面的研究,其中一些成功的策略是分割验证码中每个字符再进行识别,但随着验证码的生成规则愈加复杂(例如加入干扰背景,扭曲文字,重叠文字),这些方法开始失效
-
文章提出一种基于深度学习的通用、省力且有效的自动化识别文本验证码的方法
- 利用生成对抗网络自动生成大量的合成验证码,用于训练识别器
- 用一个较小的真实验证码数据集(500张验证码),通过迁移学习微调基础识别器参数
- 因为不需要人工的收集大量验证码并打标签,所以极大的节省了人力
在引言的最后,作者写到,我们这篇paper也没干什么别的,大概三件事:
第一个,首次使用生成对抗网络方法自动生成训练数据,构建文本验证码求解器(Text-Based Solvers)
第二个,首次应用迁移学习训练文本验证码求解器
第三个,提供一种新的见解——文本验证码的安全特征(例如波浪文字、横线和文字重叠等各种干扰)在深度学习方法面前非常脆弱。
2 开门见山——直击模型详情
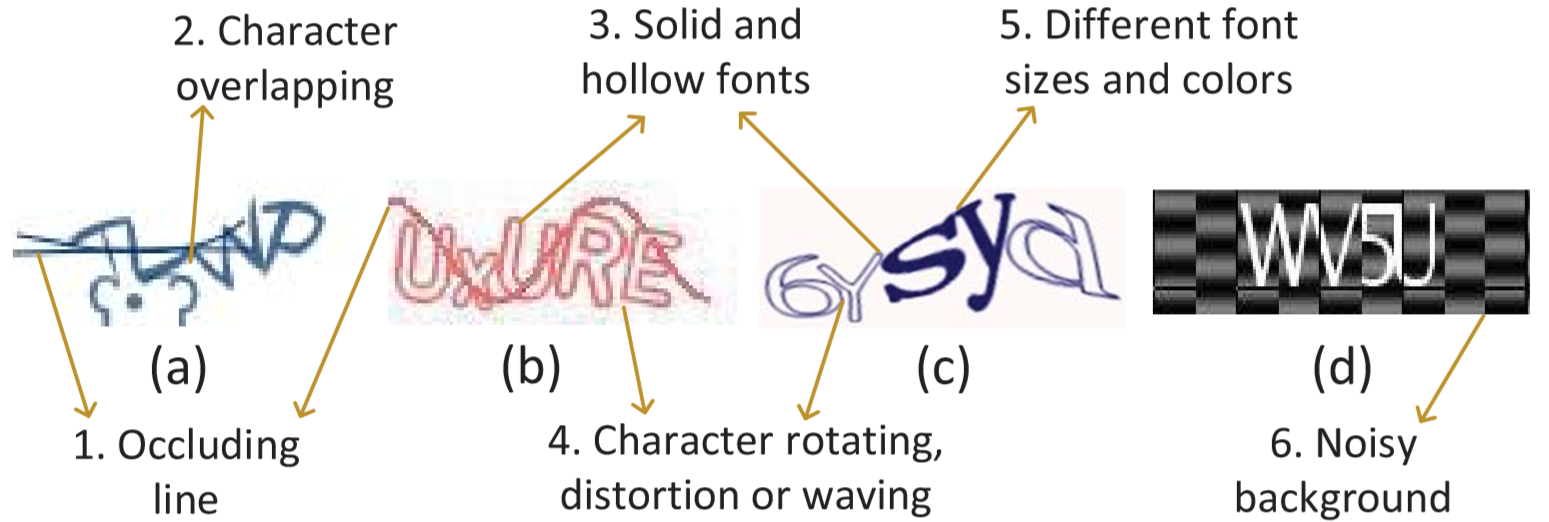
作者在引言后写了背景介绍,篇幅极短,主要介绍文中使用的六种被普遍使用的验证码安全策略(如图2-1)和生成对抗网络是什么(后文将详细举例说明,这里不累述)。
而后便直接开始介绍文章的重点,整个模型的构建和每个部分的详细情况。当然作者非常了解我们想看到什么,所以将模型的大概框架和每个模块都做了精美的图用以解释,而我个人也做了一些图更清楚的介绍每个模块的输入和输出,以便读者理清作者的模型前后关系。
2.1 整体模型

-
① 用极小的目标验证码数据集,通过生成对抗网络方法训练验证码合成器,而后由图片合成器自动合成大量与真实验证码非常相似的验证码,以及干净的验证码(没有前面提到的六种验证码安全特征)。
-
② 用合成的验证码和干净的验证码训练预处理模型,这个模型最终效果是输入带有安全特征的验证码图片,输出一个自动去除了安全特征并标准化字体样式后的“干净验证码”。
-
③ 将合成验证码输入到训练好的预处理模型,产生大量”干净验证码“用于训练基础求解器
-
④ 将真实验证码输入到训练好的预处理模型,产生少量”干净验证码”,通过迁移学习微调基础求解器,得到最终的微调求解器。
看完整个获得求解器的过程后,也许你会有很多疑问,验证码合成器是怎么做到生成与真实验证码极其相似的图片的?,验证码合成器生成的干净验证码和预处理模型输出的干净验证码有什么区别,为什么要用迁移学习微调一次,不用行吗?接下来让我们详细解析各个模型,解开这些疑惑,看看作者的idea究竟有多巧妙
2.2 验证码合成器
还记得我们之前动机里面提到了Science也有验证码领域的文章吗,作者在原文中简述道:science的文章展示出,构建一个基于CNN的有效验证码求解器需要超过230万张不同的验证码,但对于这么大的数据集,收集数据和打标签工作是非常耗费人力的工程,所以我们提出了一种最小化人力投入的方法——验证码合成器,让机器自动合成百万级数量的验证码,还都带有标签。
根据作者的描述和原文图片,我做了一个更有容易理解前后关系的图片(如图2-3所示)
- 1、根据目标验证码方案的字符集设置(英文、数字的包含情况)和字符参数设置(如颜色,位置,旋转等)自动生成不带有安全特征的验证码——这个验证码就是就是完全干净验证码,而预处理模块去除安全特征后的干净验证码可能还是有一些干扰像素点。
- 2、将不带有安全特征的验证码输入到生成器网络中——生成器网络由CNN构成,可以在像素级修改验证码,目标是生成与真实验证码相似的带有安全特征的验证码。
- 3、将合成的验证码与数据集中的真实验证码一起交给判别网络进行鉴别,目标是鉴别出哪些图片的合成的验证码图片,当判别网络的准确性低于5%时停止迭代(例如100张合成图片,只有4张被判定为合成图片);当不满足终止条件时,将分类的准确性反馈给生成网络和判别网络,以调整各自的参数。如此,生成网络和判别网络的目标截然相反,以此相互竞争,形成生成对抗网络。对生成网络而言可以不断提高合成验证码与真实验证码的相似程度;对判别网络而言,可以不断增强其鉴别图片是否为合成图片的能力。
- 4、当终止条件满足时,说明生成器网络合成的验证码图片与真实的验证码图片以及非常相似了,此时停止生成对抗网络的迭代,得到一个验证码合成器。
这里从原文中截取一个样例,展示验证码合成器的强大威力。
图2-4中,每组对比图的左边是真实验证码图片,右边是合成图片。
2.3 预处理模型(安全特征消除器)
前面的验证码合成器,已经是一个非常不错的idea,作者立马又拿出一个同样厉害的武器——基于生成对抗网络的预处理模型,目标是去除合成图片的安全特征,让其回归到便于机器学习方法识别出文字的图片。预处理模型具体流程如下图所示(图片来源于论文原文)
-
预训练:左边灰色部分,作者将验证码合成器合成的安全验证码和完全干净验证码(参见2.2节的步骤1)预先对生成网络和判别网络进行训练。(作者并未提及为什么要进行预训练,个人猜测是为了加快训练速度)
-
生成网络:右下方蓝色部分,采用Pix2Pix图片转化框架(一种可以将图片样式进行的算法),目标是去除合成验证码的噪音、横线等,并且将字体标准化(例如将中空的字体填满,将文字间距拉大等),使之于完全干净验证码相似。所以生成网络的输入是一个带有安全特征的验证码图片,输出是一个被去除了安全特征的验证码图片,例如图中的安全验证码被去除了一些横线和下方的可爱小熊图案。
-
判别网络:右上方紫色部分,将去掉安全特征的验证码和对应的完全干净验证码同时输入,让判别网络对两者进行鉴别,目标是选出被生成网络去掉安全特征的验证码。生成网络和当判别网络的目标相反,相互竞争,当判别网络的准确性低于5%时停止迭代。
-
当终止条件达成后,就要进入验证码求解器,需要强调的是,所有验证码图片输入到验证码求解器前,都要经过预处理模型,去掉其安全特征,提高识别准确率。
注意:训练预处理模型这一步非常重要,是论文模型最终能吊打其他验证码识别模型的一个关键点。
2.4 验证码求解器
所谓验证码求解器(Captcha Solvers),意思就是输入验证码图片得到其中文本的模型。这里继续使用原文精美的图片来介绍。
求解器使用LeNet-5模型进行构建,LeNet-5是一种经典的CNN模型,作者经过实验对比发现在目前的实验条件下,其他算法的效果与之差距不大,但LeNet-5简单高效,并且在迁移学习时对数据集大小的要求最低。
(a)步骤——训练基础求解器
-
将大量的合成图片经过预处理模型的处理后,去除了安全特征,再输入到基础求解器进行训练。
-
这一部分使用了20万张合成验证码图片,因为每张合成验证码图片在合成时即可自动设置标签,所以极大的减少的人力投入,另外增强了整个模型的自动化实现能力。
(b)步骤——迁移学习
-
作者在基础求解器训练完成后,考虑到基础求解器的训练数据全部来自于合成图片,容易对合成图片的特征过拟合,另外迁移学习对LeNet-5模型后部分进行训练,可以提高模型的实施效果
-
原文引用参考文献指出: The idea of transfer learning is that in neural network classification, information learned at the early layers of neural networks (i.e.closer to the input layer) will be useful for multiple classification tasks. The later the network layers are, the more specialized the layers become.
-
文章的实验部分也提供数据进一步证明,微调参数后,对模型的识别准确率有较大的提升。
到这里文章的模型详情就介绍完毕了,下面给一张图示例作者的模式识别验证码的完整过程
3 精彩的实验
之前也提到了,作者的实验对象是Alexa评出的2018年最受欢迎的50个网站中的32个,而这32个网站中有些网站使用了相同的验证码方案(例如Youtube使用Google的安全验证码方案,Live、Office和Bing使用的是Microsoft的安全验证码方案),所以不需要重复实验,而各种验证码方案又又不同的字符集,所以作者整理数据后分别做了实验。先展示一下作者的模型在各种安全验证码上的识别准确率和耗时,如图3-1。
可见微调后,模型的识别准确率有较大的提升,且用时极低,如前面所言0.05s以内完成识别工作。那么我们再来看看这些验证码方案大概是什么样子的,以及验证码求解器犯的错误(如图3-2所示)。
其实作者给出这张图的意思是想说,他们设计的模型已经非常优秀了,这些识别错误的地方其实对人而言识别起来也是比较困难的。
3.1 与其他模型的对比
作者主要从验证码识别准确率和验证码安全特征去除效果两个方面与前人的成果进行了对比
3.1.1 对比识别验证码的准确率
这里与四个前人研究成果进行了对比,第一种是2011年发表在CCS,第二个是2016年发表在NDSS,第三个是2014年发表在USENIX WOOT,第四个是2017年发表在science,在下方表格中的顺序依次为左上、右上、左下、右下。
从图中可以看出作者的研究成果,相对于前人的方法有非常大的提升,在后面的实验种,作者这套识别模型甚至与人的识别准确率不相上下。
3.1.2 对比其他去除安全特征的方法
其实去除验证码的安全特征的想法并不是作者首创,但作者的预处理模型实现了更好的去除效果,而去掉安全特征后,深度学习算法会更容易的识别出图片种的文字,因此在最终的识别准确率上相对于其他模型会有有较大提升。图3-4和3-5展示了作者与其他去除安全特征模型的对比,图3-6展示了预处理模型去除安全特征和标准化字体的效果。
(a)是百度验证码方案的真实图片,(b)(c)(d)是不同设置下的安全特征过滤方案输出效果,(e)是预处理模型的输出,这里差距明显。
图3-5是预处理模型与文献[16]的模型除去安全特征的对比。图3-6则是是单独列出的一些预处理模型的处理效果,其中每一个组对比图的左边是合成验证码图片,右边是预处理模型去除安全特征后的验证码图片。可以明显看出,作者的预处理模型不光能够准确地消除安全特征,还能填充中空的文字,并且还有为各个字符增加间隔的能力。
3.2 最佳参数探索实验
这一小节主要介绍实验思路,展示作者对自己的模型进行了哪些参数和阈值的思考。
- 在迁移学习中,从不同的验证码方案观察改变真实图片的数量和微调参数的层对最终识别准确率的影响,最终得出使用500张真实图片进行参数的微调,且微调参数的层是第二个卷积层到最后效果最好,如图3-7&3-8。
- 在两个生成对抗网络中,从不同的验证码方案观察修改迭代终止阈值对验证码识别准确率的影响,最终确定迭代的终止条件是当判别网络的准确率低于5%时效果最好,如图3-9。
- 不同的安全特征对识别准确率的影响如何?如图3-10。
作者对这三个问题分别进行了实验,得出了相应的结果,500张图片、从第二个卷积层到最后进行微调、阈值为5%是最佳选择。而安全特征越多,验证码就越难以识别,但另一方面,验证码的可用性也会降低。
图3-10可见,虽然验证码安全特征变复杂可以降低模式的识别准确率,但验证码的可用性明显降低。
3.3 验证码可用性探究实验
上一小节中,作者的实验已经证明:安全特征越复杂,模型的的识别准确率会降低,但另一方面,验证码越复杂,它看起来似乎越不可用。作者指出,验证码应该被设计成能让人轻松识别但机器却非常困难。于是作者做了如下实验,探索可用性和安全性的平衡点,实验设置每张图人最多可用观察30秒,机器则只识别一次,而人观察后还需要对每张图得可用性进行评分,分值区间为1-5。
从图中可见,作者的识别模型在准确率上几乎与人得识别准确率相差无几,只有当安全特征变得复杂时两者才有一定差距,但此时验证码也变得对用户不友好。
4 结尾
作者将相关工作介绍、讨论和总结都放在了实验部分的后面,一般来说相关工作的介绍都是放在引言之后,而文章结构这样设计的原因估计也是想尽快让读者了解到他们的模型是如何构建的,进一步引导出模型的设计有哪些思考。
个人总结
文章的书写还是很流畅的,最关键的是提出了三个非常好的想法
- 基于生成对抗网络训练出一个验证码合成器,自动化合成验证码图片且带有标签,极大的减少了人力投入,提高了验证码攻击的自动化部属能力。
- 基于生成对抗网络训练出一个验证码的预处理模型,自动化去除验证码图片的安全特征,便于识别模型进行识别,提高识别的准确率。
- 使用迁移学习,让模型学习真实验证码图片的特征,微调参数,防止过拟合,获得了非常好的效果。
虽然我也不熟悉验证码攻击领域的研究现状,但作者的idea、实验设计、文章的书写和精美简洁的示例图片都是非常棒的,特别是原文中的图片,真的是制作精美,便于读图理解。
文章的一些小瑕疵可能在于写作的逻辑,例如在介绍生成对抗网络模型设计时,讲述完模型的设计后立马指出了最终效果,但之后却在介绍模型迭代的终止条件是什么,感觉逻辑不太对劲。
总体而言,文章提出的验证码攻击模型自动化部署方便,验证码识别准确率高,针对具体的某种验证码方案有极大杀伤力(例如,结合爬虫对验证码不断识别,因为耗时较短,计算代价也相对较小,所以可用对某些网站实施撞库攻击等)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号