

团队作业3--需求改进&系统设计
0.作业声明
| 这个作业属于哪个课程 | 信安1912-软件工程 (广东工业大学 - 计算机学院) |
|---|---|
| 这个作业要求在哪里 | 团队作业3--需求改进&系统设计 |
| 这个作业的目标 | 需求&原型改进、系统设计、Alpha任务分配计划、测试计划 |
1.作业gitee链接
2.团队展示
1、队名:is-good-bro
2、队员学号
| 队员 | 学号 |
|---|---|
| 陈梓浩(组长) | 3119005455 |
| 罗行健 | 3119005470 |
| 黄浩 | 3119005414 |
| 何子阳 | 3119005413 |
| 苏泽 | 3119005473 |
3、拟作的团队项目描述:基于知识图谱的医疗问答机器人
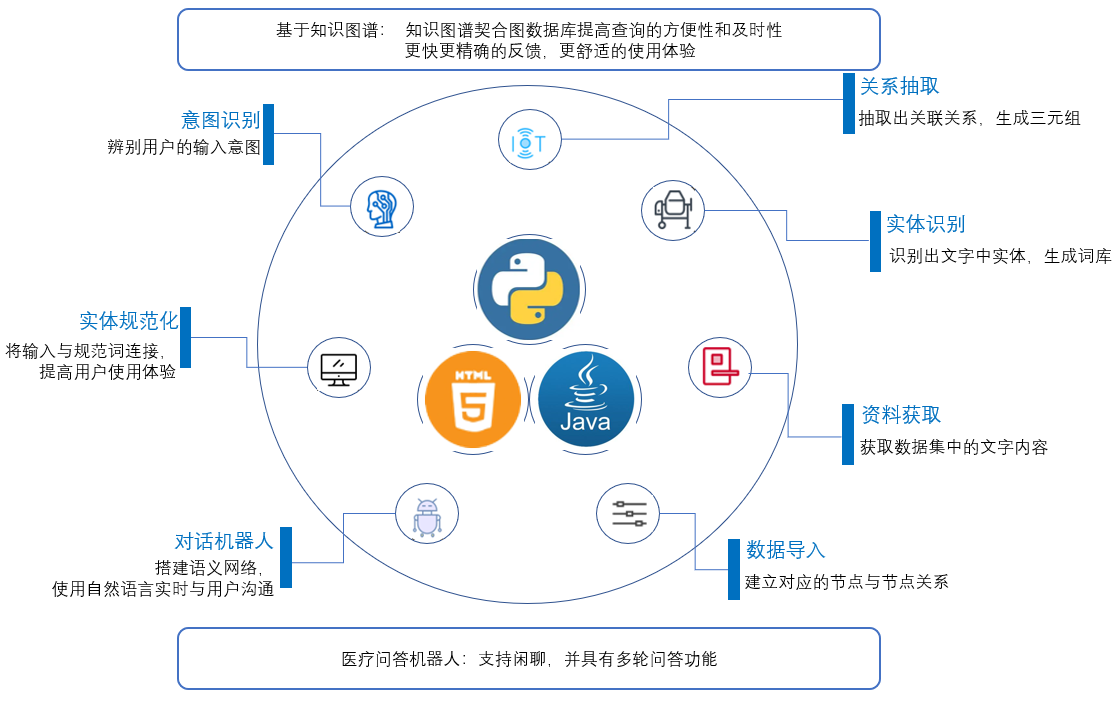
3.需求&原型改进:
1、针对课堂讨论环节老师和其他组的问题及建议,对修改选题及需求进行修改
问题1:数据来源是否能确保准确性
修改1:实体识别模型训练数据集采用ChineseBLUE中的cMedQANER数据集,关系抽取模型训练数据集采用baiduie数据集,实体规范化模型训练数据集采用yidu-n7k数据集,意图识别模型训练数据集采用CMID数据集
问题2:用户如何能使用到本产品
修改2:使用前端交互界面,后端将项目部署到服务器上,提供web端供用户进行使用
问题3:web端存在很多不便性,如何让项目更能推广出去
修改3:团队成员研究更多的使用途径,并开始尝试开发微信聊天端
2、修改完善上周提交的需求规格说明书
上周提交的需求规格说明书中,只是浅谈了不同用户人群的需求状况,这里进行详细描述:
面向学龄儿童,由于人口老龄化趋势导致年轻人的压力增大,越来越多的年轻人选择外出打拼,将孩子交给祖辈看护,但是祖辈的科学知识并不充裕,存在很多封建土方,比如孩子发烧通过厚被闷汗出热治病,但是这其实没有任何正效应,甚至可能导致加重发烧,需要一个准确的医疗诊断机器人,避免因误判或过晚发现身体上的异常,容易造成不可估量的无法挽回后果
面向青年群体,青年身体有异常习惯通过挺两天尝试自愈,但是并非每种情况都可以靠身体自愈,而且为了方便,通常选择网络查病,但例如百度,经常随便一问都是癌症征兆或者晚期,不仅没实际效果,而且会导致心理焦虑,需要一个即时的医疗咨询机器人,及时保障自身健康
面对中老年群体,他们的记忆力下降,容易忘记药物的服用时间和剂量频率,需要一个便捷的医疗问答机器人,防止影响治疗效果
3、参考《构建之法》5节功能的定位和优先级,给出功能分析的四个象限
| 外围功能 | 杀手功能 | |
|---|---|---|
| 必要需求 | 基本的症状问病功能 | 独特的并发症和宜忌食物查询功能 |
| 辅助需求 | 拓展的药品查询功能 | 缓存对话信息,支持多轮对话功能 |
4、根据修改后的需求,调整任务分解WBS及相应的项目进度计划
| 第9周 | 1.团队组队、团队博客 |
|---|---|
| 2.团队介绍、成员展示、角色分配、选题确定 | |
| 3.制定团队计划安排,团队贡献分的规定 | |
| 4.原型设计,队员估计任务难度并开始学习必要的技术 | |
| 第10周 | 1.需求规格说明书 |
| 2.队员完成基础知识的学习 | |
| 3.完成系统基本编码、服务器调试、基本架构 | |
| 第11周 | 1.原型改进(给目标用户展现原型,并进一步理解需求) |
| 2.架构设计,WBS | |
| 3.已有模块测试 | |
| 第12、13周 | 1.团队项目Alpha任务分配计划 |
| 2.连续7天的Alpha敏捷冲刺,7篇每日Scrum Meeting博客+代码提交 | |
| 3.第一次正式使用测试 | |
| 第14周 | 1.第二、三次正式使用测试 |
| 2.团队Alpha阶段个人总结 | |
| 3.团队项目Alpha博客:发布说明、测试报告、展示博客、项目管理 | |
| 第15周 | 1.团队项目Alpha博客:事后分析 |
4.系统设计
1、系统的架构设计
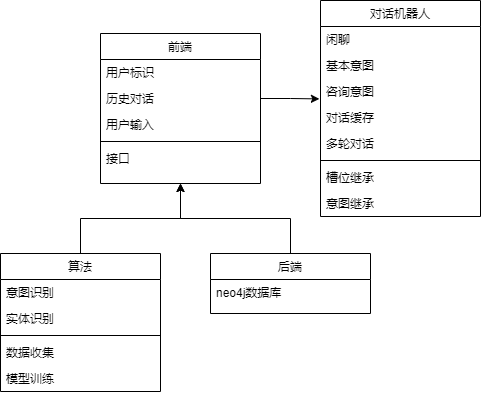
| 功能模块 | 实现需求解决说明 |
|---|---|
| 前端 | 提供输入界面和输入方法,获取用户输入 |
| 后端 | 使用Java语言进行设计开发,使用版本为Java11。在设计过程中采用了SpringBoot框架进行开发,期间调用了Neo4j图形数据库进行数据存储,后续通过Java语言设计接口,实现了对数据库中节点数据的模糊搜索 |
| 实体识别 | 使用BILSTM-CRF模型对用户输入进行命名实体识别预测,识别出用户输入中疾病、器官、症状、人群、治疗、时间等实体,提供给后期对话机器人使用 |
| 关系抽取 | 使用CasRel模型对病症数据进行实体关系抽取预测,抽取出病症数据中疾病、器官、症状、人群、治疗、时间等实体的关联关系,生成三元组,保存为关系文本文件,提供给后期数据导入作为预处理后的数据使用 |
| 数据导入 | 将实体识别生成的词库文本文件和关系抽取获得的关系三元组文本文件,使用python编写批处理程序,先使用词库在neo4j图数据库建立对应的节点,并将关系三元组中的内容以此使用CQL语句向neo4j数据库输入,建立节点之间的关系,提供给后期对话机器人使用 |
| 实体规范化 | 当涉及到使用本项目进行查询相关信息时,为减少误输和错输对用户产生的体验影响,使用bm25算法+esim模型进行实体规范化训练,收集常错输入与规范词的数据,如将“你好”误输为“nihao”,将输入与规范词进行实体连接,使得即使错输部分词语也能正确反馈,提供给后期对话机器人使用 |
| 意图识别 | 使用bert+textCNN模型进行意图识别训练,可以用来辨别用户的输入意图是什么,如用户输入“你好”,对话机器人可以识别出这是问好意图,回复“你好,我是信息查询机器人”;用户输入“查询XXX信息”,机器人可以识别出这是查询意图,提供给后期对话机器人使用 |
| 对话机器人 | 调用前面的实体识别等多个部分,对用户的输入进行自然语言理解,得出用户的对话意图和关键词,如用户输入“心脏病是什么”,机器人就可以识别出这是查询意图,并且是查询关键词是心脏病,从neo4j数据库查询相关信息并返回给用户 |
| 对话缓存 | 将用户上一句查询意图输入经实体识别后得到的槽位信息保存,当下一句输入缺乏槽位信息时进行槽位继承,使得实现多轮对话 |
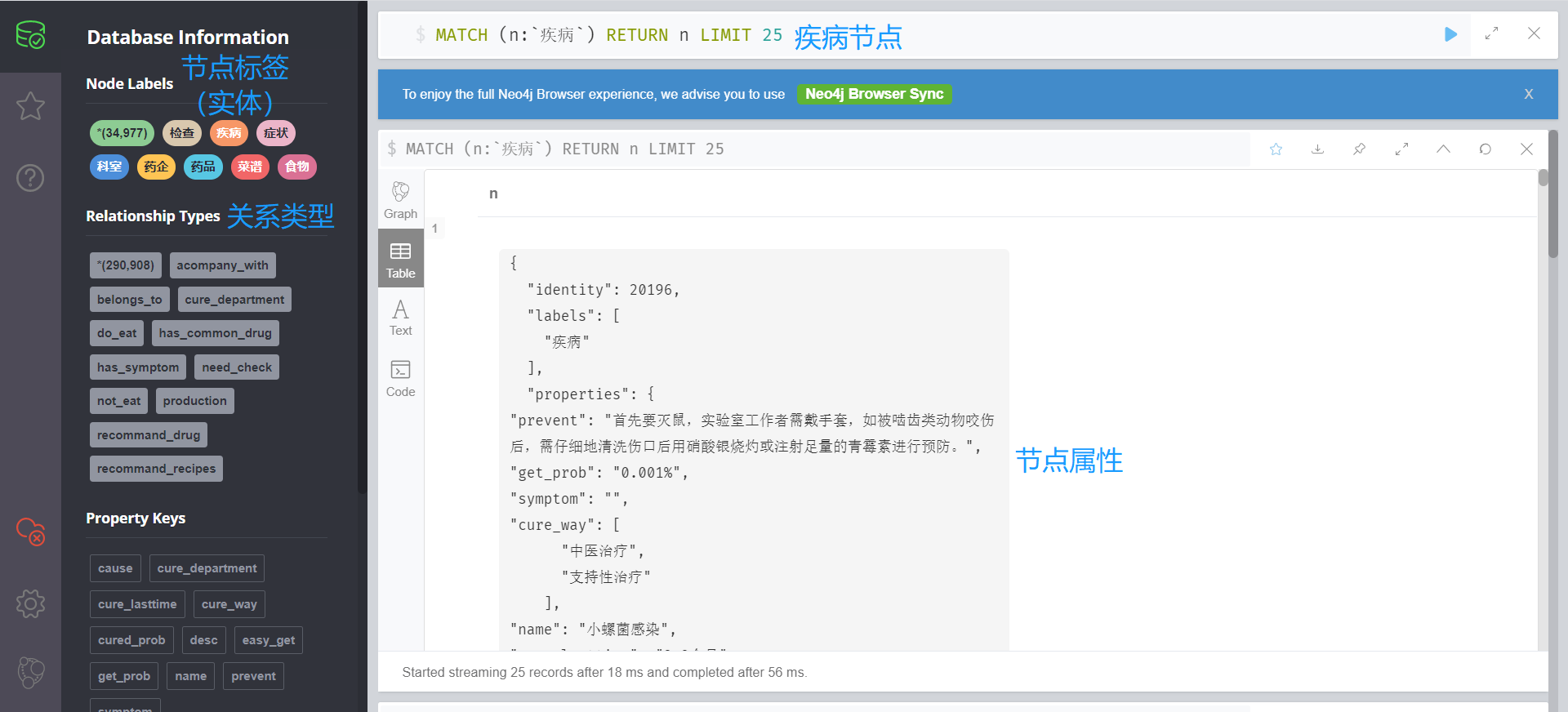
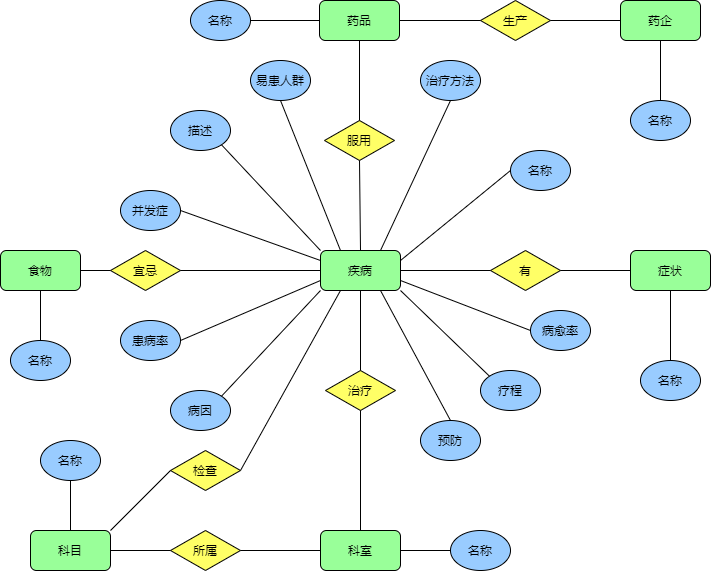
2、完成团队项目的数据库设计,并在提供相应ER图
由于本项目使用的数据库为neo4j,无需定义属性的数据类型,此处截图以做展示
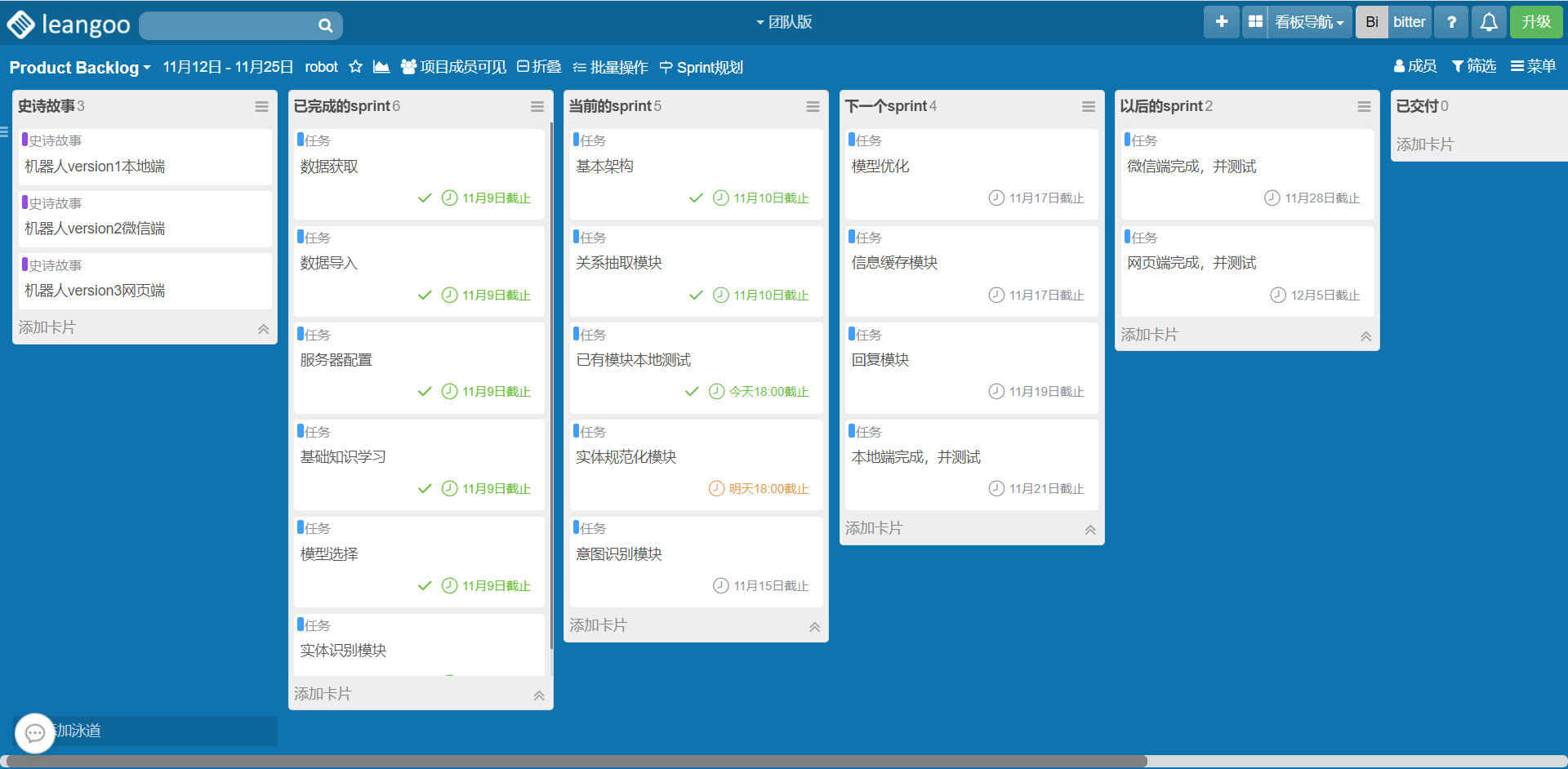
5.Alpha任务分配计划
1、依据项目组能提供的总时间、功能模块的优先级以及模块之间的依赖关系,在Product Backlog中选取待实现的功能项
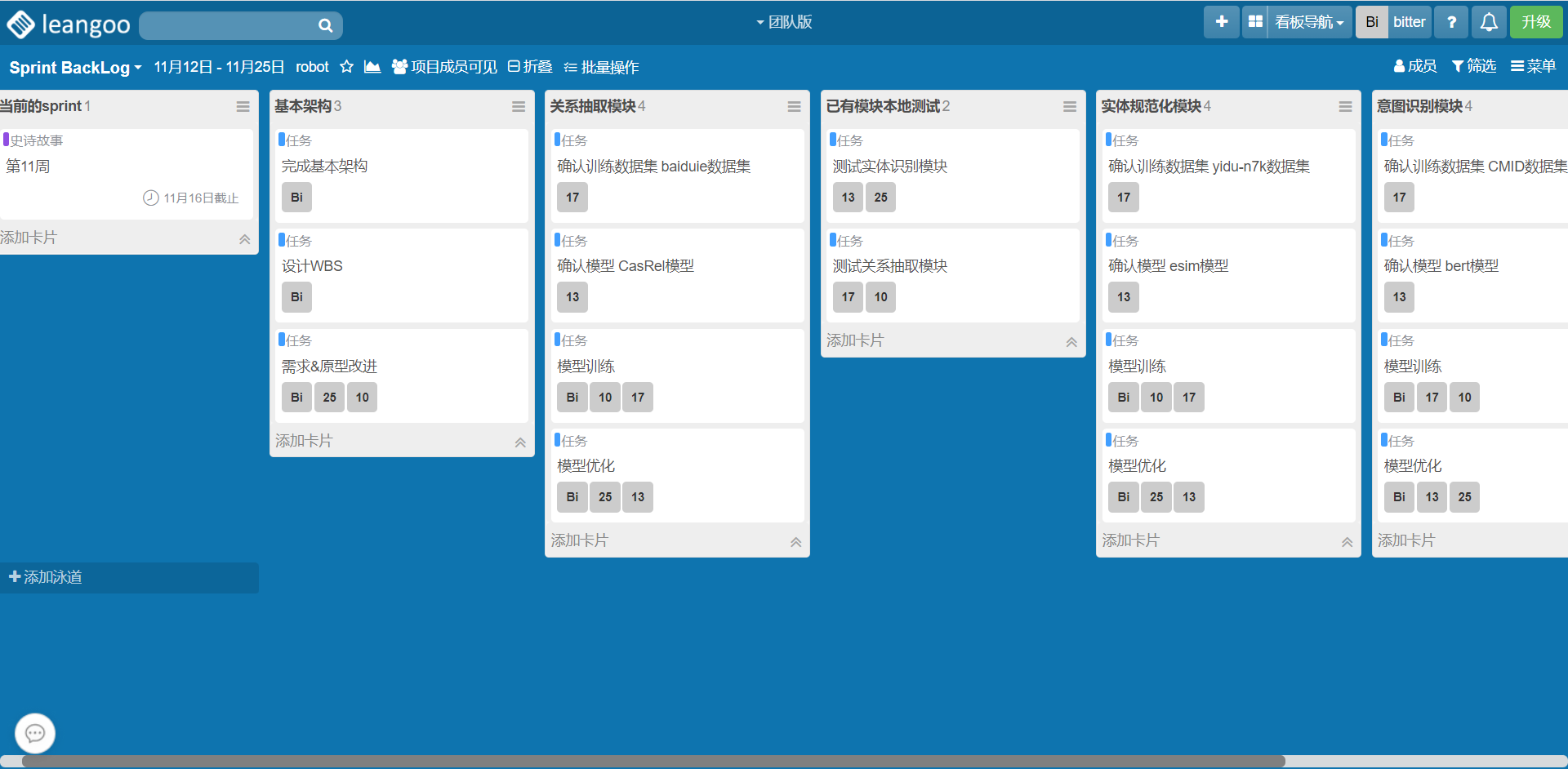
2、对已选择的功能项再做进一步分解,分解为1-10小时左右的任务,构成Sprint Backlog。在PM的协助下,编码的同学对任务进行认领
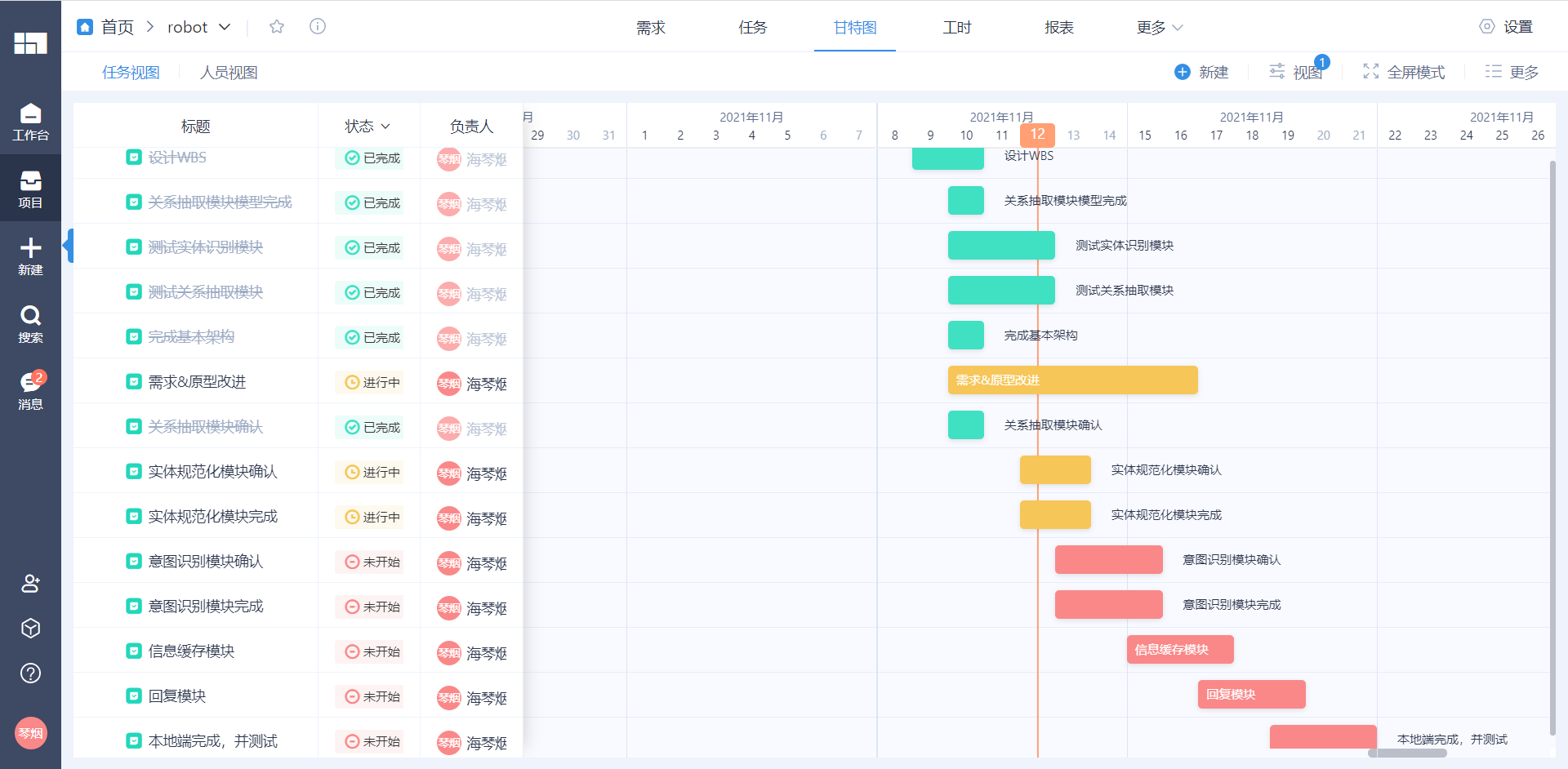
3、以甘特图的方式拟定迭代冲刺计划
此处由于截图展示不便,故将上图细致分时的子任务进行一定的合成,作出下图,使用软件为Worktile
6.测试计划
1、产品背景与定义
针对学龄儿童需要一个准确的医疗诊断机器人,青年群体需要一个即时的医疗咨询机器人,中老年群体需要一个便捷的医疗问答机器人的时代发展背景,我们开发一个基于知识图谱的医疗问答机器人,要求医疗数据包含疾病的定义、症状、治疗方法,拓展疾病的忌吃食物、宜吃食物、通用药品、推荐药品、并发症、治疗科室;要求辨识用户,识别用户输入内容中的意图、实体,缓存用户对话信息,并支持槽位继承和意图继承实现多轮对话
2、测试定义与目的
此次测试为已有模块测试,目的在于对目前已开发好的两个模块,实体识别模块、关系抽取模块,进行测试,测试模块一是否能对输入内容进行实体识别,分割出文字中的实体,测试模块二是否能抽取出文字中的实体关系,测试要求广泛收集测试数据,确保测试的客观准确性,提高测试可信度,并据测试结果向开发人员反馈意见
3、测试工具与环境
测试工具:Pycharm
测试环境:
python==3.7
tensorflow==1.14.0
keras==2.3.1
bert4keras==0.10.6
h5py==2.8.0
3、测试时间与人员
| 测试内容 | 测试时间 | 测试人员 |
|---|---|---|
| 实体识别模块 | 3天,11.10-11.12 | 罗行健、苏泽 |
| 关系抽取模块 | 3天,11.10-11.12 | 黄浩、何子阳 |
| 模块衔接测试 | 1天,11.12 | 陈梓浩 |
4、测试资源
每项测试,测试数据均为200条,30%为测试人员结合自身生活生成,40%为网络收集,30%为交叉测试人员生成,例如实体识别模块,测试数据为“我昨天晚上肠胃炎犯了,而且头痛”,实体识别模块识别出“肠胃炎”疾病实体和“头痛”症状实体,关系抽取模块测试数据“昨天晚上的肠胃炎,导致我肚子痛”,模块识别出“肠胃炎”是“肚子痛”的原因,模块衔接测试则为使用实体识别,扩大关系抽取模型可利用的实体,进而识别出更多的实体关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号