理解两种变量模型以及三种传参模式
在学习 Python 过程中,关于引用式变量与对象之间的关系,以及 Python 社区中习惯于被称呼为共享传参(Call by sharing)的传参方式,感觉上和之前接触的 C/C++ 不同,但具体的本质区别是什么呢?本文主要总结了从 C → C++ → Python 学习过程中,如何理解变量和值之间的关系以及相应的传参模式,最后简要补充了函数返回相关的疑惑。
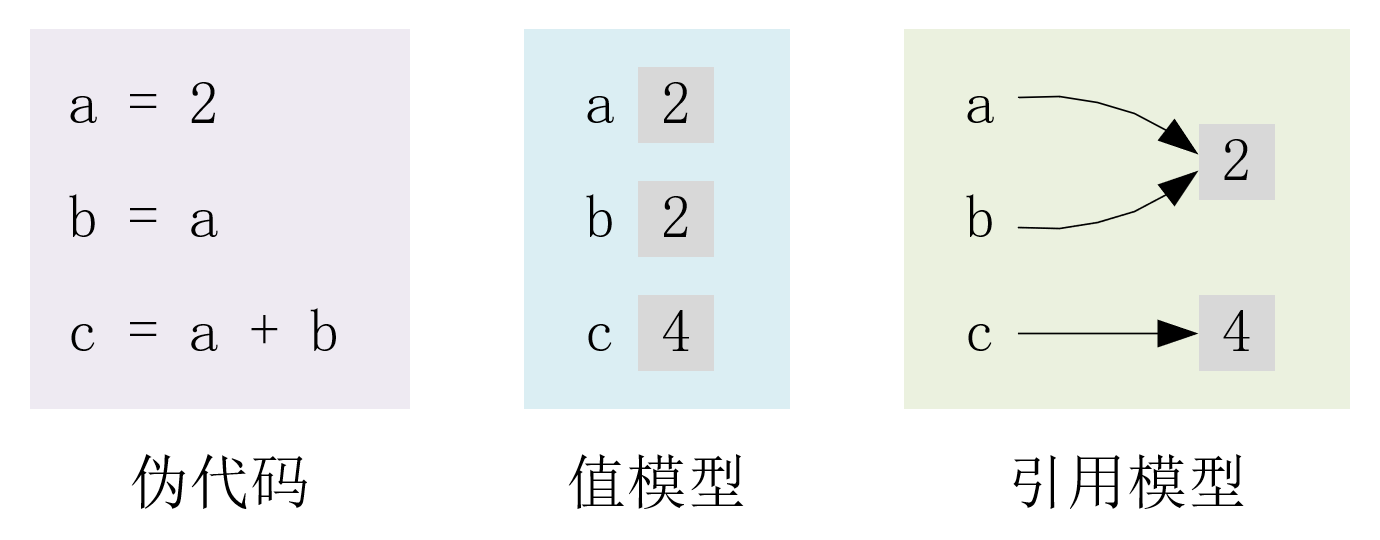
1. 变量是盒子
在 C 语言中,什么是数据类型呢?数据类型可以理解为固定内存大小的别名,数据类型就是创建变量的模子。int a;实际上通过定义变量a申请了一段连续存储的空间,并命名为a,后续通过变量的名字a便可以使用该存储空间。所以在 C 语言中,不同的变量就是不同的盒子,用来存储各自的数据。定义指针也是普通的变量,只不过这个盒子中存储的是地址数据。
#include <stdio.h>
int main(void)
{
int a = 10;
int b = a;
// 变量 a 和 变量 b 的地址不同
printf("addr[a]=0x%p, addr[b]=0x%p\n", &a, &b);
return 0;
}
在 C 语言中,每定义一个变量名都创建一个不同的盒子,这个盒子具有固定的内存地址;而所谓的数据类型,就是固定内存大小的别名,也就是用来决定盒子的大小。
在 C 语言中,函数实参的传参方式只有一种,即按值传递(Call by value),也就是说实际参数会被求值,然后将其值绑定到函数中对应的变量上(通常是把值复制到新内存区域),即传递的是值,而非变量本身;同理,返回值也是按值传递(Call by value)的,即return x;返回的是变量x的值,而非变量本身,因为变量x马上就要被释放了。
2. 不是所有变量都是盒子
在 C++ 中,除了和 C 语言相同的部分外,新增加了引用的概念。C++ 中的引用只能在定义时被初始化一次,之后不可变。实际上,C++ 中的引用的内部实现是一个常指针,即Type &name = var⇔Type *const name = &var,比如int &A = a;⇔int *const A = &a;;也就是说,引用一个变量,就相当于指向这个变量的指针,只不过这个指针本身不可变,而指向的数据可变,即可以通过解引用*A来改变变量a的值;而在 C++ 中int &A = a;,使用时可以直接操作A(无需解引用),就可以修改变量a,A就像变量a的别名一样。即变量A是对变量a的引用(别名),虽然 C++ 编译器对A和a的内部实现方式不同,但从使用的角度,A和a之间没有任何语义上的区别,可以应用于他们的操作完全一样,得到的结果也完全一样;同时,对A或a的任何修改都可以从对方看到。所以从使用的角度而言,C++ 中定义的变量,并不都是创建了盒子,引用作为一个已定义变量的别名而存在。
#include <stdio.h>
int main(void)
{
int a = 10;
int &b = a;
// 变量 a 和 变量 b 的地址相同
printf("addr[a]=0x%p, addr[b]=0x%p\n", &a, &b);
// 对于 a 或 b 的任何修改都可以从对方看到
b = 20;
printf("a=%d, b=%d\n", a, b); // a=20, b=20
return 0;
}
在 C++ 中,存在基本类型的变量(值变量),可以看成不同的盒子;也存在引用变量,通过在名字前面放一个&符号来区别,如int &b = a;,b就是一个引用变量,可以看成变量a的别名,b和a可以看成是同一个盒子。
因此,在 C++ 中,函数的传参方式组合了传值调用(Call by value)和传引用调用(Call by reference)。在传引用调用(Call by reference)求值中,传递给函数的是实参的引用而不是实参的值拷贝,通常函数能够修改这些参数(比如赋值),而且该改变对于调用方而言是可见的,即传引用调用(Call by reference)提供了一种调用方和函数交换数据的方法。如下示例,实现交换两个变量的值:
#include <stdio.h>
void swap_1(int *a, int *b)
{
int t = *a;
*a = *b;
*b = t;
}
void swap_2(int &a, int &b)
{
int t = a;
a = b;
b = t;
}
int main(void)
{
int a = 10;
int b = 20;
printf("a=%d, b=%d\n", a, b);
swap_1(&a, &b);
printf("a=%d, b=%d\n", a, b);
swap_2(a, b);
printf("a=%d, b=%d\n", a, b);
return 0;
}
也就是说,虽然 C 语言缺少引用参数,但总可以通过指针来修改变量。即在 C 语言中,若要修改变量,实参可以传入变量的地址值,此时要求形参必须是指针,且在使用时必须显式的做间接操作。C++ 引入了一种显式的引用记法,即通过&符号,形参可以被描述为引用参数,如上述代码void swap(int &a, int &b) { int t = a; a = b; b = t; },子程序swap代码中的a和b是int,而不是指向int的指针,不需要对他们做间接操作,而且在调用时,也只需将需要交换值的变量名字传入即可,而不再需要传入他们的地址。
注意:在 C++ 中,声明引用变量需要显式的在名字前面放一个&符号,且引用只能在定义时被初始化一次,之后不可变,所以其仅仅作为一个已定义变量的别名而存在,而实际很少有理由需要在直接代码中创建别名,因此,C++ 中引用的主要用途是修饰函数的形参和返回值,使用引用既具有指针的效率,又具有变量使用的方便性和直观性。
补充:Java 对内部类型使用值模型,对用户定义的类型(类)使用引用模型,其引用式变量与 C++ 中的引用用法不同,比如不需要特殊的语法来显式定义为引用变量,且定义后可变(之后允许重新赋值);另外,C# 和 Eiffel 允许程序员为每个用户定义的类型选择使用值模型或者引用模型;C# 中的class使用引用模型,而struct使用值模型。【并不了解 Java、C# 及 Eiffel,在这里注记一下方便后续查阅】
3. 变量不是盒子
在 C/C++ 中,int a = 10;、int b = a;,这里a和b是两个不同的变量,有不同的内存地址,只不过存储的数据值相同而已;而在 Python 中,若有a = 10、b = a,则b is a结果为True。也就是说 Python 不是使用变量的值模型的语言,而是使用变量的引用模型的语言,即 Python 中的变量本身已经是对象的引用。因此,“变量是盒子”这样的比喻,将有碍于理解类似 Python 这种面向对象语言中的引用式变量。在 Python 中,最好把变量理解为附加在对象上的标注(便利贴),而不是盒子,而且可以为同一对象贴上多个标注(便利贴),而所贴的多个标注,就是别名。如下示例(图片来源于《流畅的 Python》),变量b和变量a引用同一个列表对象,b并不是列表a的副本:

实际上,在处理不可变的对象时,变量保存的是真正的对象(盒子)还是共享对象的引用(便利贴)无关紧要,关于 Python 可变性的相关内容不在本文讨论范围之内。
在 Python 中,由于变量本身保存的都是引用,这一点对编程时有很多实际的影响:
- 变量之间的简单赋值不会创建副本(如
b = a,不会创建a的副本)。 - 对
+=或*=所做的增量赋值来说,如果左边的变量绑定的是不可变对象,会创建新对象;如果是可变对象,会就地修改。 - 为现有的变量赋予新值(赋值语句),不会修改之前绑定的变量,这叫重新绑定:现在变量绑定了其他对象。如果变量是之前那个对象的最后一个引用,则之前那个对象会被当作垃圾回收。
- 函数的参数以别名的形式传递,这意味着,函数可能会修改通过参数传入的可变对象。这一行为无法避免,除非在本地(函数内)创建副本,或者使用不可变对象(例如,传入元组,而不传入列表)。
关于传参方式,既然变量本身保存的是对象的引用,那么最自然的做法就是传递引用本身,并让实参和形参引用同一个对象。在 Python 中,唯一支持的参数传递模式是共享传参(Call by sharing),即函数的各个形式参数获得实参中各个引用的副本;也就是说,函数得到参数的副本,但是参数始终是引用。因此,如果参数引用的是可变对象,那么对象可能会被修改,但是对象的标识不变。【注:因为函数得到的是参数引用的副本,所以重新绑定(赋予新值)对函数外部没有影响。】有如下示例:
def f(l):
l.append(10)
l = [20]
m = []
f(m)
print(m)
变量m是列表[]的引用,调用f(m),引用的副本传给形参l,现在函数内的局部变量l和函数外部的变量m引用了同一个列表对象[],又因为列表是可变对象,所以append方法修改了对象,而l = [20]为局部变量l赋值(赋值是给变量绑定一个新对象,而不是改变对象),现在局部变量l绑定了新的对象(即重新绑定),这将对函数外的作用域没有影响,因此,最后打印m,会输出[10]而不是[20]。
在解释 Python 中参数传递的方式时,人们经常这样说:“参数按值传递,但是这里的值是引用”。这么说没错,但是会引起误解,因为在旧式语言中,最常用的参数传递模式有按值传递(Call by value)和按引用传递(Call by reference):
- 而共享传参(Call by sharing)与按值传递(Call by value)的不同之处在于,虽然我们确实将实参复制到形参中,但实参和形参都是引用的,因此如果我们在函数内修改了参数引用的对象(如果是可变的话),那么将可以通过实参看到这些修改【当然,对于不可变对象,实际上共享传参(Call by sharing)和按值传递(Call by value)之间并没有真正的区别】。
- 此外,共享传参(Call by sharing)还与按引用传递(Call by reference)不同,因为函数并不会访问变量本身(例如为变量赋值只是重新绑定),而只是访问具体的共享对象(参数所引用的对象)【The semantics of call by sharing differ from call by reference because access is not given to the variables of the caller, but merely to certain objects】,如下示例,分别是 C++ 和 Python 代码,用来对比
Call by sharing与Call by reference的不同:
#include <stdio.h>
void f(int &x)
{
x = 20;
}
int main(void)
{
int a = 10;
f(a);
printf("a=%d\n", a);
return 0;
}
def f(x):
x = [20]
a = [10]
f(a)
print(a)
我们尝试在函数内部为形参变量赋值:C++ 打印结果a=20;而 Python 打印结果为[10]。这是因为:按引用传递(Call by reference)的本质其实就是函数得到参数的指针,从而访问变量本身;而共享传参(Call by sharing)函数得到的是参数引用的副本,从而使形参和实参引用同一个共享对象,所以函数内的赋值对外部并无影响,而只是将形式参数绑定到一个新对象(参考上文),也就是说,传递变量仅意味着传递变量所引用的实际对象,虽然函数内可以修改此共享对象(如果是可变的话),但并不能访问传递的原始变量本身。
4. 对比函数返回
既然 Python 变量保存的是引用,那么函数内局部变量新绑定的对象为什么可以作为返回值被返回而不像 C/C++ 一样会变成“野指针”呢?这是因为内存管理的方式不同:Python 中的对象绝不会自行销毁(会由垃圾回收器进行回收);而 C/C++ 中不同的变量(如栈变量、静态变量等)有着不同的生命周期。
在 C/C++ 中,需要我们手动进行内存管理,有栈变量、堆变量、静态变量、全局变量、生命周期等等概念;而在 Python 等更高级的语言中,一般会有垃圾自动回收程序。例如 Python 中的对象绝不会自行销毁,仅当无法得到对象时,可能会被当作垃圾回收。在 CPython 的实现中,垃圾回收使用的主要算法是引用计数,每个对象都会统计有多少引用指向自己,当引用计数归零时,对象立即就被销毁。我们现在考虑函数内局部变量的返回,这里仅作为对比不进行详细说明,分别举例代码如下所示:
- 在 C 语言中,若函数返回栈变量的指针,函数返回后将变成“野指针”,导致程序崩溃
#include <stdio.h>
char *func()
{
char p[] = "Hello World !";
return p; // Warning
}
int main(void)
{
char *s = func();
printf("%s\n", s); // OOPS !
return 0;
}
- 同理,在 C++ 中,根据上文介绍的 C++ 中引用的底层实现方式可知,若函数返回值为引用,当返回栈变量时,则不能作为左值使用,也不能成为其他引用的初始值,同样地,也可能会导致程序崩溃。
#include <stdio.h>
int &func()
{
int p = 0;
return p; // Warning
}
int main(void)
{
int a = func(); // OOPS !
int &b = func();
printf("b = %d\n", b); // OOPS !
return 0;
}
- 在 Python 中,使用变量的引用模型,有基于引用计数的垃圾回收器来进行内存管理,可以在Python Tutor中运行如下代码,注意观察
Frames与Objects的变化:
def func():
l = [3, 2, 1]
return l
func()
x = func()
x.append(0)
print(x)
参考链接:
- 可视化代码执行过程的工具
- Python Tutor(目前支持:Python, Java, C, C++, JavaScript, and Ruby)
- 变量的值模型 & 变量的引用模型
- 《程序设计语言——实践之路(第3版)》 6.1.2 赋值 → §引用和值
- 《程序设计语言——实践之路(第3版)》 7.7.1 语法和操作 → §引用模型、§值模型
- 传参方式:按值传递(Call by value)、按引用传递(Call by reference)、共享传参(Call by sharing)
- 《程序设计语言——实践之路(第3版)》 8.3.1 参数模式
- 维基百科:https://en.wikipedia.org/wiki/Evaluation_strategy
- 关于 C/C++ 中的指针解引用(
Dereference)- 关于 C++ 中的引用和指针的区别与联系
- 《高质量程序设计指南—— C++/C 语言(第3版)》 7.5 引用和指针的比较
- 文中关于 Python 的部分
- 《流畅的 Python》 7.4 变量作用域规则
- 《流畅的 Python》 第 8 章 对象引用、可变性和垃圾回收
- Python 数据模型:https://docs.python.org/zh-cn/3/reference/datamodel.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号