

Python爬虫post一例
抓取博客园(https://www.cnblogs.com/)分类列表(下图红框所示),在浏览器直接查看网页的源码,是看不到这部分内容的.
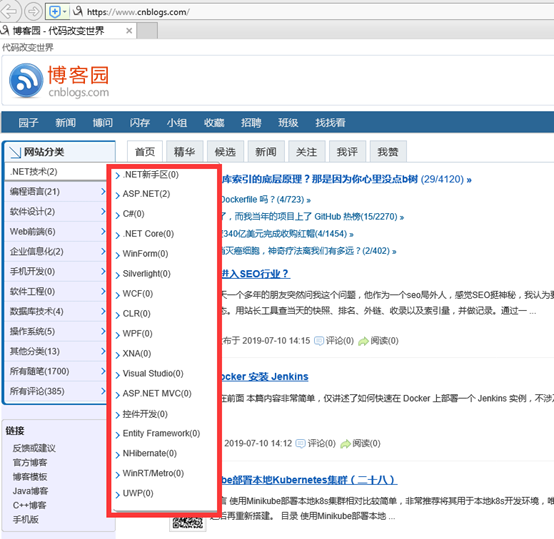
抓取方法如下:
使用谷歌浏览器,按F12,切换到Network,点击第一个按钮开始抓包.

按F5重新刷新页面,左边会出现所有请求内容.
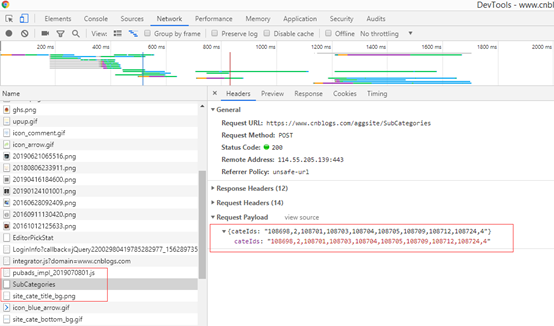
这里就需要一个一个人工查看,如下图,找到所需内容.

切换到Headers选项,可以查看到请求的类型:
方式:post
"content-type":"application/json; charset=UTF-8", "user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36", "x-requested-with": "XMLHttpRequest", "accept":"text/plain, */*; q=0.01", "accept-encoding": "gzip, deflate, br",
最下面的Request Payload就是post的数据.
from MyRequestPost import MyRequestPost#自己写的一个公用类 from lxml import etree headers = { "content-type":"application/json; charset=UTF-8", "user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36", "x-requested-with": "XMLHttpRequest", "accept":"text/plain, */*; q=0.01", "accept-encoding": "gzip, deflate, br", "accept-language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7", #"cookie": "xxx" }; data = '{"cateIds": "108698,2,108701,108703,108704,108705,108709,108712,108724,4"}' post = MyRequestPost(url="https://www.cnblogs.com/aggsite/SubCategories",headers = headers,data = data.encode('utf-8')) print(post.htmlCode);
然后输出结果如下:

这里有个小坑:
提交的数据看起来是json数据,开始我是这么写的:
data = {"cateIds": "108698,2,108701,108703,108704,108705,108709,108712,108724,4"},看起来名正言顺的json呢,但是总是返回500错误:
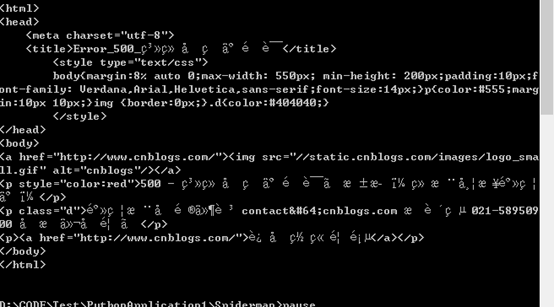
后来直接把json字符串加了引号,终于成功.
另外:
"content-type"="application/json; charset=UTF-8"的时候,数据是json数据.
Content-Type=application/x-www-form-urlencoded; charset=UTF-8,数据应该是表单数据.
例如:
data = [
(‘user’, 'xxxx'),
('password', '5xxxx'),]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号