
【Canal】互联网背景下有哪些数据同步需求和解决方案?看完我知道了!!
写在前面
在当今互联网行业,尤其是现在分布式、微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis、Memcached等NoSQL数据库,也会使用大量的Solr、Elasticsearch等全文检索服务。那么,这个时候,就会有一个问题需要我们来思考和解决:那就是数据同步的问题!如何将实时变化的数据库中的数据同步到Redis/Memcached或者Solr/Elasticsearch中呢?
互联网背景下的数据同步需求
在当今互联网行业,尤其是现在分布式、微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis、Memcached等NoSQL数据库,也会使用大量的Solr、Elasticsearch等全文检索服务。那么,这个时候,就会有一个问题需要我们来思考和解决:那就是数据同步的问题!如何将实时变化的数据库中的数据同步到Redis/Memcached或者Solr/Elasticsearch中呢?
例如,我们在分布式环境下向数据库中不断的写入数据,而我们读数据可能需要从Redis、Memcached或者Elasticsearch、Solr等服务中读取。那么,数据库与各个服务中数据的实时同步问题,成为了我们亟待解决的问题。
试想,由于业务需要,我们引入了Redis、Memcached或者Elasticsearch、Solr等服务。使得我们的应用程序可能会从不同的服务中读取数据,如下图所示。
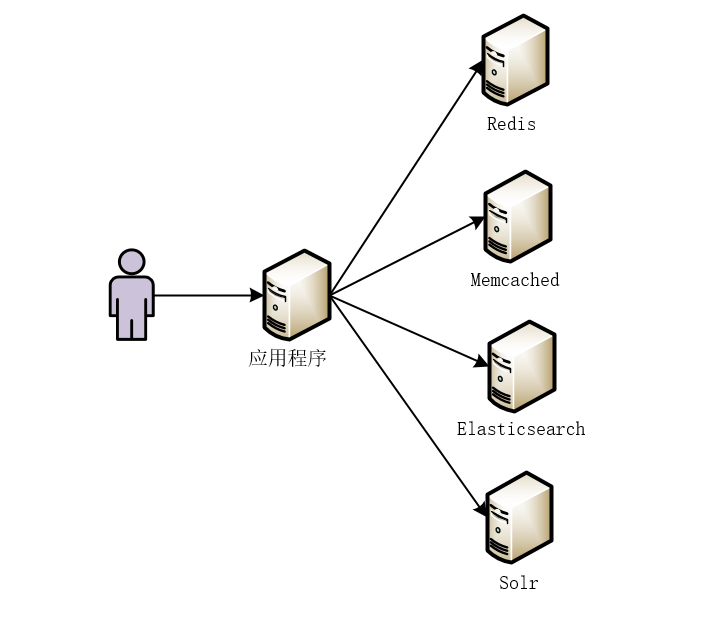
本质上讲,无论我们引入了何种服务或者中间件,数据最终都是从我们的MySQL数据库中读取出来的。那么,问题来了,如何将MySQL中的数据实时同步到其他的服务或者中间件呢?
注意:为了更好的说明问题,后面的内容以MySQL数据库中的数据同步到Solr索引库为例进行说明。
数据同步解决方案
1.在业务代码中同步
在增加、修改、删除之后,执行操作Solr索引库的逻辑代码。例如下面的代码片段。
public ResponseResult updateStatus(Long[] ids, String status){
try{
goodsService.updateStatus(ids, status);
if("status_success".equals(status)){
List<TbItem> itemList = goodsService.getItemList(ids, status);
itemSearchService.importList(itemList);
return new ResponseResult(true, "修改状态成功")
}
}catch(Exception e){
return new ResponseResult(false, "修改状态失败");
}
}
优点:
操作简便。
缺点:
业务耦合度高。
执行效率变低。
2.定时任务同步
在数据库中执行完增加、修改、删除操作后,通过定时任务定时的将数据库的数据同步到Solr索引库中。
定时任务技术有:SpringTask,Quartz。
哈哈,还有我开源的mykit-delay框架,开源地址为:https://github.com/sunshinelyz/mykit-delay。
这里执行定时任务时,需要注意的一个技巧是:第一次执行定时任务时,从MySQL数据库中以时间字段进行倒序排列查询相应的数据,并记录当前查询数据的时间字段的最大值,以后每次执行定时任务查询数据的时候,只要按时间字段倒序查询数据表中的时间字段大于上次记录的时间值的数据,并且记录本次任务查询出的时间字段的最大值即可,从而不需要再次查询数据表中的所有数据。
注意:这里所说的时间字段指的是标识数据更新的时间字段,也就是说,使用定时任务同步数据时,为了避免每次执行任务都会进行全表扫描,最好是在数据表中增加一个更新记录的时间字段。
优点:
同步Solr索引库的操作与业务代码完全解耦。
缺点:
数据的实时性并不高。
3.通过MQ实现同步
在数据库中执行完增加、修改、删除操作后,向MQ中发送一条消息,此时,同步程序作为MQ中的消费者,从消息队列中获取消息,然后执行同步Solr索引库的逻辑。
我们可以使用下图来简单的标识通过MQ实现数据同步的过程。

我们可以使用如下代码实现这个过程。
public ResponseResult updateStatus(Long[] ids, String status){
try{
goodsService.updateStatus(ids, status);
if("status_success".equals(status)){
List<TbItem> itemList = goodsService.getItemList(ids, status);
final String jsonString = JSON.toJSONString(itemList);
jmsTemplate.send(queueSolr, new MessageCreator(){
@Override
public Message createMessage(Session session) throws JMSException{
return session.createTextMessage(jsonString);
}
});
}
return new ResponseResult(true, "修改状态成功");
}catch(Exception e){
return new ResponseResult(false, "修改状态失败");
}
}
优点:
业务代码解耦,并且能够做到准实时。
缺点:
需要在业务代码中加入发送消息到MQ的代码,数据调用接口耦合。
4.通过Canal实现实时同步
Canal是阿里巴巴开源的一款数据库日志增量解析组件,通过Canal来解析数据库的日志信息,来检测数据库中表结构和数据的变化,从而更新Solr索引库。
使用Canal可以做到业务代码完全解耦,API完全解耦,可以做到准实时。
Canal开源地址:https://github.com/alibaba/canal。
重磅福利
关注「 冰河技术 」微信公众号,后台回复 “设计模式” 关键字领取《深入浅出Java 23种设计模式》PDF文档。回复“Java8”关键字领取《Java8新特性教程》PDF文档。回复“限流”关键字获取《亿级流量下的分布式限流解决方案》PDF文档,三本PDF均是由冰河原创并整理的超硬核教程,面试必备!!
好了,今天就聊到这儿吧!别忘了点个赞,给个在看和转发,让更多的人看到,一起学习,一起进步!!
写在最后
如果你觉得冰河写的还不错,请微信搜索并关注「 冰河技术 」微信公众号,跟冰河学习高并发、分布式、微服务、大数据、互联网和云原生技术,「 冰河技术 」微信公众号更新了大量技术专题,每一篇技术文章干货满满!不少读者已经通过阅读「 冰河技术 」微信公众号文章,吊打面试官,成功跳槽到大厂;也有不少读者实现了技术上的飞跃,成为公司的技术骨干!如果你也想像他们一样提升自己的能力,实现技术能力的飞跃,进大厂,升职加薪,那就关注「 冰河技术 」微信公众号吧,每天更新超硬核技术干货,让你对如何提升技术能力不再迷茫!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号