Hbase 系列(一)基本概念
Hbase 系列(一)基本概念
HBase 是 Apache 旗下一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。利用 HBase 技术可在廉价 PC 服务器上搭建起大规模的存储化集群。使用 HBase 可以对数十亿级别的大数据进行实时性的高性能读写,在满足高性能的同时还保证了数据存取的原子性。
一、HBase 基本概念
大数据具有以下特征:volume(体量大)、variety(样式多)、velocity(速度快)、valueless(价值密度低)
Hbase(Hadoop Database)是一个高可靠、高性能、面向列、可伸缩的分布式数据库,利用 Hbase 技术可在廉价 PC 上搭建起大规模结构化存储集群。 Hbase 参考 Google 的 Big Table 建模,使用类似 GFS 的 HDFS 作为底层文件存储系统,在其上可以运行 Mapreduce 批量处理数据,使用 Zookeeper 作为协同服务组件。
二、HBase 与 Hadoop
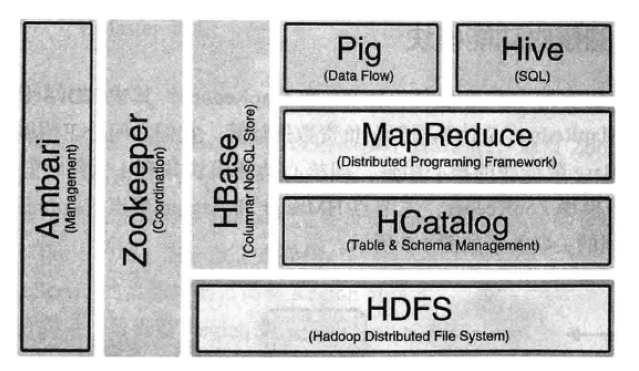
HBase 底层依赖 Hadoop,所以选择 Hadoop 版本对 HBase 部署很关键(https://blog.csdn.net/sunny05296/article/details/54089194)
三、HBase 四大核心组件
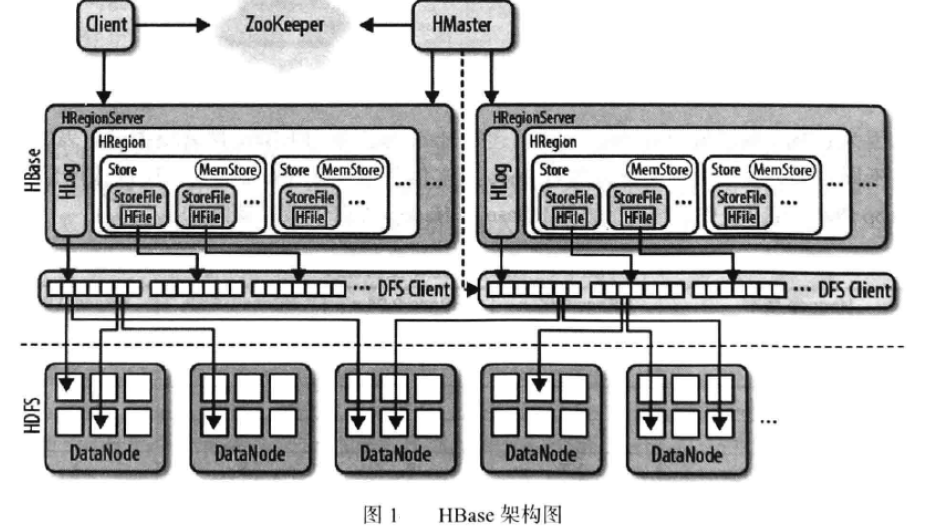
Hadoop 框架包含两个核心组件: HDFS 和 Mapreduce,其中 HDFS 是文件存储系统,负责数据存储; Mapreduce 是计算框架,负责数据计算。它们之间分工明确、低度耦合、相关关联。对于 Hbase 数据库的核心组件,即核心功能模块共有 4 个,它们分别是:客户端 Client、协调服务模块 Zookeeper、主节点 Master 和 Region 节点 Region Server,这些组件的描述和相互之间的关联关系如图所示。
3.1 客户端
Client 客户端 C1ient 是整个 Hbase 系统的入口。使用者直接通过客户端操作 Hbase。客户端使用 Hbase 的 RPC 机制与 Master 和 Region Server 进行通信。对于管理类操作, Client 与 Master 进进行 RPC 通信;对于数据读写类操作, Client 与 Regionserver 进行 RPC 交互。这里客户端可以是多个, 并不限定是原生 Java 接口,还有 Thrift、Avro、Rest 等客户端模式,甚至 Mapreduce 也可以算作一种客户端。
3.2 客户端协调服务组件 Zookeeper
Zookeeper Quorum(队列)负责管理 Hbase 中多 Master 的选举、服务器之间状态同步等。再具体一些就是, Hbase 中 Zookeeper 实例负责的协调工作有:存储 Hbase 元数据信息、实时监控 Region Server、存储所有 Region 的寻址入口,当然还有最常见的功能就是保证 Hbase 集群中只有一个 Master 节点。
3.3 主节点 HMaster
HMaster 没有单点问题,在 Hbase 中可以启动多个 HMaster,通过 Zookeeper 的 Master 选举机制保证总有一个 Master 正常运行并提供服务,其他 HMaster 作为备选时刻准备(当目前 HMaster 出现问题时)提供服务。 HMaster 主要负责 Table 和 Region 的管理工作。
- 管理用户对 Table 的增、删、改、査操作。
- 管理 Region Server 的负载均衡,调整 Region 分布。
- 在 Region 分裂后,负责新 Region 的分配。
- 在 Region Server 死机后,负责失效 Region Server 上的 Region 迁移。
3.4 Region 节点 HRegionServer
HRegionServer 主要负责响应用户 I/O 请求,向 HDFS 文件系统中读写数据,是 Hbase 中最核心的模块。 HRegionServer 内部管理了一系列 HRegion 对象,每个 HRegion 对应了 Table 中的一个 Region。 HRegion 由多个 HStore 组成,每个 HStore 对应了 Table 中的一个 Column Family 的存储。可以看出每个 Column Family 其实就是一个集中的存储单元,因此最好将具备共同 I/O 特性的列放在一个 Column Family 中,这样能保证读写的高效性。HRegionServer 的组成结构如图2所示。
如图2所示, Hstore 存储是 Hbase 存储的核心,由两部分组成: MemStore 和 StoreFile。 MemStore 是 Sorted Memory Buffer,用户写入的数据首先会放入 MemStore 中,当 MemStore 满了以后会缓冲(flush)成一个 StoreFile(底层实现是 HFile),当 StoreFile 文件数量增长到一定阈值,会触发 Compact 操作,将多个 StoreFiles 合并成一个 StoreFile,在合并过程中会进行版本合并和数据删除,因此可以看出 HBase 其实只有增加数据,所有的更新和删除操作都是在后续的 Compact 过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了 HBase I/O 的高性能。
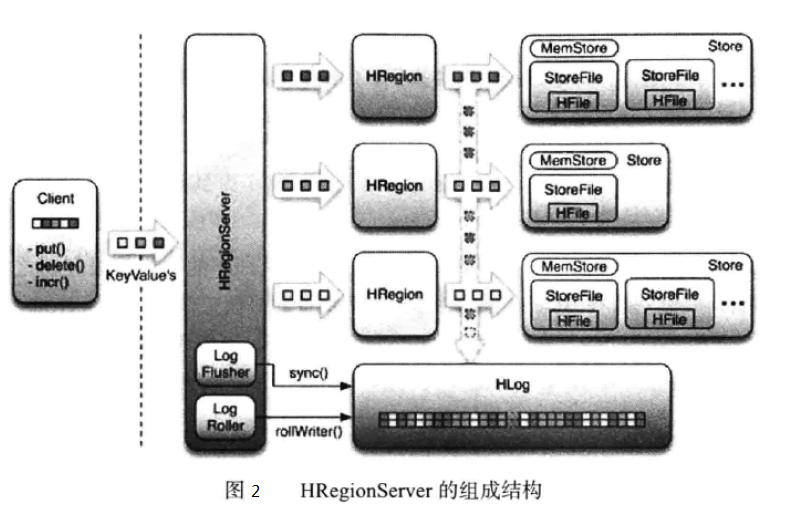
StoreFiles 在触发 Compact 操作后,会逐步形成越来越大的 StoreFile,当单个 StoreFile 大小超过一定阈值后,会触发 Split 操作,同时把当前 Region 分裂成 2 个 Region,父 Region 会下线,新分裂的 2 个子 Region 会被 Master 分配到相应的 HRegionServer 上,使得原先 1 个 Region 的压力得以分流到 2 个 Region 上。
每个 HRegionServer 中都有一个 HLog 对象,HLog是一个实现 Write Ahead Log 的类,在每次用户操作写入 MemStore 的同时,也会写一份数据到 HLog 文件中,HLog 文件定期会滚动出新,并删除旧的文件(已持久化到 StoreFile 中的数据)。在 HRegionServer 意外终止后, Master 会通过 Zookeeper 感知到,首先处理遗留的 HLog 文件,将其中不同 Region 的 Log 数据进行拆分,分别放到相应 Region 的目录下,然后再将失效的 Region 重新分配,领取到这些 Region 的 HRegionServer 在加载 Region 的过程中,会发现有历史 HLog 需要处理,因此会将 HLog 中的数据回放到 MemStore 中,然后缓冲(flush)到 StoreFiles,完成数据恢复。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号