指令和运算 - 编译、链接和装载之程序装载:640K内存真的不够用么
指令和运算 - 编译、链接和装载之程序装载:640K内存真的不够用么
计算机组成原理目录:https://www.cnblogs.com/binarylei/p/12585607.html
在前面几节中,我们已经知道高级语言通过编译、链表生成可执行文件,但这个可执行文件只有先被加载到内存中,才能被 CPU 执行。但问题是内存是有限的,如何加载越来越多的程序呢?
比尔·盖茨在上世纪 80 年代说的 "640K ought to be enough for anyone",也就是 640K 内存对所有人都够用了。那他是怎么做到的呢?硬件工程师巧妙的通过内存分段、内存交换、内存分页三项技术来解决这个问题。
1. 程序装载面临的挑战
我们的代码通过编译和链接后,将多个文件合并成一个最终可执行文件。在运行这些可执行文件的时候,我们其实是通过一个装载器,解析 ELF 或者 PE 格式的可执行文件。装载器会把对应的指令和数据加载到内存里面来,让 CPU 去执行。
可执行程序装载到内存,是由装载器完成的。装载器需要满足两个要求:
- 可执行程序加载后占用的内存空间应该是连续的。执行指令的时候,程序计数器是顺序地一条一条指令执行下去。这也就意味着,这一条条指令需要连续地存储在一起。
- 需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。虽然编译出来的指令里已经有了对应的各种各样的内存地址,但是实际加载的时候,我们其实没有办法确保,这个程序一定加载在哪一段内存地址上。因为我们现在的计算机通常会同时运行很多个程序,可能你想要的内存地址已经被其他加载了的程序占用了。
要满足这两个基本的要求,我们很容易想到一个办法。那就是我们可以在内存里面,找到一段连续的内存空间,然后分配给装载的程序,然后把这段连续的内存空间地址,和整个程序指令里指定的内存地址做一个映射。
- 虚拟内存地址(Virtual Memory Address):指令里用到的内存地址,其实也就有编译链接后可执行文件中的地址。
- 物理内存地址(Physical Memory Address):内存硬件里面的空间地址,其实是可执行文件加载到内存中的地址。
这样,程序编译和链接时,只要关心虚拟内存地址。当程序执行时,会将可执行文件先加载到内存,我们在内存中维护一个虚拟内存到物理内存的映射表。这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。因为是连续的内存地址空间,所以我们只需要维护映射关系的起始地址和对应的空间大小就可以了。具体参考:存储器 - 内存:程序的虚拟内存是如何映射到物理内存?
2. 内存分段
2.1 内存分段
这种找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。这里的段,就是指系统分配出来的那个连续的内存空间。
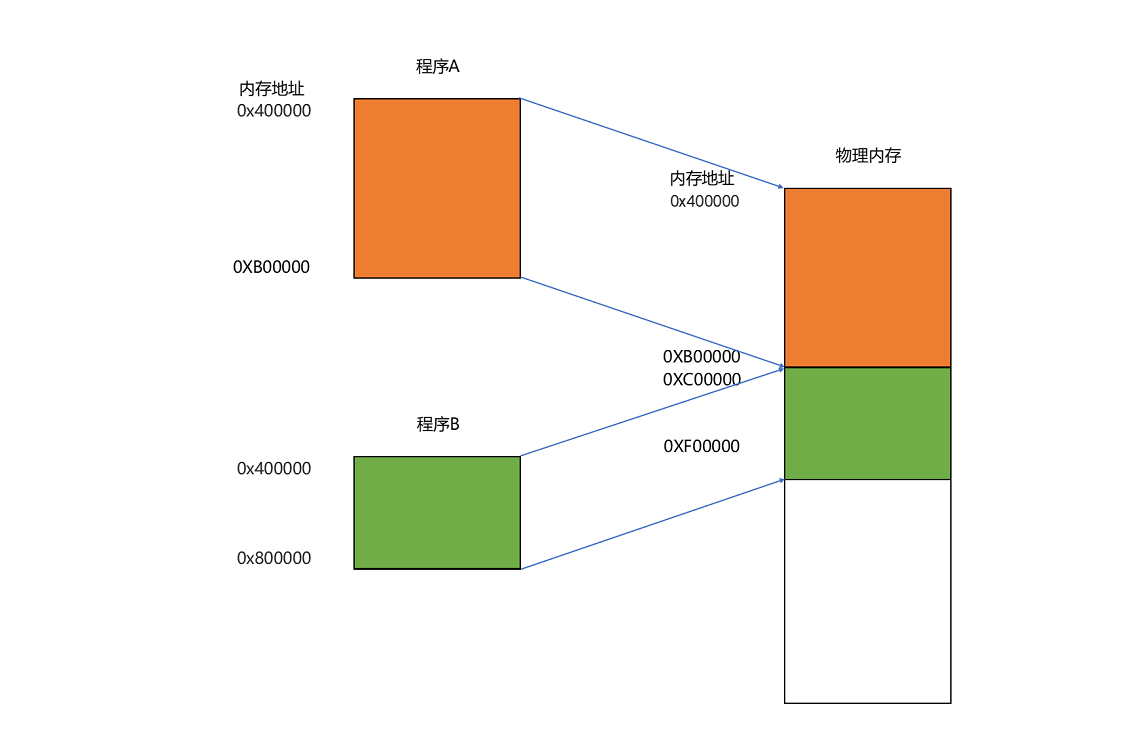
说明: 通过内存分段技术,我们可以将多个程序同时加载到内存中,而且每个程序的内存地址都是连续的。当程序关闭时,同时释放对应的内存空间,这段内存空闲下来后又可以加载新的程序。但这样真的就完美了吗?和 JVM、SSD 一样,当反复加载和卸载多个程序后,内存不可避免产生内存碎片的问题,这又怎么解决呢?
2.2 内存交换
我们首先看这样一个场景:在 1GB 内存的电脑中先启动三个程序,图形渲染程序(512MB)、Chrome 浏览器(128MB)、Python 程序(256MB)。这时候关掉 Chrome,于是空闲内存还有 1024 - 512 - 256 = 256MB。按理来说,我们有足够的空间再去装载一个 200MB 的程序。但是,这 256MB 的内存空间不是连续的,而是被分成了两段 128MB 的内存。因此,实际情况是,我们的程序没办法加载进来。
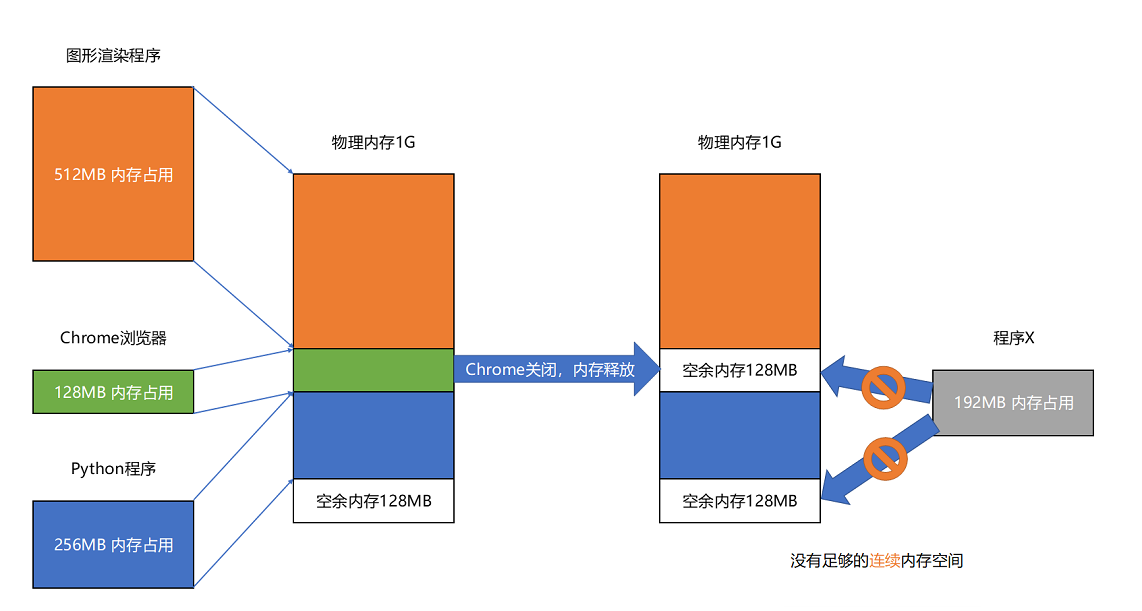
像上述场景中,内存中出现多块不连续的空间,我们叫做内存碎片(Memory Fragmentation)。解决这种内存碎片的办法就是内存交换(Memory Swapping)。我们可以先将内存中不连续的内存空间全部写到硬盘上,然后再从硬盘上读回到内存,当然读回内存的时候,就会将内存整理成连接的空间。在 Linux 操作系统,分配了一个 swap 硬盘分区,这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。
如上例中,我们会将 Python 程序对应的 256M 写入磁盘,再从磁盘读回时会将内存地址接到 512M 的地址之后,这样我们就有了连续的 256MB 内存空间,可以加载一个新的 200MB 的程序。
虽然通过虚拟内存、内存分段和内存交换,看似解决了计算机同时装载运行很多程序的问题。不过,硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上,这时硬盘就会成为一个性能瓶颈。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。你会有什么好办法呢?
3. 内存分页
3.1 Redis List
我们知道数组是一个非常高效的数据结构,因为数组使用连续的内存空间进行存储,可以充分利用 CPU 的预取功能。所以在很多追求高性能的中间件,如 Disrupter 都是使用数组这样的结构。
不过,如果数组占用的空间非常大,比如需要 20GB 甚至更大的空间时,我们往往更推荐使用链表了。因为数组需要使用连续的内存空间,很多时候明明有 30GB 的内存,但却没有 20GB 的连续内存空间,导致无法申请到内存。如果我们即想使用数组连续内存带来的高性能,又想使用链表这种不需要大量连续内存带来的优势,你会怎么设计你的数据结构呢?我们看一下 Redis List 是怎么解决这个问题的。
Redis List 可能存储海量的数据,直接使用数组肯定不行。事实上,Redis List 使用 quicklist 的数据结构,quicklist = linkedlist + ziplist。linkedlist 是一个链表,但 ziplist 和数组类似也是使用连续的内存空间存储。实际上,quicklist 是使用小段小段的连续内存,然后使用一个 linkedlist 将这些连续的内存 ziplist 串连起来,避免了一次性的分配一个大的连续内存。当然,ziplist 也不适合存储很大的数据。

3.2 内存分页
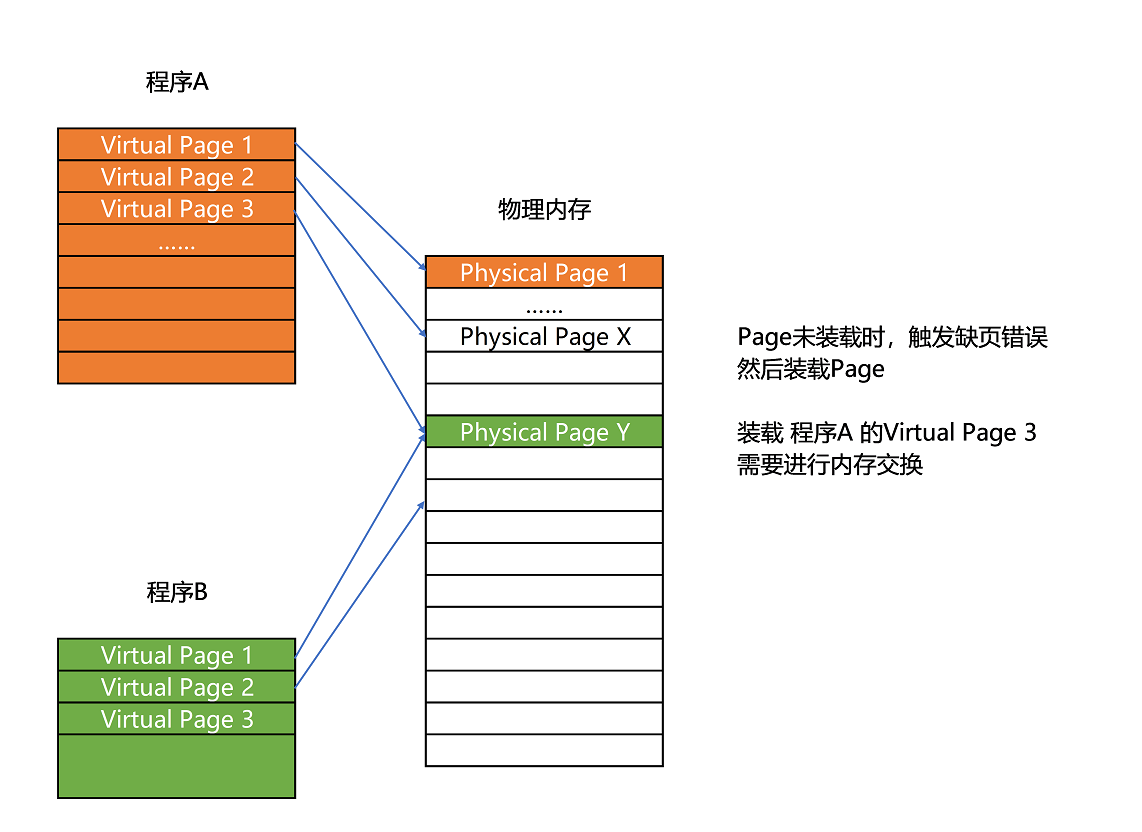
和 quicklist 的思想类似,现在计算机的内存管理,使用了内存分页(Paging)。这种技术将内存分隔成一小段一小段的连续内存,同样避免一次性的分配大量连续内存空间,这每一小段的连续内存称之为页(Page)。然后,使用页表保存虚拟页和物理页的映射关系。Linux 上,每一页大小通常为 4KB,可以通过 getconf PAGE_SIZE 查看 Linux 下每页的大小。
总结: 内存分页采用 "页 + 页表" 的数据结构,来避免一次性的分配大量连续内存空间。其中每页都是固定大小的连续内存空间,通常是 4KB,而页表则是一种类似 B+ 树的结构用来保存虚拟页和物理页的映射关系。
使用内存分页技术有如下优势:
- 每个页大小都只有 4KB 大小,即便发生内存交换也只有少数几个页写入磁盘,不会使用程序卡顿。
- 程序加载运行时,只需要将用到指令和数据对应的页,加载到内存中即可,不需要一次性的全部加载。
3.3 缺页错误
当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
4. 总结延伸
推荐阅读:
- 《程序员的自我修养——链接、装载和库》的第 1 章和第 6 章:深入地了解代码装载的详细过程。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号