NIO 源码分析(03) 从 BIO 到 NIO
NIO 源码分析(03) 从 BIO 到 NIO
Netty 系列目录(https://www.cnblogs.com/binarylei/p/10117436.html)
一、NIO 三大组件 Channels、Buffers、Selectors
1.1 Channel 和 Buffer
基本上,所有的 IO 在 NIO 中都从一个 Channel 开始。Channel 有点象流。 数据可以从 Channel 读到 Buffer 中,也可以从 Buffer 写到 Channel 中。这里有个图示:
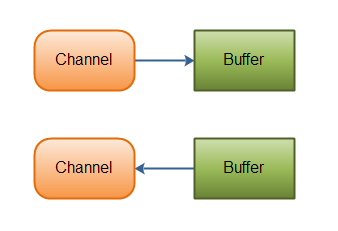
总结: Channel 和 Buffer 在 NIO 并不是新的东西:Channel 的本质就是 Socket,Buffer 的本质就是 byte[]。在 BIO 时代,BufferedInputStream 就是一个缓冲流。
1.2 Selector
Selector 允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用 Selector 就会很方便。例如,在一个聊天服务器中。
这是在一个单线程中使用一个 Selector 处理 3 个 Channel 的图示:
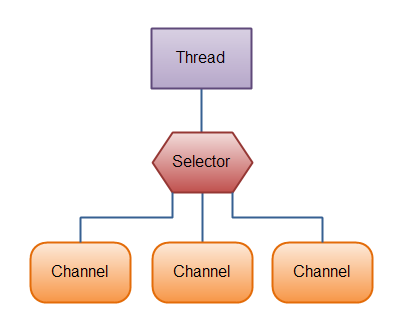
总结: Selector 在是 NIO 的核心,有了 Selector 模型,一个线程就可以处理多个 Channel 了。
1.3 Linux IO 和 NIO 编程的区别
(1) Linux IO 网络编程
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
bind(listenfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
listen(listenfd, BACKLOG);
socklen_t cliaddr_len = sizeof(client_addr);
int clientfd = accept(listenfd, (struct sockaddr*)&client_addr, &cliaddr_len);
(2) Linux NIO 网络编程
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
bind(listenfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
listen(listenfd, BACKLOG);
// select 模型处理过程
// 1. 初始化套接字集合,添加监听 socket 到这个集合
FD_ZERO(&totalSet);
FD_SET(listenfd, &totalSet);
maxi = listenfd;
while(1) {
// 2. 将集合的一个拷贝传递给 select 函数。当有事件发生时,select 移除未决的 socket 然后返回。
// 也就是说 select 返回时,集合 readSet 中就是发生事件的 readSet
readSet = totalSet;
int nready = select(maxi + 1, &readSet, NULL, NULL, NULL);
if (nready > 0) {
if (FD_ISSET(listenfd, &readSet)) {
cliaddr_len = sizeof(cliaddr);
connfd = accept(listenfd, (struct sockaddr *) &cliaddr, &cliaddr_len);
printf("client IP: %s\t PORT : %d\n", inet_ntoa(cliaddr.sin_addr), ntohs(cliaddr.sin_port));
FD_SET(connfd, &totalSet);
maxi = connfd;
if (--nready == 0) {
continue;
}
}
}
}
总结: 对比 Linux IO 和 NIO 网络编程可以发现,NIO 相对 BIO 多出来的部分其实是 select 部分,其余的(包括 socket 创建,数据读取等)都是一样的。所以我说 Channel 和 Buffer 是 JDK 层面概念的转换,Selector 才是 NIO 的核心,接下来 NIO 的源码会更多的关注 Selector 模型的分析,Channel 和 Buffer 点到即止。
二、BIO 和 NIO 的区别
2.1 BIO 面向流,NIO 面向缓冲区。
Java NIO 和 IO 之间第一个最大的区别是,IO 是面向流的,NIO 是面向缓冲区的。
Java IO 面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO 的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
面向流,面向缓冲区,这是 Java 中的概念,和操作系统无关。
(1) Java IO 【SocketInputStream】
/**
* Java IO 直接对读取的数据进行操作
* 1. socketRead(native) 函数中获取相当长度的数据,然后直接对这块数据进行了操作
*/
int read(byte b[], int off, int length, int timeout) throws IOException {
// acquire file descriptor and do the read
FileDescriptor fd = impl.acquireFD();
try {
// native函数,这里从内核态中读取数据到数组 b 中
n = socketRead(fd, b, off, length, timeout);
if (n > 0) {
return n;
}
} catch (ConnectionResetException rstExc) {
} finally {
impl.releaseFD();
}
}
(2) Java NIO 【DatagramChannelImpl】
/**
* Java NIO 每次读取的数据放在该内存中,然后对该内存进行操作,增加了处理数据的灵活性
* 1. Util.getTemporaryDirectBuffer(newSize) 申请了一块堆外内存
* 2. receiveIntoNativeBuffer(native) 将数据读取到堆外内存中
* 3. dst.put(bb) 将数据从该内存中读取到内存块 dst 中
* 4. dst 就一个共享的内存块,可以对该内存进行各种操作,但也要注意一些问题,如数据覆盖
*/
private int receive(FileDescriptor fd, ByteBuffer dst)
throws IOException {
int pos = dst.position();
int lim = dst.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
if (dst instanceof DirectBuffer && rem > 0)
return receiveIntoNativeBuffer(fd, dst, rem, pos);
// 申请一块 newSize 大小的缓冲区块
int newSize = Math.max(rem, 1);
ByteBuffer bb = Util.getTemporaryDirectBuffer(newSize);
try {
// 数据读取到缓冲区中,buffer 可以做标记,操作指针等
int n = receiveIntoNativeBuffer(fd, bb, newSize, 0);
bb.flip();
if (n > 0 && rem > 0)
dst.put(bb);
return n;
} finally {
Util.releaseTemporaryDirectBuffer(bb);
}
}
可以看到,第一段代码中一次性从 native 函数中获取相当长度的数据,然后直接对这块数据进行了操作。
而第二段代码中 Util.getTemporaryDirectBuffer(newSize); 申请了一块堆外内存,每次读取的数据放在该内存中,然后对该内存进行操作。
一般说法面向缓存相对于面向流的好处在于增加了处理数据的灵活性,当然也增加了操作的复杂度,比如当更多数据取入时,是否会覆盖前面的数据等
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号