数据采集第五次作业
作业一
- 要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/
关键词:学生自由选择 - 输出信息:
MySQL数据库存储和输出格式如下:

实验过程
创建浏览器对象
url = 'https://www.jd.com/' # 起始url
driver = webdriver.Chrome() # 创建浏览器对象
driver.get(url)
输入关键字
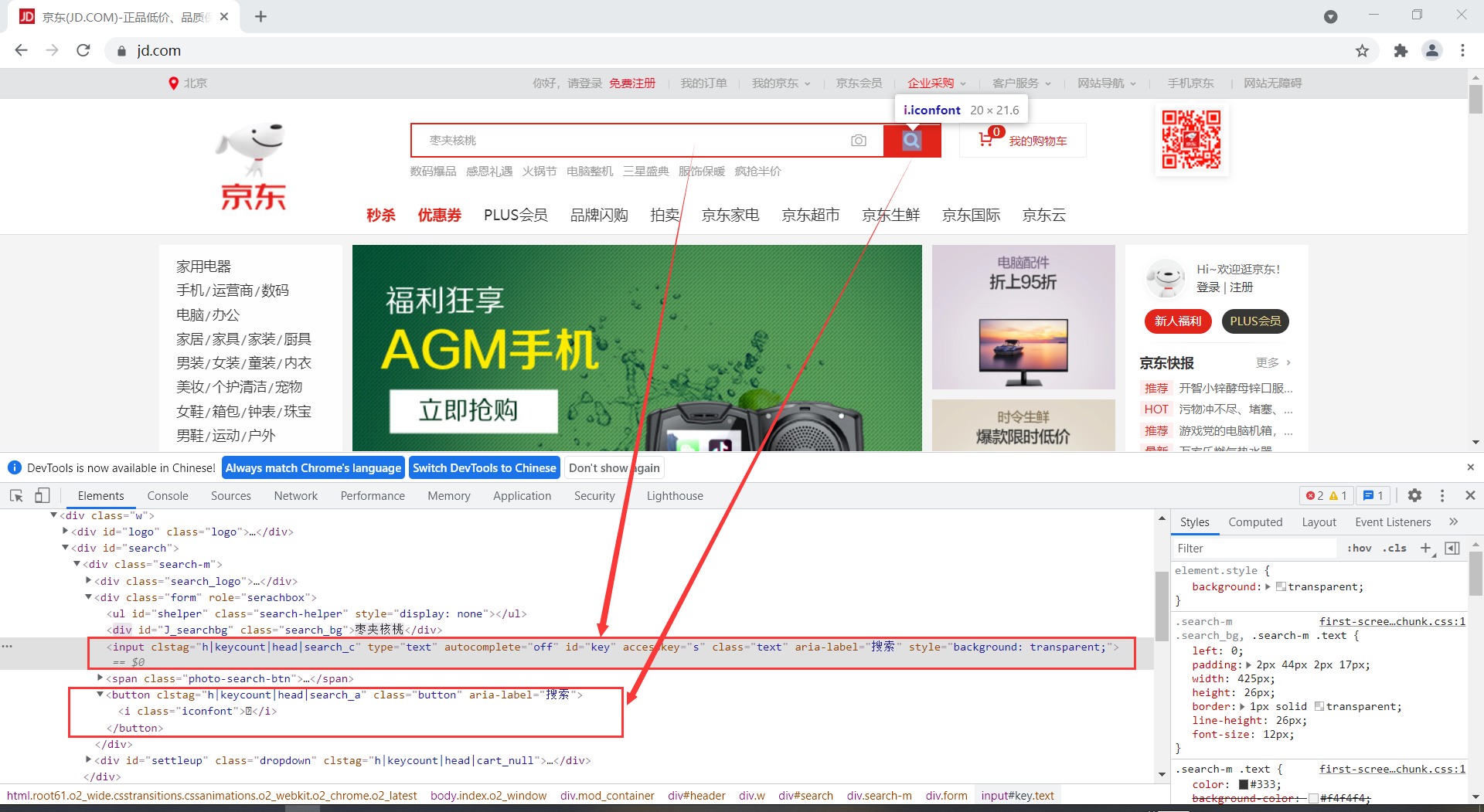
找到输入框位置后,传入参数'手机',再去寻找搜索按钮,模拟点击
search_content = driver.find_element(By.XPATH, '//*[@id="key"]') # 寻找搜索栏
search_content.send_keys("手机") # 传入信息:手机
search_button = driver.find_element(By.XPATH, '//*[@id="search"]/div/div[2]/button') # 寻找搜索按钮
search_button.click() # 点击搜索
爬取相关信息
这边要慢慢滚动页面,加载图片信息。
还有就是,京东拉到页面底端后,会继续增加信息,所以下拉滚动条的长度是初始页面高度的2.2倍
为什么是2.2倍呢?,我是随便试的,发现能成就用了
def Scrollbar():
# 滚动页面
js = "return action=document.body.scrollHeight"
new_height = driver.execute_script(js) # 获取页面的高度
# 滚动到页面长度2.2倍的位置,以80为间隔做滚动,一是为了加载图像,二是为了能够实现点击下一页
# 应因为京东的滚动条往下拉,他会继续加载信息,所以选择拉当前页面高度的2.2倍长度
for i in range(0, int(new_height * 2.2), 80): #
driver.execute_script('window.scrollTo(0, %s)' % (i))
time.sleep(0.06) # 慢慢滚动,否则图片信息加载不出
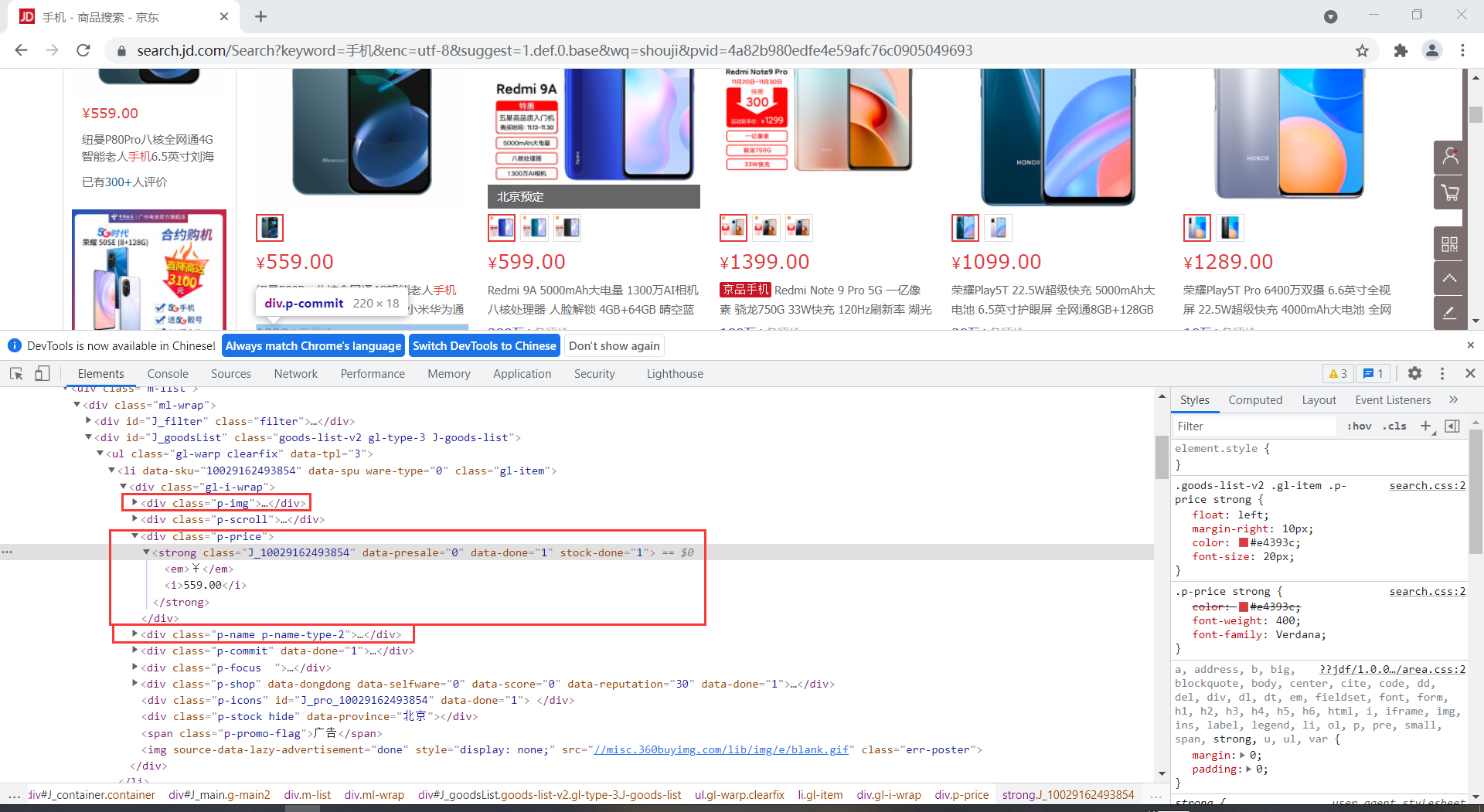
经过分析网页后,发现要爬取的数据在这里面,用Xpath定位元素
其中,mark部分为商品信息的第一个字段,所以note提取后,用split分隔取第一个元素作为mark
def ProcessSpider():
# 用Xpath寻找信息
Scrollbar() # 下拉滚动条
imgs = driver.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li/div/div[1]/a/img') # 图片的url
price = driver.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li/div/div[3]') # 价格
note = driver.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li/div/div[4]') # 找商品的title
for img, p, n in zip(imgs, price, note):
mprice.append(p.text)
mfile.append(img.get_attribute('src'))
mark.append(n.text.split()[0]) # 一般商品的title第一个字段就是这个商品的mark
mnote.append(n.text)
翻页
要保证页面停留的位置出现'下一页'这个按钮
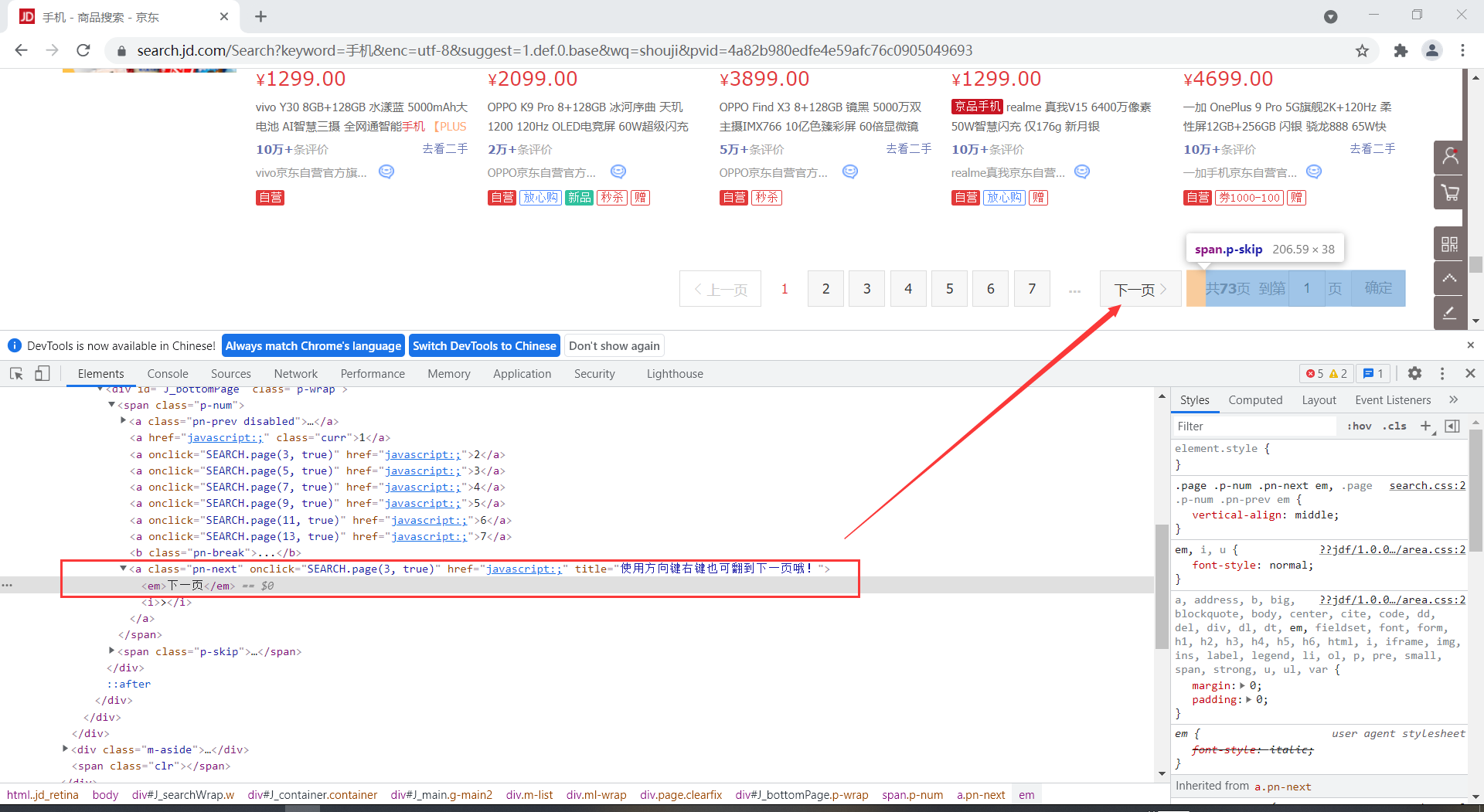
# 翻页
def Pageturn():
try:
# Xpath定位到点击下一页的a标签,然后模拟点击
next_page = driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]/em')
next_page.click()
except Exception as err:
print(err)
数据存储
写入数据库
# 存入数据库
def InsertDB():
conn = pymysql.connect(host="localhost", user="root", password="root", database="task", charset='utf8') # 连接数据库
cs1 = conn.cursor() # 创建游标对象
# 创建表 定义表格式
sqlcreat = '''
create table if not exists exp5_1(
mNo int not null,
mMark char(100),
mPrice char(50),
mNote char(200),
mFile char(200)
)
'''
cs1.execute(sqlcreat)
# 插入格式
sql = '''INSERT INTO exp5_1(mNO,mMark,mPrice,mNote,mFile) VALUES("%s","%s","%s","%s","%s")'''
for i in range(len(mark)):
arg = (i + 1, mark[i], mprice[i], mnote[i], mfile[i])
cs1.execute(sql, arg)
conn.commit()
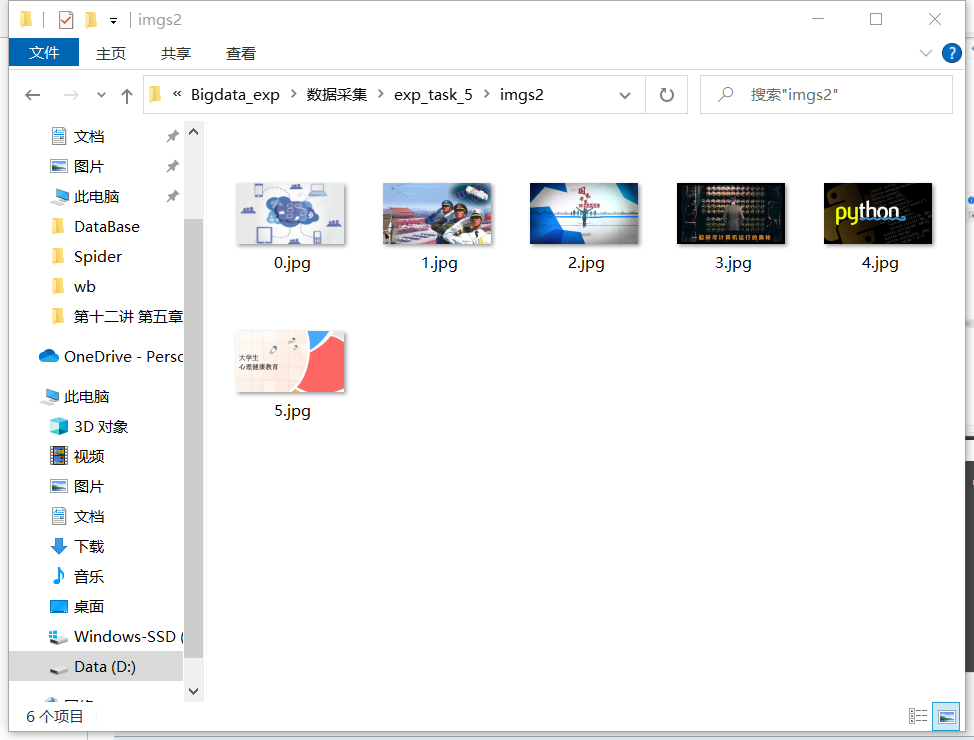
下载图片
这边是单线程下载
def DownLoadImg():
for i in range(len(mfile)):
resp = requests.get(mfile[i]) # 通过requests.get()直接访问图像地址
f = open('./imgs/' + str(i) + '.jpg', 'wb') # 二进制保存
f.write(resp.content) # 写入
f.close() # 关闭
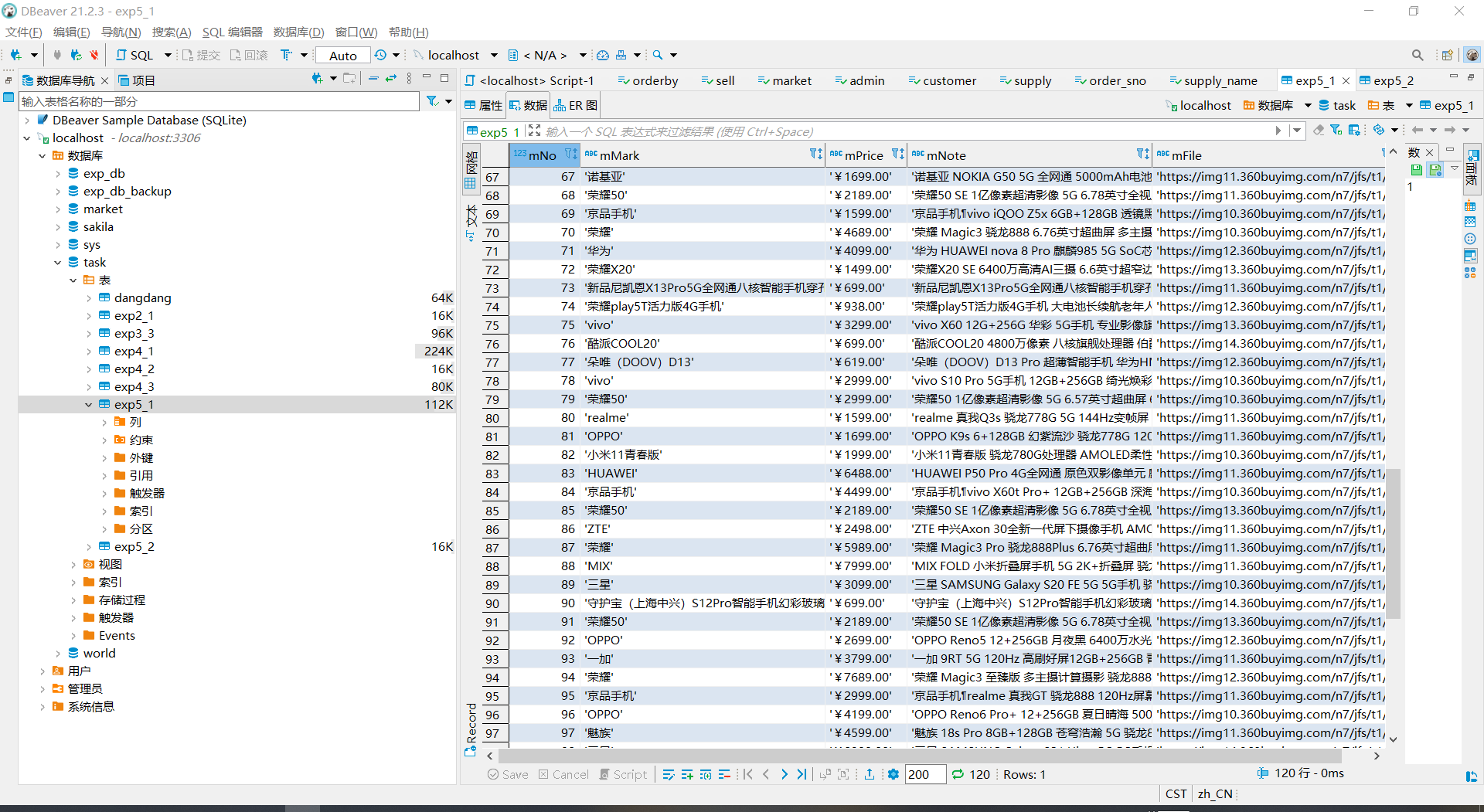
运行结果
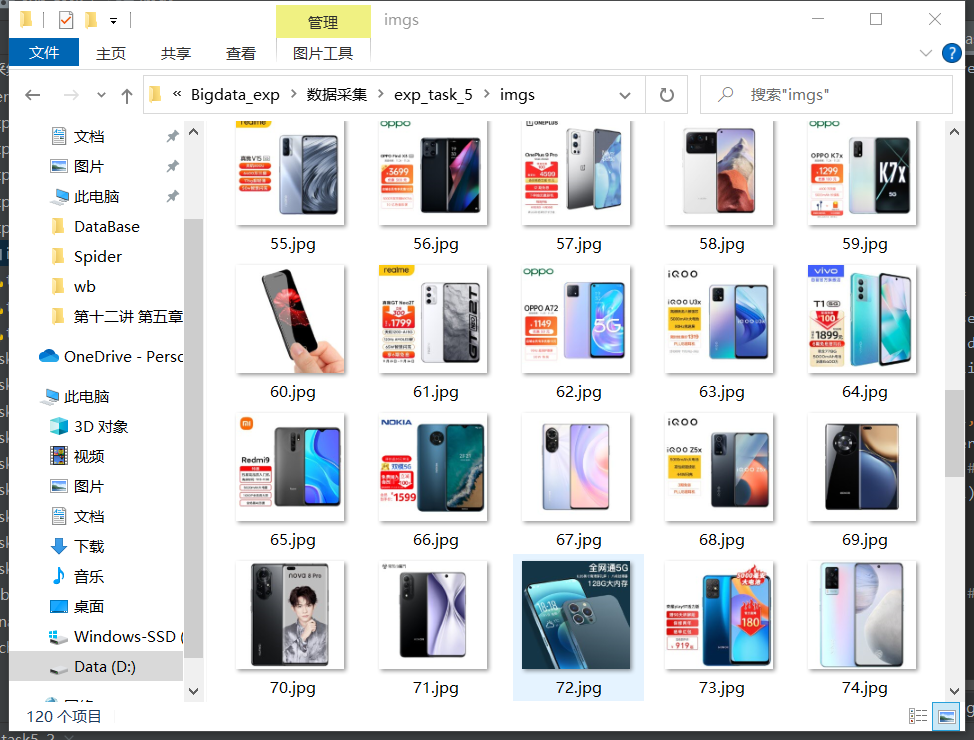
心得体会
使用selenium爬取信息做的是模拟用户操作,编写代码的时候要更多考虑一下自己在浏览相关信息的时候需要做什么。如更待相关信息的加载,机器的速度极快,多数都是还没等他加载就爬取完了,这时候爬取的信息都是None,所以需要慢慢浏览页面,让信息都加载完全后再爬取。
模拟点击,输入信息进行检索都要让相关按钮,输入框在当前页面能看到的地方,这一点也是体现了模拟用户的操作。
作业二
- 要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待
HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学
进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹
中,图片的名称用课程名来存储。
候选网站:http://www.icourse163.org - 输出信息:
MYSQL数据库存储和输出格式表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义
设计表头:
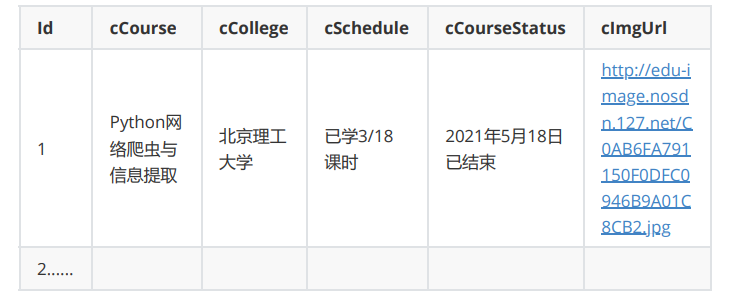
实验过程
模拟登录
登录过程中,元素会有一个id属性,这个是表示用户的身份,这边不能将其作为我们找元素的依据,需要绕开这个id
首先是点击登录
# 进入首页先找到登录按钮
login_content = driver.find_element(By.XPATH, '//*[@id="j-topnav"]/div')
login_content.click()
默认是扫码登录,这边要点击其他登陆方式
# 点击选择其他登录方式
other = driver.find_element(By.XPATH, '//body/div[13]/div[2]/div/div/div/div/div[2]/span')
other.click()
选择手机账号登录
# 点击选择手机账号登录
phone = driver.find_element(By.XPATH, '//div[@class="ux-tabs-underline"]')
phone.click()
这个时候 需要找到这个frame,才能输入账号,密码相关信息。

# 找到弹出的登陆框架
iframe = driver.find_element(By.XPATH,'//body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe')
driver.switch_to.frame(iframe)
输入账号,密码
# 输入手机号(账号
number = input("请输入手机账号:")
pwd = input("请输入密码:")
admin = driver.find_element(By.XPATH, '//div[@class="u-input box"]//input[@type="tel"]')
admin.send_keys(number)
time.sleep(0.5)
# 输入密码
psd = driver.find_element(By.XPATH, '//body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
psd.send_keys(pwd)
time.sleep(0.5)
模拟点击登陆
# 点击登录按钮,这边登录时会很慢,所以等待5s
button = driver.find_element(By.XPATH, '//*[@id="submitBtn"]') # 寻找登录按钮
button.click() # 点击登录
time.sleep(5)
登陆成功,会显示一个弹窗,需要我们确定(写博客的时候他没了。。。
# 登录成功后,会跳出弹窗,模拟点击同意,否则影响后续操作
agree = driver.find_element(By.XPATH, '//*[@id="privacy-ok"]')
agree.click()
time.sleep(2)
点击进入我的课程
#进入我的课程
mycourse = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[4]/div')
mycourse.click()
数据爬取
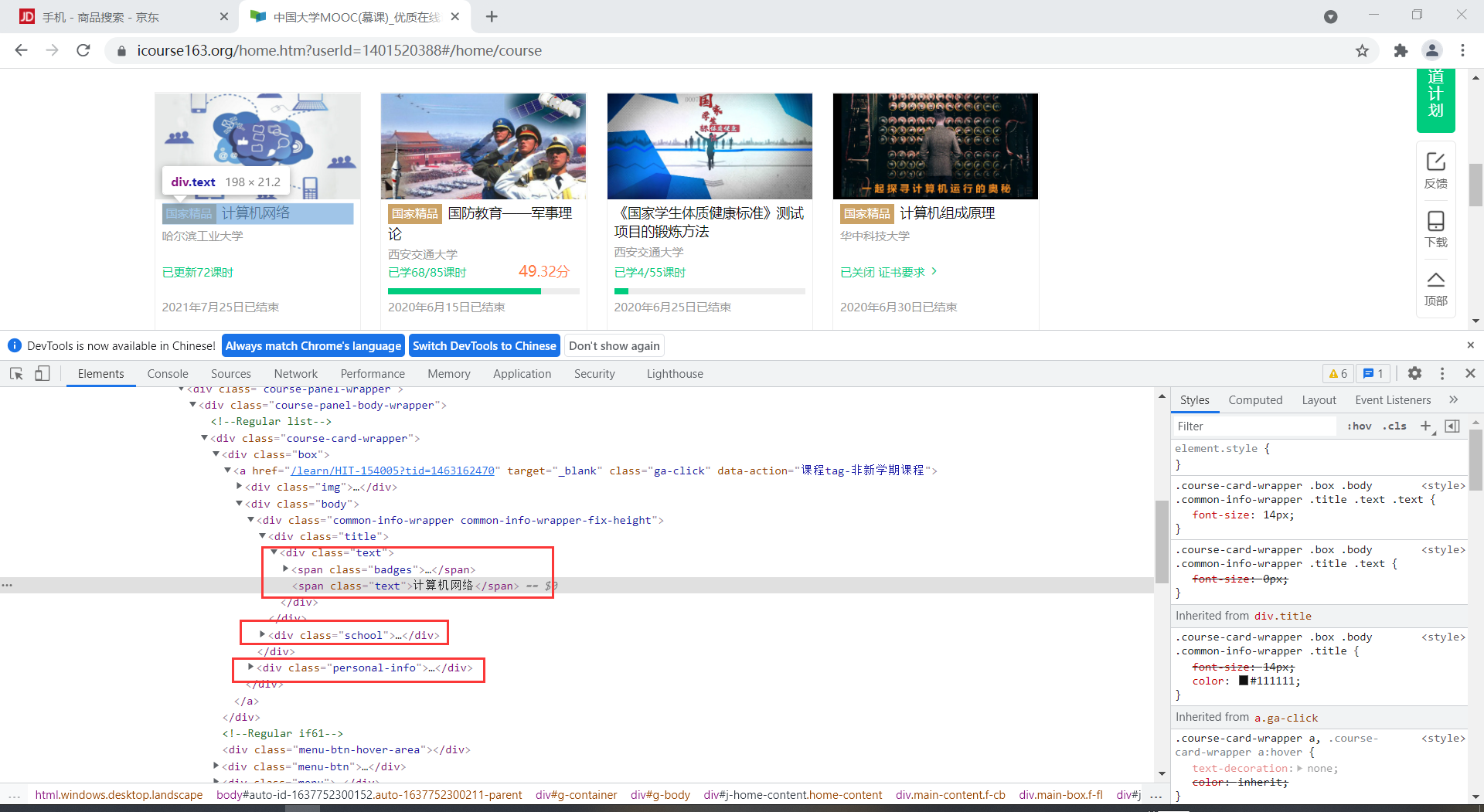
通过Xpath元素定位,找到相关信息
def ProcessSpider():
# 用Xpath寻找信息
name = driver.find_elements(By.XPATH,
'//div[@class="course-card-wrapper"]//div[@class="text"]//span[@class="text"]')#课程名
temp_collage = driver.find_elements(By.XPATH,
'//*[@id="j-coursewrap"]/div/div[1]/div//div[1]/a/div[2]/div[1]/div[2]/a')#学校名
temp_schedule = driver.find_elements(By.XPATH,
'//*[@id="j-coursewrap"]/div/div[1]/div//div[1]/a/div[2]/div[2]/div[1]/div[1]/div[1]/a/span')#进度
temp_status = driver.find_elements(By.XPATH,
'//*[@id="j-coursewrap"]/div/div[1]/div//div[1]/a/div[2]/div[2]/div[2]')#状态
imgs = driver.find_elements(By.XPATH, '//*[@id="j-coursewrap"]/div/div[1]/div//div[1]/a/div[1]/img')#图片地址
#分别添加到对应列表
for n, c, s, ss, img in zip(name, temp_collage, temp_schedule, temp_status, imgs):
course.append(n.text)
college.append(c.text)
schedule.append(s.text)
status.append(ss.text)
imgurl.append(img.get_attribute('src'))
数据存储
数据存储部分和前面代码类似,便不展示了。
运行结果
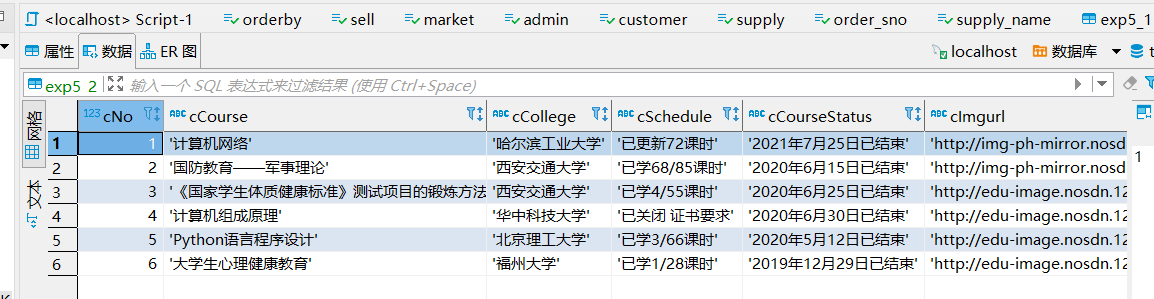
心得体会
通过selenium模拟用户操作可以方便的爬取数据,但是有点笨笨的感觉。
巩固,加强了selenium框架的学习,对他的爬取数据有了更深的认识。
作业三
- 要求:
理解Flume架构和关键特性,掌握使用Flume完成日志采集任务。
完成Flume日志采集实验,包含以下步骤:
任务一:开通MapReduce服务
任务二:Python脚本生成测试数据
任务三:配置Kafka
任务四:安装Flume客户端
任务五:配置Flume采集数据
实验过程
任务一:开通MapReduce服务 (略)
任务二:Python脚本生成测试数据
使用Xshell 7连接服务器,进入/opt/client/目录,用xftp7将本地的autodatapython.py文件上传至服务器/opt/client/目录下。
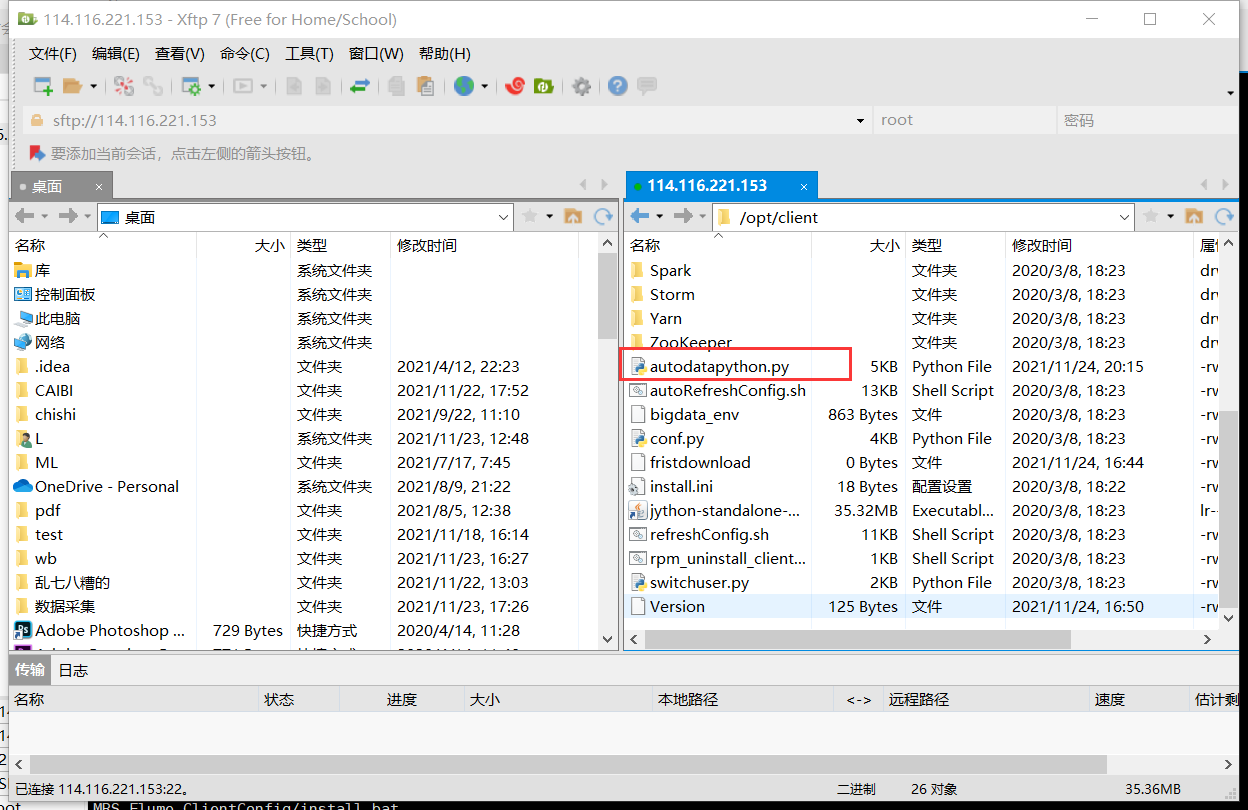
创建目录,使用mkdir命令在/tmp下创建目录flume_spooldir,我们把Python脚本模拟生成的数据放到此目录下,后面Flume就监控这个文件下的目录,以读取数据。
执行Python命令,测试生成100条数据。

查看数据
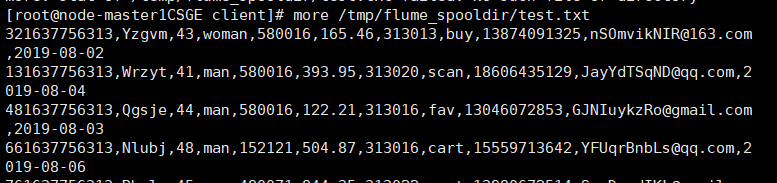
任务三:配置Kafka
步骤1 首先设置环境变量,执行source命令,使变量生效
步骤2 在kafka中创建topic(注意更换为自己Zookeeper的ip,端口号一般不动)
步骤3 查看topic信息

任务四:安装Flume客户端
进入MRS Manager集群管理界面,打开服务管理,点击flume,进入Flume服务,点击下载客户端
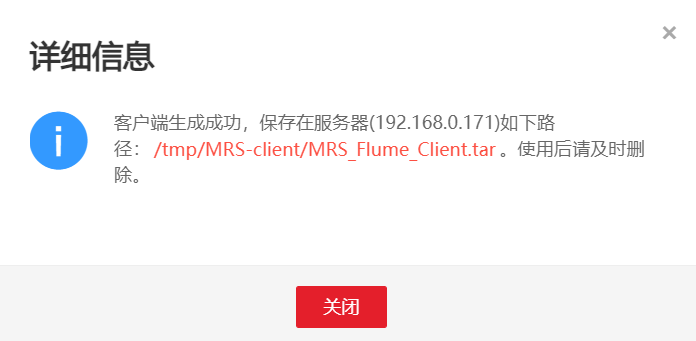
解压下载的flume客户端文件,校验文件包,安装Flume客户端
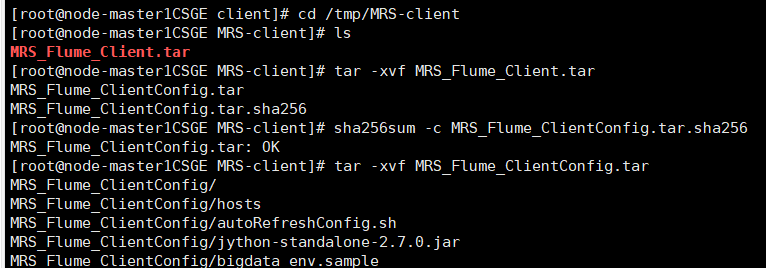

任务五:配置Flume采集数据
修改配置文件,创建消费者消费kafka中的数据。

执行完毕后,在新开一个Xshell 7窗口(右键相应会话-->在右选项卡组中打开),执行2.2.1步骤三的Python脚本命令,再生成一份数据,查看Kafka中是否有数据产生:
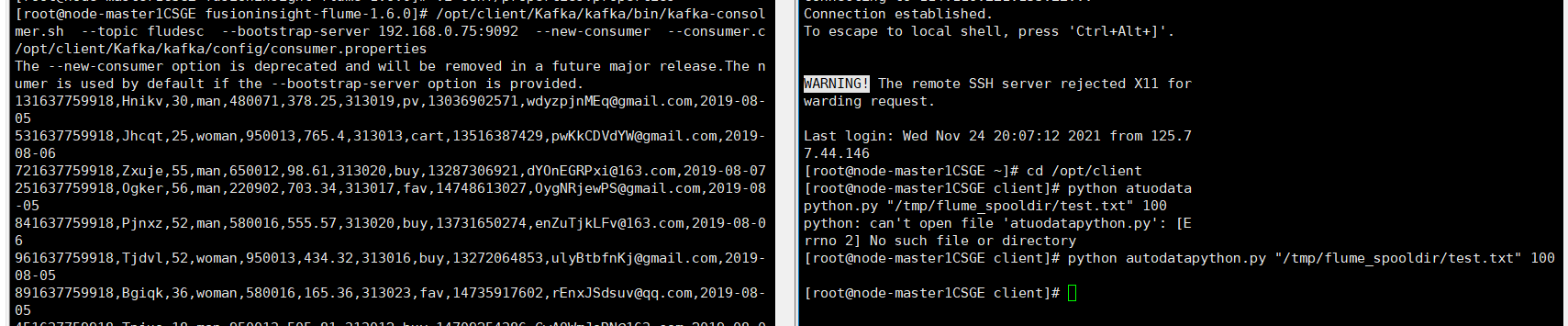
心得体会
通过学习Flume日志采集实验手册,了解了什么是Flume,对其有了一定的认知,初步掌握了Flume日志采集相关服务的使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号