数据采集第四次作业
作业一
- 要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;
Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
候选网站:http://www.dangdang.com/
关键词:学生自由选择 - 输出信息:
MySQL数据库存储和输出格式如下:

实验过程
编写Spider
items.py中编写需要爬取的信息
class Task41Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 书名
author = scrapy.Field() # 作者
publish = scrapy.Field() # 出版社
date = scrapy.Field() # 日期
price = scrapy.Field() # 价格
detail = scrapy.Field() # 描述
pass
Spider.py中实现数据爬取操作
name = "Spider" #命名为Spider
start_urls = 'https://search.dangdang.com/'
params = {
"key": 'python', # 搜索关键字python
"page_index": 'temp' # 翻页 ,页面数
}
发起请求:start_requests()
def start_requests(self):
for i in range(1, 4): #爬取三页
self.params["page_index"] = str(i) # 转成字符
#发起请求
yield scrapy.FormRequest(url=self.start_urls, callback=self.parse, method="GET", formdata=self.params)
信息提取:parse()
先解码,这个网页utf-8乱码,需要用gbk解码
data = response.body.decode('gbk') # 解码,utf-8乱码
selector = scrapy.Selector(text=data) # Xpath选择器
用Xpath进行信息提取,extract_first()以字符串形式返回
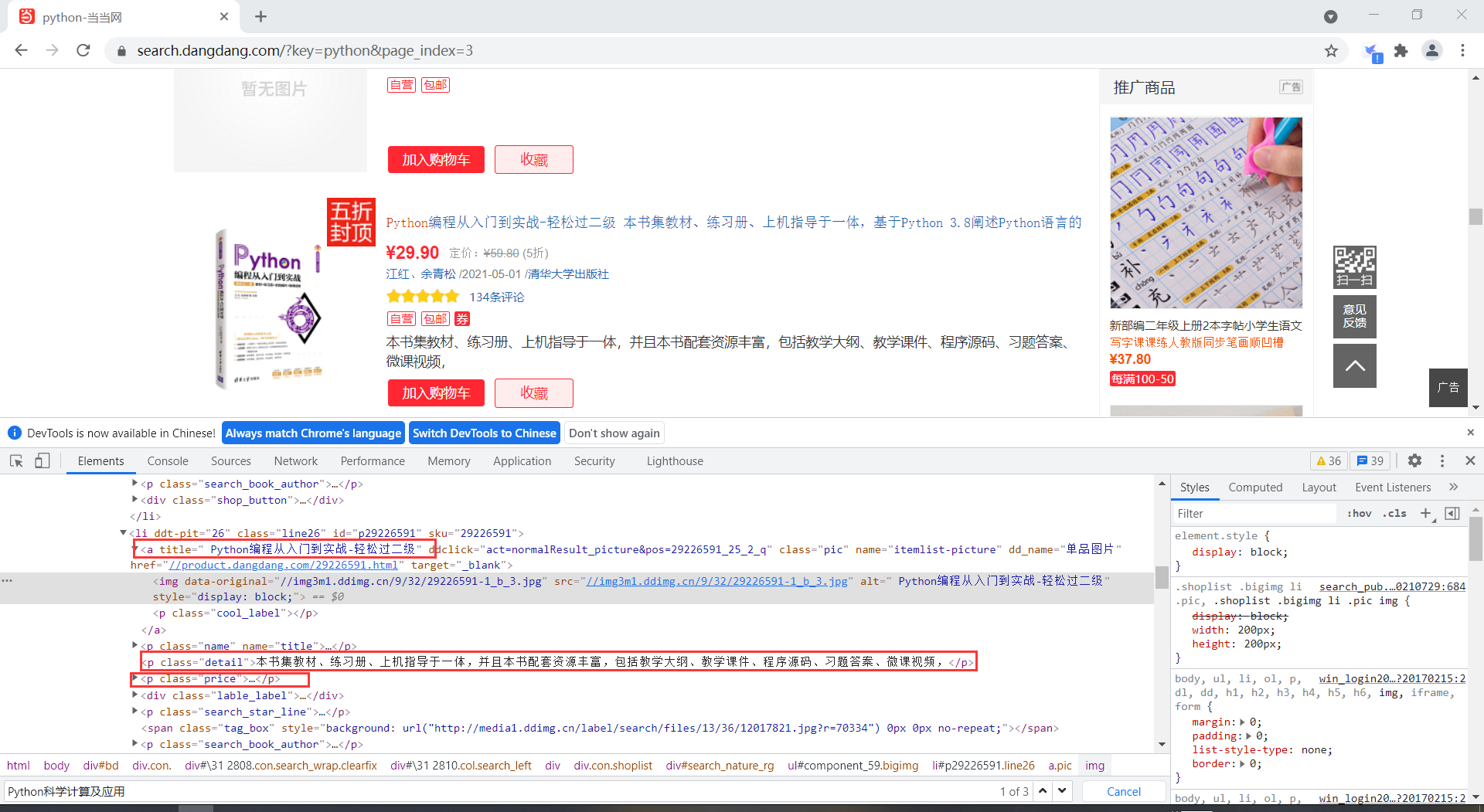
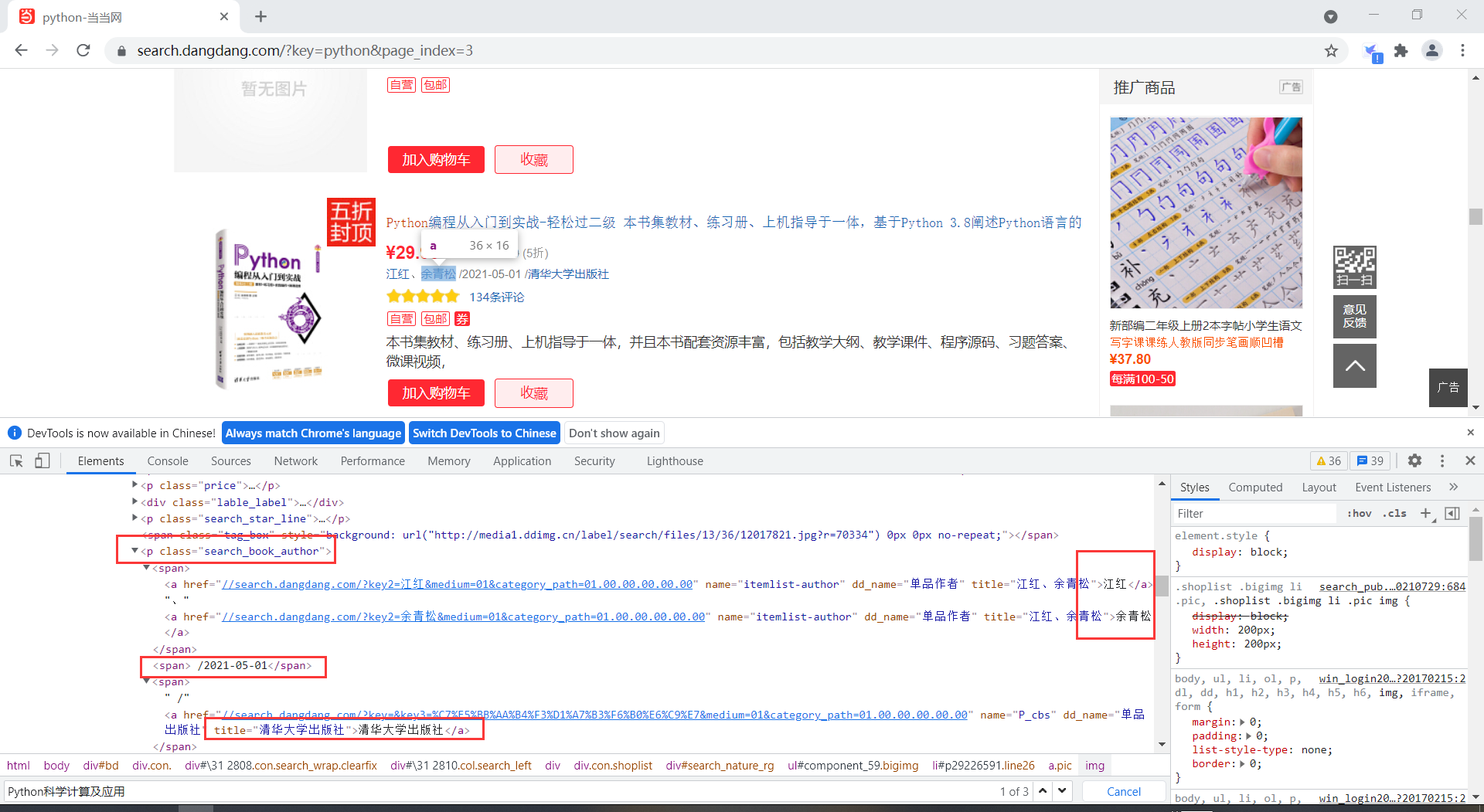
通过分析,书籍信息都放在li标签中,各个书籍的信息在li标签下面的p或者a标签中,通过Xpath元素定位,可以很好的提取相关信息
title = selector.xpath('//li[' + str(i) + ']/p[@class="name"]//a/@title').extract_first()#书名
detail = selector.xpath('//li[' + str(i) + ']/p[@class="detail"]/text()').extract_first()#描述
price = selector.xpath('//li[' + str(i) + ']/p[@class="price"]/span[@class="search_now_price"]/text()').extract_first()#价格
author = selector.xpath('//li[' + str(i) + ']/p[@class="search_book_author"]/span[1]/a[1]/text()').extract_first()#作者
date = selector.xpath('//li[' + str(i) + ']/p[@class="search_book_author"]/span[2]//text()').extract_first()#日期
publish = selector.xpath('//li[' + str(i) + ']/p[@class="search_book_author"]/span[3]/a[1]/text()').extract_first()#出版社
由于有这种信息不太完全的书籍,在数据库存入阶段会报错,需要做一些空值处理
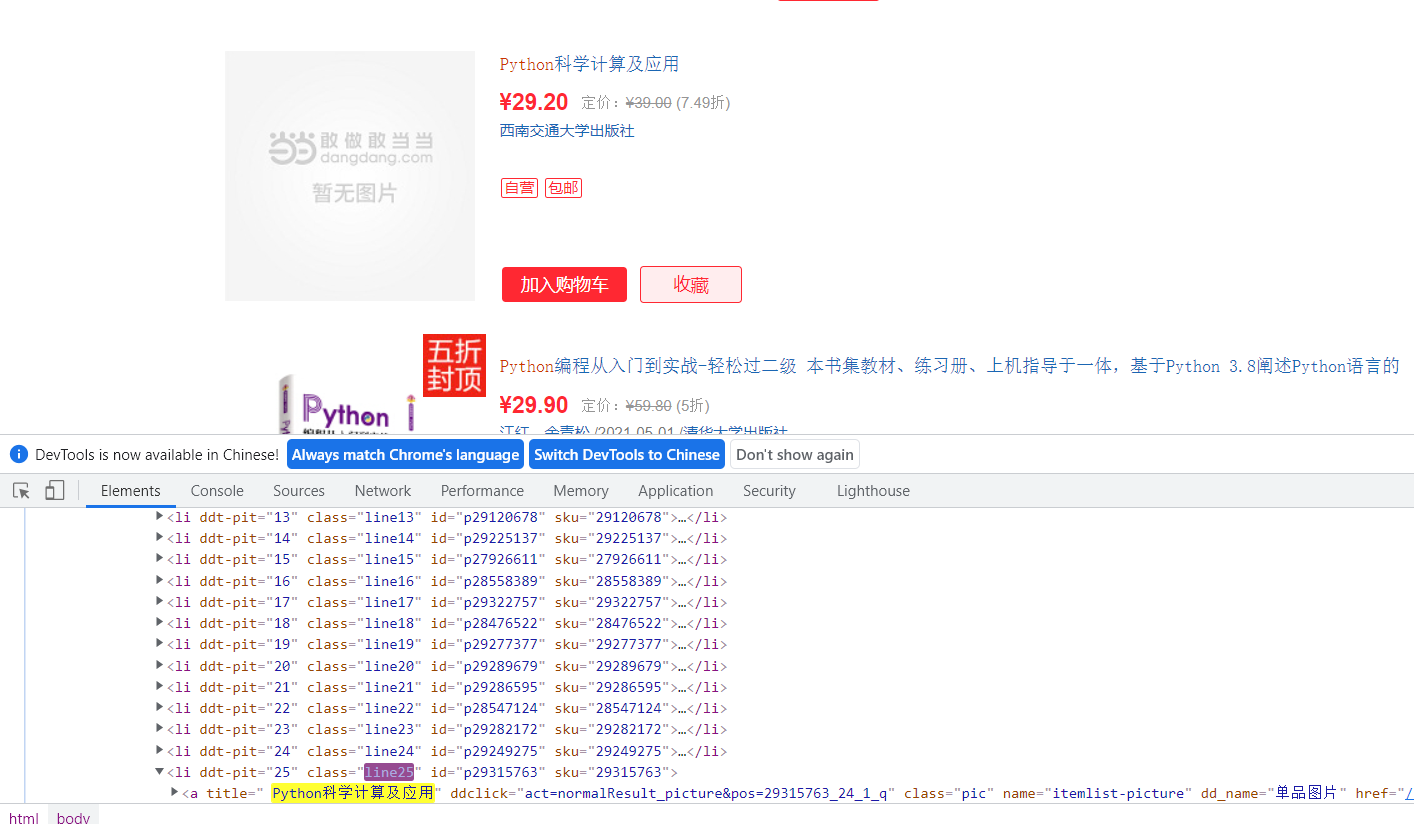
判断元素是否为None
#判断爬取的数据是否为空,如果是None,则赋值null
if detail is None:
print("detail is null")
detail = 'null'
if author is None:
print("author is null")
author = 'null'
if date is None:
print("date is null")
date = 'null'
if publish is None:
print("publish is null")
publish = 'null'
存入item的数据类型要字符串类型
item = Task41Item()#创建item项
#将信息存入item
item["title"] = title
item["detail"] = detail
item["price"] = price
item["author"] = author
item["date"] = date[2:]#截取日期第二位以后的字符串,前面两个是空格和'/',故舍弃
item["publish"] = publish
yield item
编写Pipelines
数据存储在 pipelines.py 中处理
class Task41Pipeline:
count = 1 #记录存入数据量
def process_item(self, item, spider):
try:
# 存入数据库
conn = pymysql.connect(host="localhost", user="root", password="root", database="task",
charset='utf8') # 连接数据库
cs1 = conn.cursor() # 建立游标
# 表创建 格式定义
sqlcreat = '''
create table if not exists exp4_1(
Id int(10) not null,
Title char(200) ,
Author char(50) ,
Publish char(50) ,
Date char(50) ,
Price char(50) ,
Detail text(2000) #文本信息
)
'''
cs1.execute(sqlcreat)
sql = '''INSERT INTO exp4_1(Id,Title,Author,Publish,Date,Price,Detail) VALUES("%s","%s","%s","%s","%s","%s","%s")'''
# 设置存入信息
arg = (self.count, item['title'], item['author'], item['publish'], item['date'], item['price'],
item['detail'])
#print(arg)
self.count += 1 #每存入一条数据,序号加一
cs1.execute(sql, arg)
conn.commit()
except Exception as err:
print(err)
return item
Settings
设置信息在settings.py中修改
将ROBOTSTXT_OBEY设置为False
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
修改PIPELINES,类名为pipelines中写的类(Task41Pipeline)
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'task4_1.pipelines.Task41Pipeline': 300,
}
请求头编写
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
执行函数
run.py 实现能够在编译器运行Scrapy
Spider 为爬虫名,在Spider.py中设置name
from scrapy import cmdline
cmdline.execute("scrapy crawl Spider -s LOG_ENABLED=False".split())
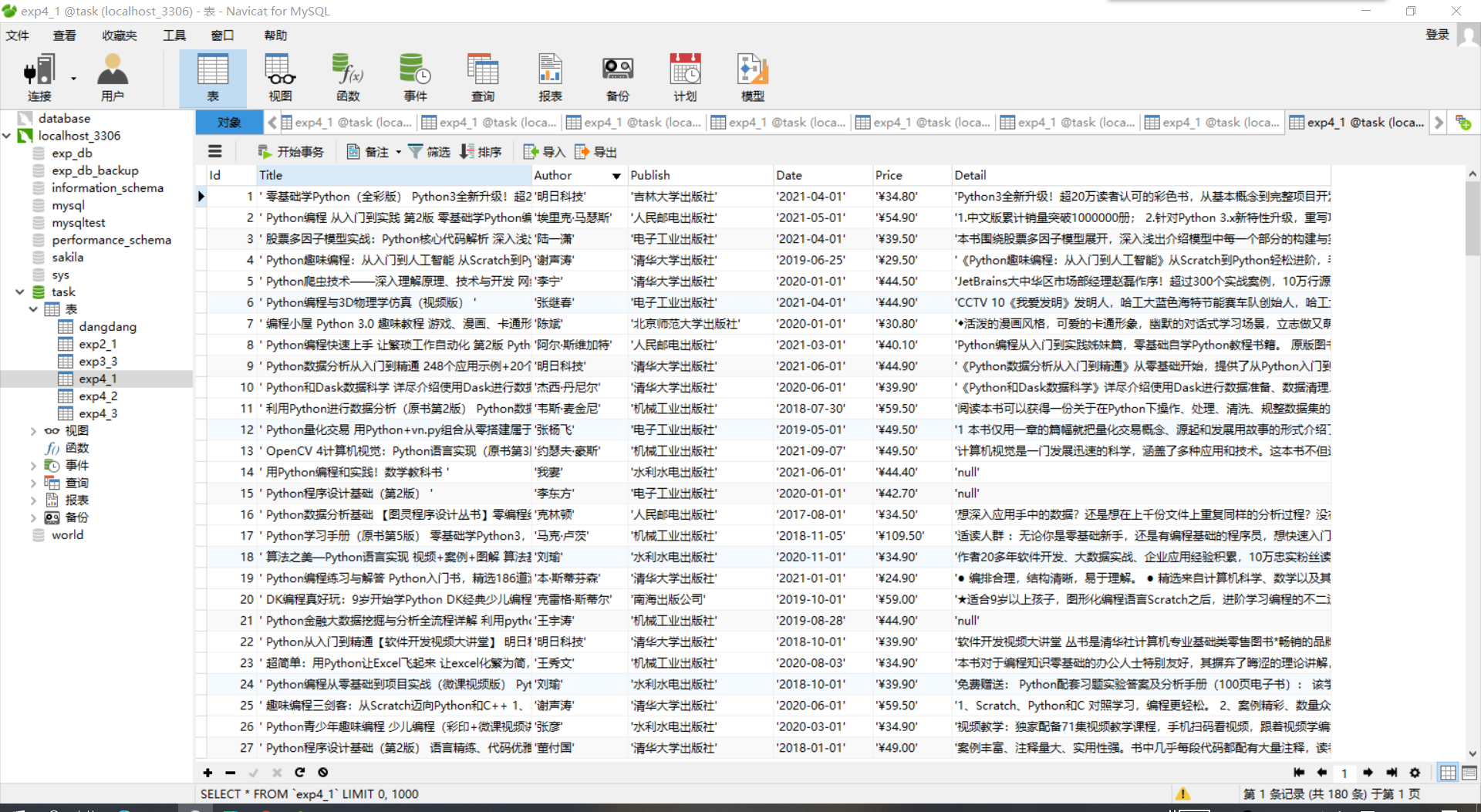
运行结果
用Navicat查看数据
心得体会
对于爬取的数据,很多并没有值,例如这边展示的西南交大出版社出版的这本书。
通过简单调试发现有些书没有作者信息,日期信息,描述信息,如下图。
所以在爬取信息后需要做一些数据处理,空值处理或者是一些数据规范化处理(如把空格,换行扔掉)。
作业二
- 要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;
使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
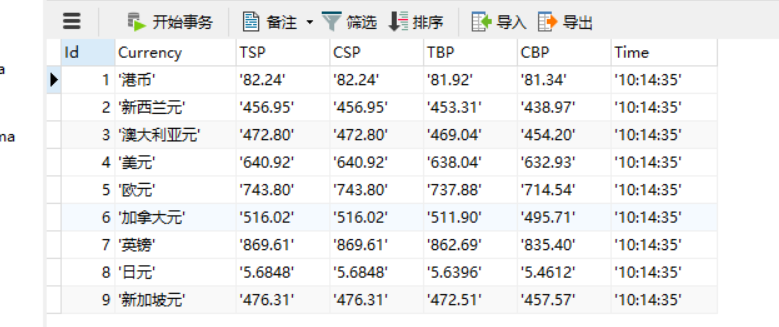
候选网站:招商银行网:http://fx.cmbchina.com/hq/ - 输出信息:
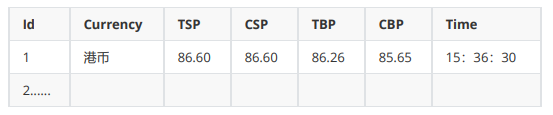
MySQL数据库存储和输出格式如下:
实验过程
编写Spider
items.py中编写需要爬取的信息
class Task42Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field() # 外币
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
Time = scrapy.Field() # 时间
pass
Spider.py中实现数据爬取操作
name = "Spider" #命名
start_urls = 'http://fx.cmbchina.com/hq/' #页面地址
发起请求:start_requests()
def start_requests(self):
yield scrapy.FormRequest(url=self.start_urls, callback=self.parse, method="GET")
信息提取:parse()
先解码,utf-8解码
data = response.body.decode() # 解码
selector = scrapy.Selector(text=data) # Xpath选择器
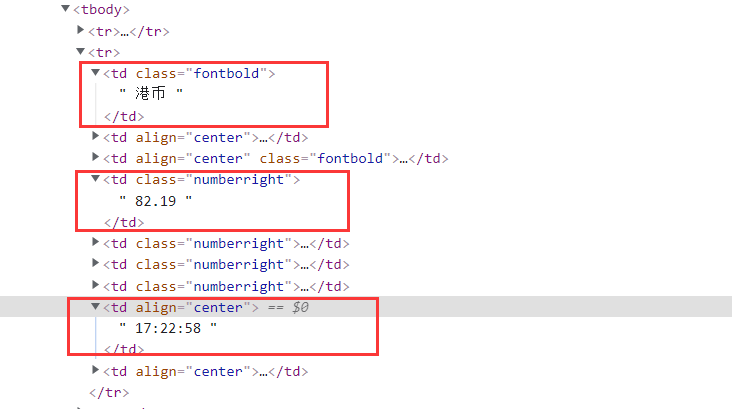
通过分析,信息都在tbody下边的tr标签中,各个tr标签存放对应外币的信息
这边比较坑的地方是这个网页的html的tbody是通过后期补全的,若使用Xpath去寻找元素时带上了tbody会找不到
用Xpath进行信息提取,extract_first()以字符串形式返回
同时用replace替换掉文本中的'\n',' '
# 一页有60条数据
for i in range(1, 61):
title = selector.xpath('//li[' + str(i) + ']/p[@class="name"]//a/@title').extract_first()#书名
detail = selector.xpath('//li[' + str(i) + ']/p[@class="detail"]/text()').extract_first()#描述
price = selector.xpath('//li[' + str(i) + ']/p[@class="price"]/span[@class="search_now_price"]/text()').extract_first()#价格
author = selector.xpath('//li[' + str(i) + ']/p[@class="search_book_author"]/span[1]/a[1]/text()').extract_first()#作者
date = selector.xpath('//li[' + str(i) + ']/p[@class="search_book_author"]/span[2]//text()').extract_first()#日期
publish = selector.xpath('//li[' + str(i) + ']/p[@class="search_book_author"]/span[3]/a[1]/text()').extract_first()#出版社
存入item的数据类型要字符串类型
item = Task42Item()#创建item项
#将信息存入item
item["Currency"] = currency
item["TSP"] = TSP
item["CSP"] = CSP
item["TBP"] = TBP
item["CBP"] = CBP
item["Time"] = Time
yield item
编写Pipelines
数据存储在 pipelines.py 中处理
将数据存入数据库,这边的操作与前面类似,便不展示了。
class Task42Pipeline:
def process_item(self, item, spider):
try:
# 存入数据库...
except Exception as err:
print(err)
return item
Settings
设置信息在settings.py中修改
将ROBOTSTXT_OBEY设置为False
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
修改PIPELINES,类名为pipelines中写的类(Task42Pipeline)
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'task4_1.pipelines.Task42Pipeline': 300,
}
请求头编写
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
执行函数
run.py 实现能够在编译器运行Scrapy
Spider 为爬虫名,在Spider.py中设置name
from scrapy import cmdline
cmdline.execute("scrapy crawl Spider -s LOG_ENABLED=False".split())
运行结果
用Navicat查看数据
心得体会
页面编写人员有时偷懒,会省去一些标签的编写,让浏览器自动补全,浏览器会对html文本进行一定的规范化,这一个网页便是这样,tbody标签是由浏览器补全的。
所以在数据爬取阶段,如果通过tbody标签定位元素,则会返回空。
在今后的学习生涯中,要多注意这种坑人的可能性。
作业三
-
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board -
输出信息:
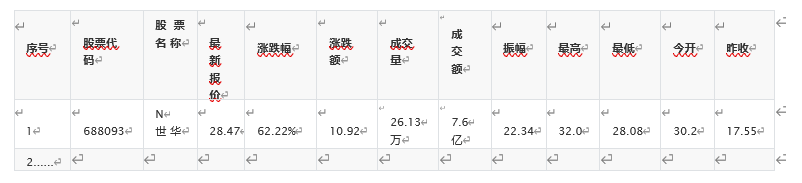
MySQL数据库存储和输出格式如下,
表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
实验过程
创建Webdriver
由于这是一个动态页面,用普通的requests爬取的html是没有经过渲染的。所以使用Selenium技术。
先创建一个浏览器对象,然后访问url
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board' # 起始url
driver = webdriver.Chrome() # 创建浏览器对象
driver.get(url)
ProcessSpider
通过分析,这个网页编写的非常规范,信息很整齐很有规律,没有多余的东西。
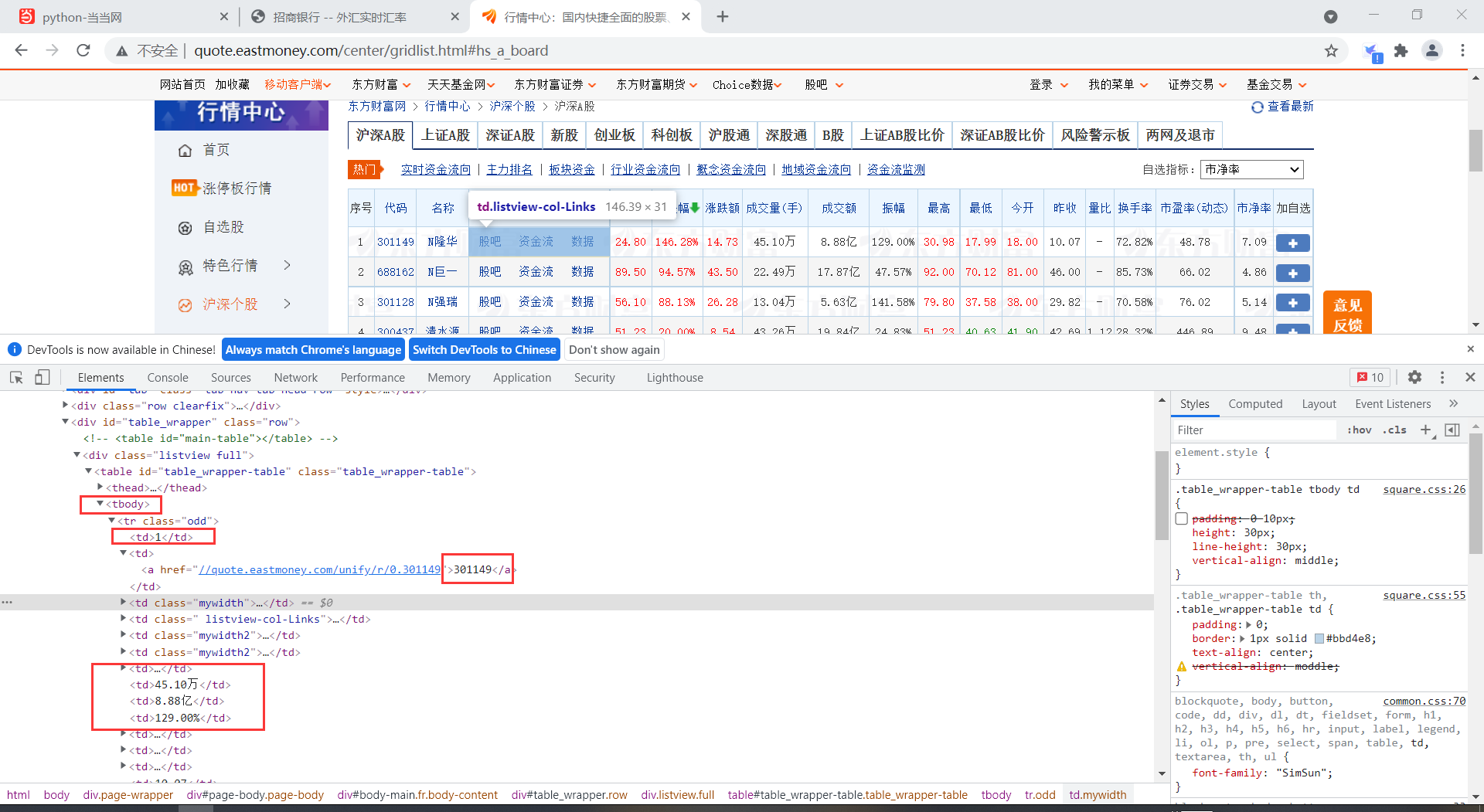
直接打印tbody下的文本,发现数据很整齐,格式规范,可以直接获取需要的数据。
获得文本信息后,先以换行分隔,得到每只股票的信息。
再以空格分隔每只股票,得到各个股票信息
def ProcessSpider(s):#传入对应板块的名称,方便存储分析
# 用Xpath寻找信息
page = driver.find_element(By.XPATH, '//*[@id="table_wrapper-table"]/tbody') # 定位信息位置,返回webElement对象
row = page.text.split('\n')#将数据以换行分隔,得到每只股票的信息,以列表返回
#遍历每只股票
for i in row:
row_data = i.split(' ')#以空格分隔数据
cate.append(s) #股票种类
id.append(row_data[0]) #序号
code.append(row_data[1]) #股票代码
name.append(row_data[2]) #股票名称
.........
实现点击翻页
翻页
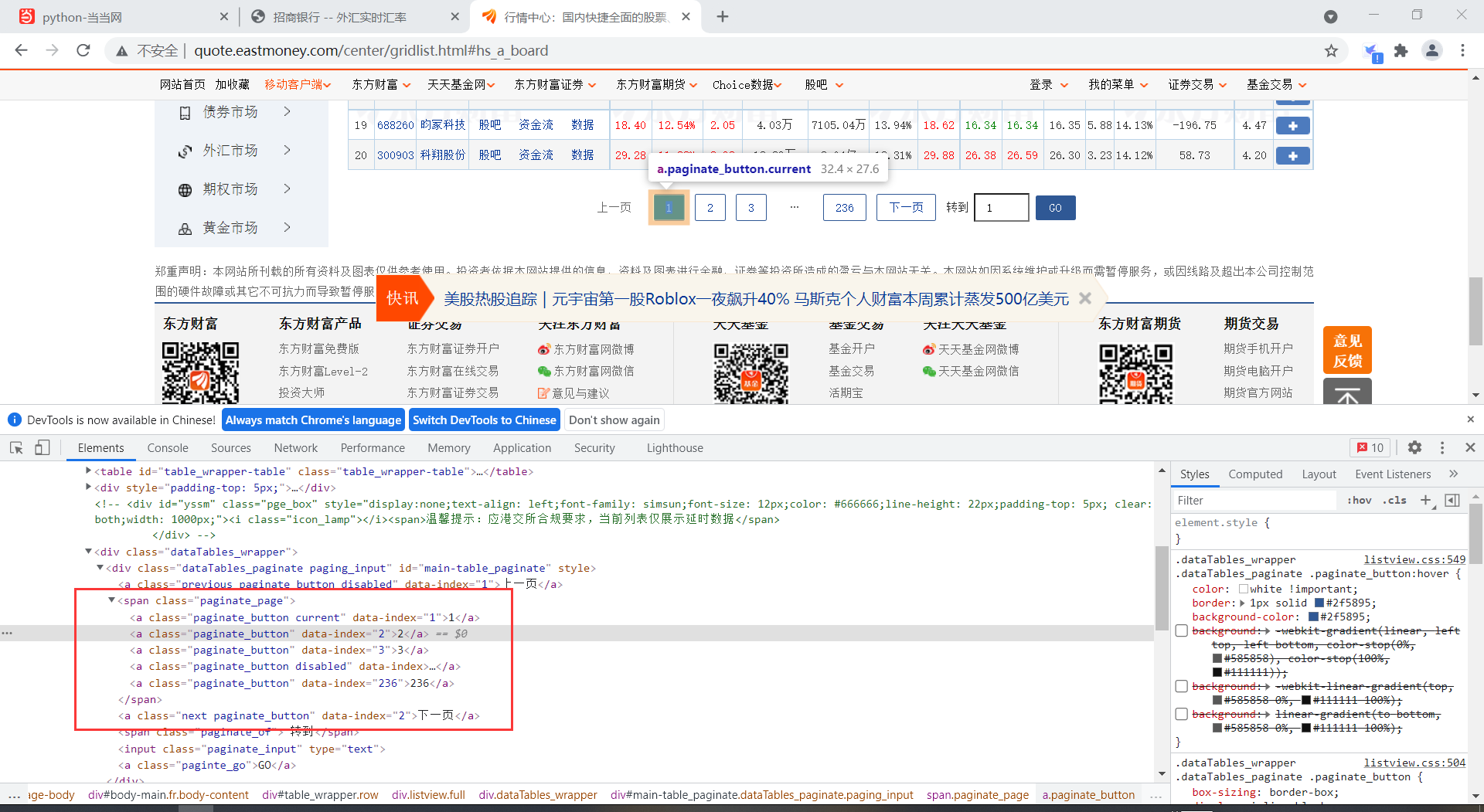
看以看到很多a标签,都是点击后访问下一页的入口
def Pageturn(index):#传入跳转的页面参数
try:
# Xpath定位到点击下一页的a标签,然后模拟点击
page_next = driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/span[1]/a[' + str(index) + ']')
page_next.click()
except Exception as err:
print(err)
滚动页面
为了板块跳转,需要回到上方才能点击,所以需要滚动页面。
def Scrollbar():# 滚动页面,回到最顶部
js_top = "var q=document.documentElement.scrollTop=0"
driver.execute_script(js_top)
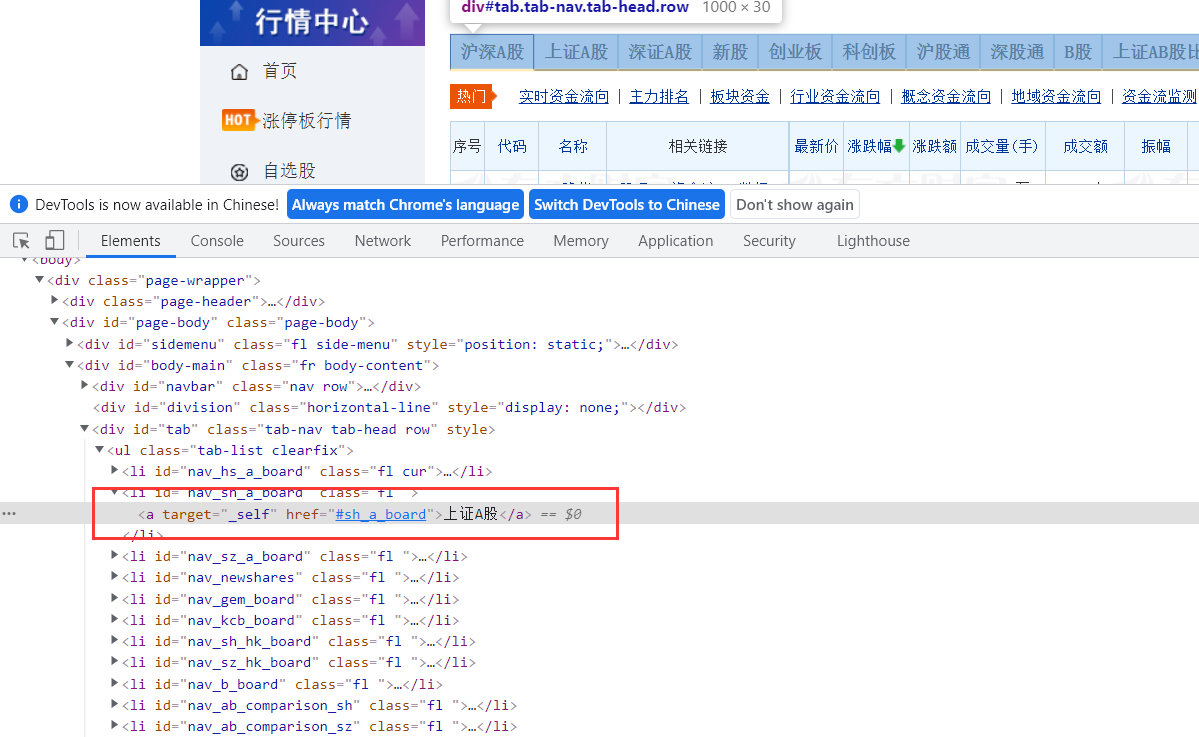
分析网页,找到点击的对应a标签,以上证A股信息为例
Scrollbar()#滑动滚动条,回到最顶部
next = driver.find_element(By.XPATH, '//*[@id="nav_sh_a_board"]/a')#用Xpath找板块跳转的a标签
next.click()#点击跳转上证A股板块
for i in range(2,4):#爬取1-2页的信息
ProcessSpider("上证A股")
Pageturn(i) #翻页
写入数据库部分与前面类似,便不展开细写。
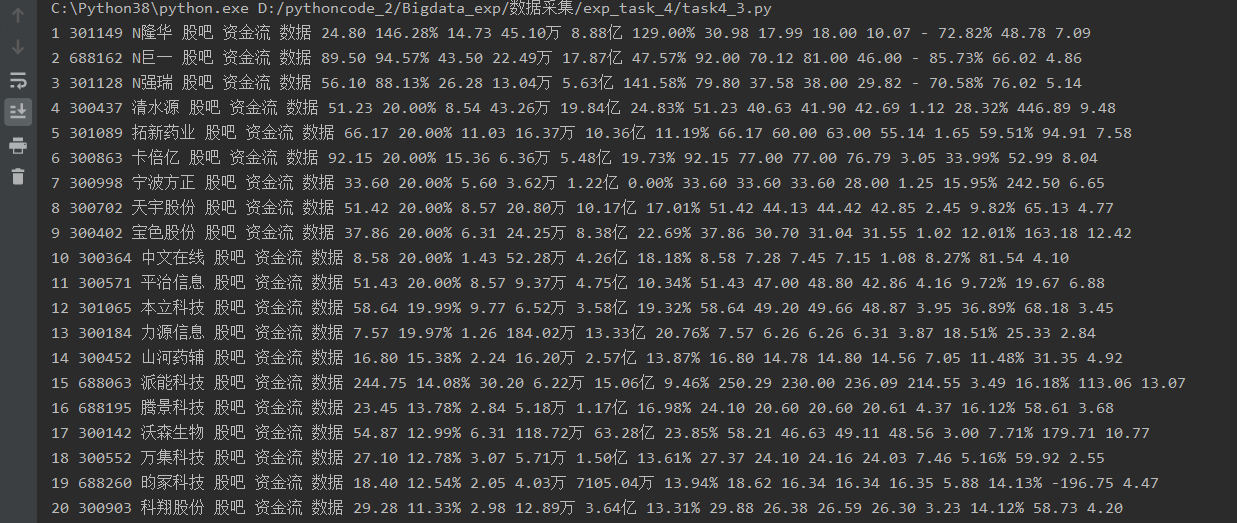
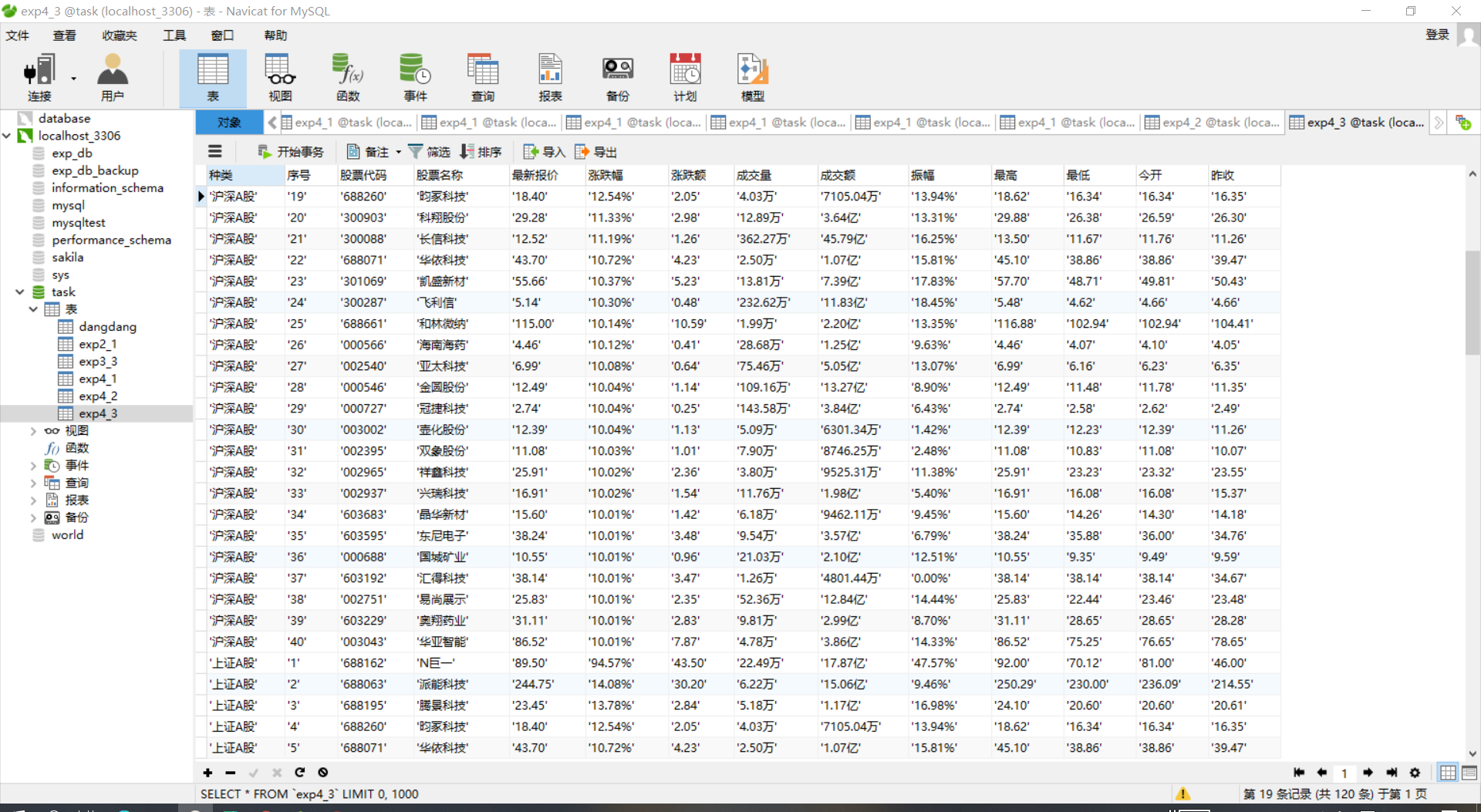
运行结果
前面加了对应的板块信息,方便查看
心得体会
使用Selenium实现模拟用户浏览网页,可以更方便爬取Ajax网页数据、等待HTML元素等内容,非常的快速方便。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号