数据采集第一次作业
作业1
-
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
-
输出信息:
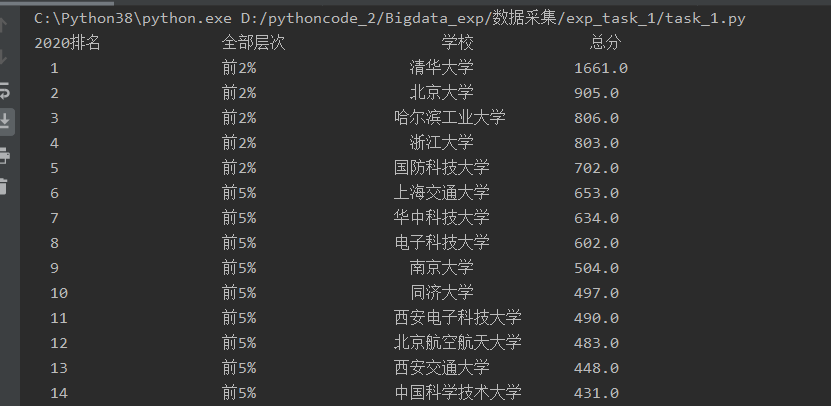
2020排名 2019排名 全部层次 学校类型 总分 1 2 前2% 中国人民大学 1069.0 2......
实验过程
获取html
def getHTMLText(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
resp = urllib.request.urlopen(req)
data = resp.read().decode("utf-8")#解码
return data
except:
return '异常'
通过正则寻找相关信息
通过审查元素,找到对应信息的位置,再分析其格式
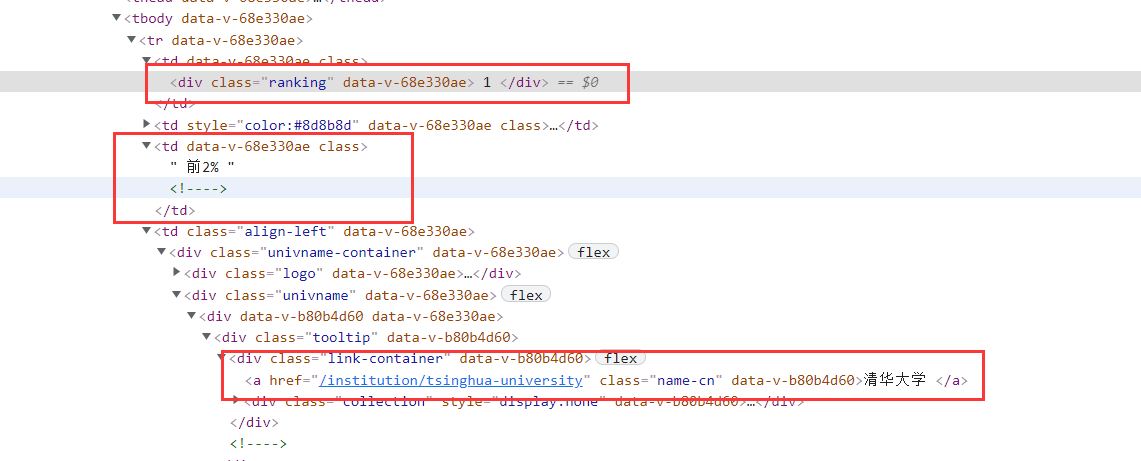
# 正则找排名所在位置
reg_ranking = r'<div class="ranking" data-v-68e330ae>(.*?)</div>'
res_ranking = re.findall(reg_ranking, data, re.S) # 设置re.S模式
for i in res_ranking:
# 替换其中的空格和换行
i = re.sub(' ', '', i)
i = re.sub('\n', '', i)
ranking.append(i)
# 正则寻找全部层次
reg_level = r'<td data-v-68e330ae>.*?(前.*?%).*?</td>'
res_level = re.findall(reg_level, data, re.S) # 设置re.S模式
for i in res_level:
level.append(i)
# 正则匹配学校名称
reg_name = r'<a href=".*" class="name-cn" data-v-b80b4d60>(.*)</a>'
res_name = re.findall(reg_name, data) # 不需要re.S
for i in res_name:
name.append(re.sub('<.*>', '', i)) # 将<>包裹的东西都洗掉再添加
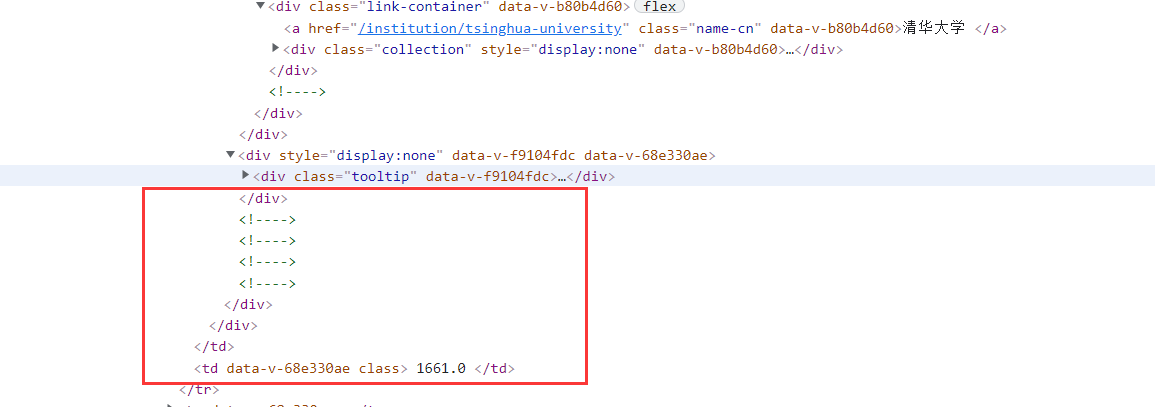
# 正则匹配学校总分
reg_score = r'<!----> <!----> <!----> <!----></div></div></td><td data-v-68e330ae>(.*?)</td>'
res_score = re.findall(reg_score, data, re.S) # 设置re.S模式
for i in res_score:
# 替换其中的空格和换行
i = re.sub(' ', '', i)
i = re.sub('\n', '', i)
score.append(i)
运行结果
心得体会
- 为了不给对方服务器造成困扰,可以先将爬取的html保存下来,再对其进行解析。
- 在正则匹配过程中,经常出现匹配失败的情况(含不可见字符\n,\r等),可以通过设置re.S模式解决该问题。
- 因为存在中文字符,会出现字符对齐问题,使得输出不美观,通过使用chr(12288)插入调试,解决对齐问题。
作业2
- 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
- 输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | No2 | Co | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | — |
| 2...... |
实验过程
获取html
def getHTMLText(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
resp.encoding = resp.apparent_encoding #解码
return resp.text
except:
return '异常'
使用apparent_encoding,可以从内容分析出响应的内容编码方式
通过Beautiful Soup寻找数据

发现里边的数据非常的整齐,都在标签内
通过css选择获取其信息,发现一个城市相关信息有9条,便以9为一次循环存储相关信息。再用.text即可获取其信息
#构建soup对象
soup = BeautifulSoup(data, 'lxml')
soup.prettify()
tags = soup.select("td[style='text-align: center; ']") # 通过css选择,得到以9个为一组的数据
cnt = 0 # 通过循环分别存储相应信息
for index in tags:
if cnt % 9 == 0:
city.append(index.text)
elif cnt % 9 == 1:
aqi.append(index.text)
elif cnt % 9 == 2:
pm25.append(index.text)
elif cnt % 9 == 3:
pm10.append(index.text)
elif cnt % 9 == 4:
so2.append(index.text)
elif cnt % 9 == 5:
no2.append(index.text)
elif cnt % 9 == 6:
co.append(index.text)
elif cnt % 9 == 7:
o3.append(index.text)
elif cnt % 9 == 8:
pollution.append(index.text.strip()) # 有\t ' '等,用strip()处理
cnt = cnt + 1
运行结果
使用chr(12288)来调整结构

心得体会
通过使用requests请求获取html,再用BeautifulSoup进行解析,直接通过标签获取相关信息。感觉BeautifulSoup是蛮好用的,但是需要先对其结构有一定了解。
作业3
-
要求:使用urllib和requests和re爬取一个给定网页( https://news.fzu.edu.cn/ )爬取该网站下的所有图片
-
输出信息:将自选网页内的所有jpg文件保存在一个文件夹中。
实验过程
获取html
分别用requests和urllib
使用requests:
def getHTMLText(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
# 解码比较奇特,utf-8是乱码,所以使用apparent_encoding,可以从内容分析出响应的内容编码方式
resp.encoding = resp.apparent_encoding
return resp.text
except:
return '异常'
#使用urllib:
def getHTMLText_urllib(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
resp = urllib.request.urlopen(req)
data = resp.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
unicodeData = dammit.unicode_markup
return unicodeData
except:
return '异常'
通过正则匹配相关信息

其图像地址都存在<img src=“......”中,故正则匹配能方便得匹配相关信息
def find_data():
img_url = [] # 存放图片的url
reg = r'<img src="(.*?)"' #获取所有的图像地址(包含了.jpg/.png等)
res = re.findall(reg, data, re.S) # 设置re.S模式。
for i in res:
if i[-3:] == 'jpg': # 只需要.jpg文件,判断是否以jpg为结尾的图片
img_url.append(url + i) # 如果是.jpg结尾的图片,直接拼接url
return img_url
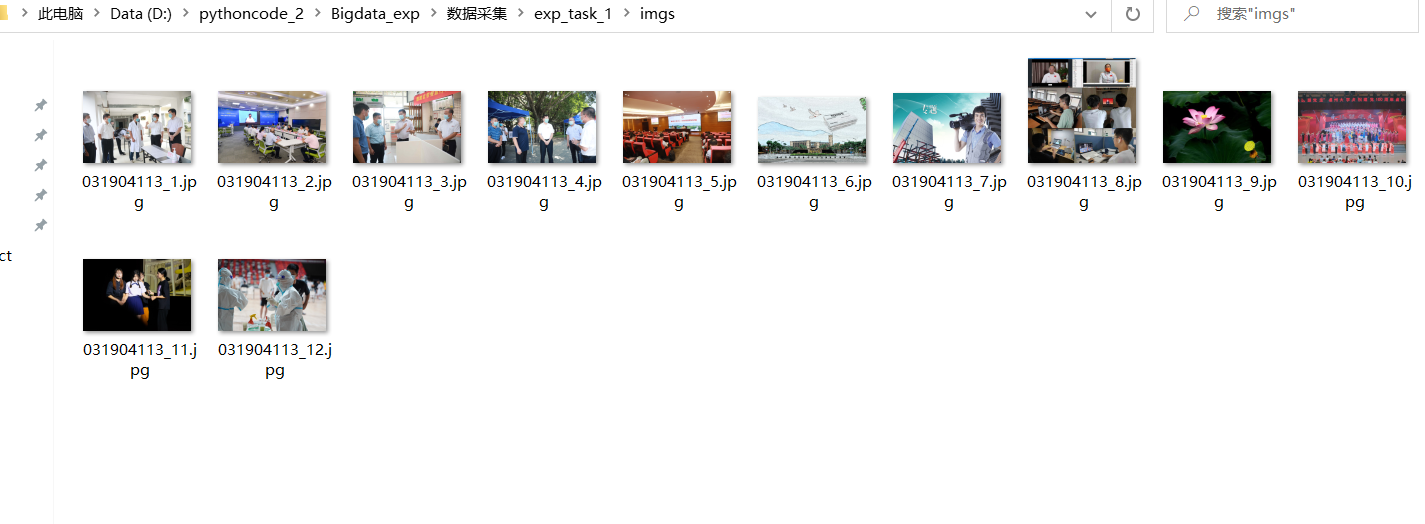
保存图像到本地:
def Save_img(list):
cnt = 1 # 控制循环,限制读取图片个数
for i in range(len(list)): # list的长度,图像个数
resp = requests.get(list[i])
f = open('./imgs/031904113_' + str(cnt) + '.jpg', 'wb') # 二进制保存
f.write(resp.content) # 写入
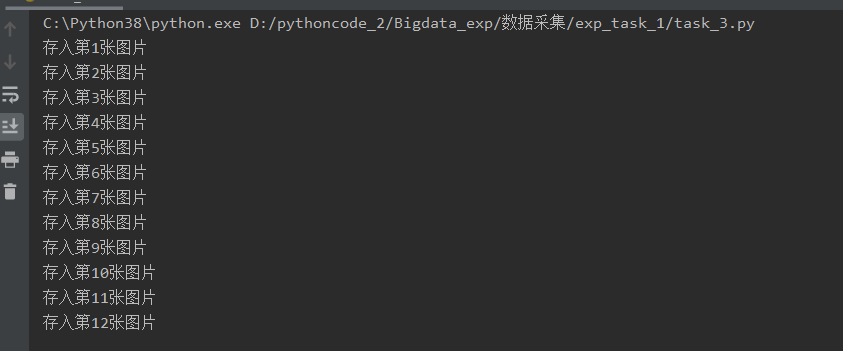
print('存入第' + str(cnt) + '张图片')
cnt += 1
运行结果!
心得体会
这一题和之前爬取商品图片的相似,需要爬取图片的地址,一个相对简单的正则匹配便可以将他们整出来。
正则匹配最需要注意的地方便是换行等看不见的字符,一个小小的错误就会导致匹配失败。
可以通过在线正则调试自己的正则表达式是否正确,代替一次又一次的运行程序调试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号