
google论文:MapReduce
1. 导论
1.1 定义
先给个定义: MapReduce是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。用户首先创建一个Map函数处理一个基于key/value pair的数据集合,输出中间的基于key/value pair的数据集合;然后再创建一个Reduce函数用来合并所有的具有相同中间key值的中间value值。
使用这个抽象模型,我们只要表述我们想要执行的简单运算即可,而不必关心并行计算、容错、数据分布、负载均衡等复杂的细节,这些问题都被封装在了一个库里面。设计这个抽象模型的灵感来自Lisp和许多其他函数式语言的Map和Reduce的原语。
1.2 概述
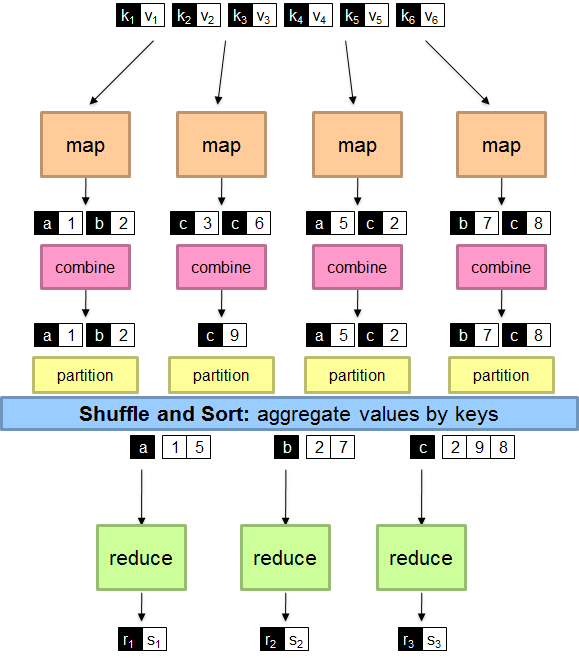
- Programmers must specify:
- map (k, v) → <k’, v’>*
- reduce (k’, v’) → <k’, v’>*
- All values with the same key are reduced together
- Optionally, also:
- partition (k’, number of partitions) → partition for k’
- Often a simple hash of the key, e.g., hash(k’) mod n
- Divides up key space for parallel reduce operations
- combine (k’, v’) → <k’, v’>*
- Mini-reducers that run in memory after the map phase
- Used as an optimization to reduce network traffic
- partition (k’, number of partitions) → partition for k’
- The execution framework handles everything else…
- Scheduling: assigns workers to map and reduce tasks
- “Data distribution”: moves processes to data
- Synchronization: gathers, sorts, and shuffles intermediate data
- Errors and faults: detects worker failures and restarts
- Limited control over data and execution flow
- All algorithms must expressed in m, r, c, p
- You don’t know:
- Where mappers and reducers run
- When a mapper or reducer begins or finishes
- Which input a particular mapper is processing
- Which intermediate key a particular reducer is processing
2. 实现
2.1 流程
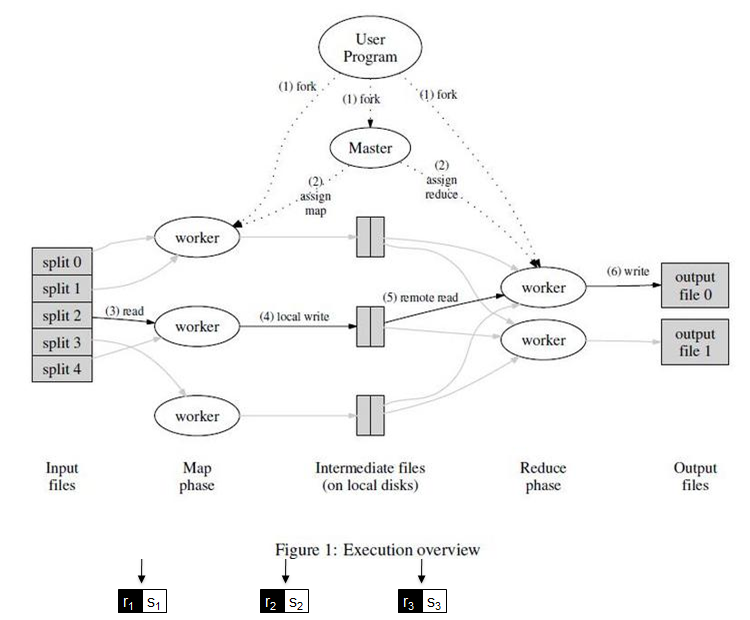
上图展示了我们的MapReduce实现中操作的全部流程。
- 用户程序首先调用的MapReduce库将输入文件分成M个数据片段,每个数据片段的大小一般从16MB到64MB。然后用户程序在机群中创建大量的程序副本。
- 这些程序副本中的有一个特殊的程序–master。副本中其它的程序都是worker程序,由master分配任务。有M个Map任务和R个Reduce任务将被分配,master将一个Map任务或Reduce任务分配给一个空闲的worker。
- 被分配了map任务的worker程序读取相关的输入数据片段,从输入的数据片段中解析出key/value pair,然后把key/value pair传递给用户自定义的Map函数,由Map函数生成并输出的中间key/value pair,并缓存在内存中。
- 缓存中的key/value pair通过分区函数分成R个区域,之后周期性的写入到本地磁盘上。缓存的key/value pair在本地磁盘上的存储位置将被回传给master,由master负责把这些存储位置再传送给Reduce worker。
- 当Reduce worker程序接收到master程序发来的数据存储位置信息后,使用RPC从Map worker所在主机的磁盘上读取这些缓存数据。当Reduce worker读取了所有的中间数据后,通过对key进行排序后使得具有相同key值的数据聚合在一起。由于许多不同的key值会映射到相同的Reduce任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。
- Reduce worker程序遍历排序后的中间数据,对于每一个唯一的中间key值,Reduce worker程序将这个key值和它相关的中间value值的集合传递给用户自定义的Reduce函数。Reduce函数的输出被追加到所属分区的输出文件。
- 当所有的Map和Reduce任务都完成之后,master唤醒用户程序。在这个时候,在用户程序里的对MapReduce调用才返回。
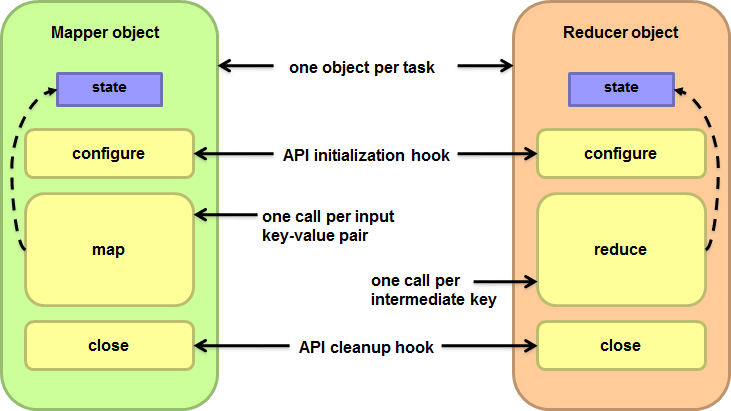
2.2 map和Reduce的同步
- Cleverly-constructed data structures
- Bring partial results together
- Sort order of intermediate keys
- Control order in which reducers process keys
- Partitioner
- Control which reducer processes which keys
- Preserving state in mappers and reducers
- Capture dependencies across multiple keys and values
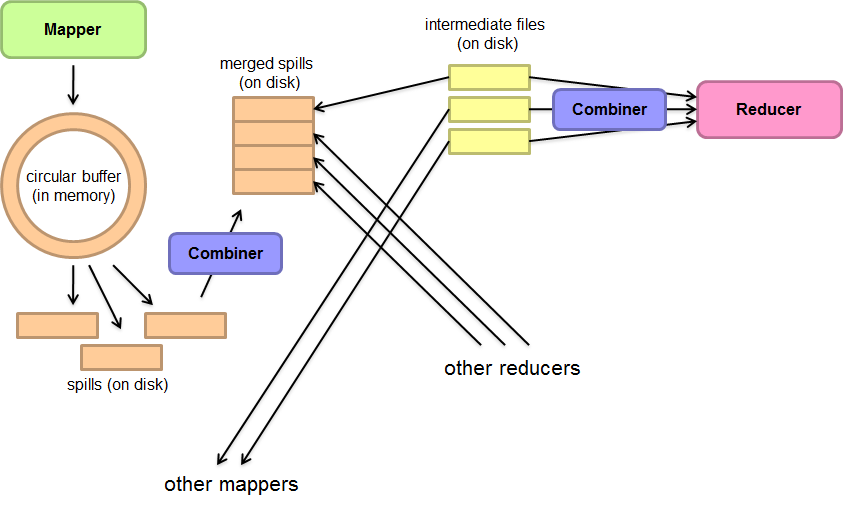
2.3 本地聚合
- Ideal scaling characteristics:
- Twice the data, twice the running time
- Twice the resources, half the running time
- Why can’t we achieve this?
- Synchronization requires communication
- Communication kills performance
- Thus… avoid communication!
- Reduce intermediate data via local aggregation
- Combiners can help
2.4 Shuffle and Sort
2.5 Master
Master持有一些数据结构,它存储每一个Map和Reduce任务的状态(空闲、工作中或完成),以及Worker机器(非空闲任务的机器)的标识。
Master就像一个数据管道,中间文件存储区域的位置信息通过这个管道从Map传递到Reduce。因此,对于每个已经完成的Map任务,master存储了Map任务产生的R个中间文件存储区域的大小和位置。当Map任务完成时,Master接收到位置和大小的更新信息,这些信息被逐步递增的推送给那些正在工作的Reduce任务。
master周期性的ping每个worker。如果在一个约定的时间范围内没有收到worker返回的信息,master将把这个worker标记为失效。所有由这个失效的worker完成的Map任务被重设为初始的空闲状态,之后这些任务就可以被安排给其他的worker。同样的,worker失效时正在运行的Map或Reduce任务也将被重新置为空闲状态,等待重新调度。
master周期性的将数据写入磁盘,即检查点(checkpoint)。如果这个master任务失效了,可以从最后一个检查点开始启动另一个master进程。然而,由于只有一个master进程,master失效后再恢复是比较麻烦的,因此我们现在的实现是如果master失效,就中止MapReduce运算。客户可以检查到这个状态,并且可以根据需要重新执行MapReduce操作。
3. 性能优化
3.1 straggler
影响一个MapReduce的总执行时间最通常的因素是straggler(落伍者):在运算过程中,如果有一台机器花了很长的时间才完成最后几个Map或Reduce任务,导致MapReduce操作总的执行时间超过预期。
当一个MapReduce操作接近完成的时候,master调度备用(backup)任务进程来执行剩下的、处于处理中状态(in-progress)的任务。无论是最初的执行进程、还是备用(backup)任务进程完成了任务,我们都把这个任务标记成为已经完成。我们调优了这个机制,通常只会占用比正常操作多几个百分点的计算资源。我们发现采用这样的机制对于减少超大MapReduce操作的总处理时间效果显著。
3.2 分区函数(partitioning function)
我们在中间key上使用分区函数来对数据进行分区,之后再输入到后续任务执行进程。一个缺省的分区函数是使用hash方法(比如,hash(key) mod R)进行分区。hash方法能产生非常平衡的分区。然而,有的时候,其它的一些分区函数对key值进行的分区将非常有用。
使用“hash(Hostname(urlkey)) mod R”作为分区函数就可以把所有来自同一个主机的URLs保存在同一个输出文件中。
3.3 顺序保证
在给定的分区中,中间key/value pair数据的处理顺序是按照key值增量顺序处理的。
3.4 Combiner函数
用户指定一个可选的combiner函数,combiner函数首先在本地将这些记录进行一次合并,然后将合并的结果再通过网络发送出去。
一般情况下,Combiner和Reduce函数是一样的。Combiner函数和Reduce函数之间唯一的区别是MapReduce库怎样控制函数的输出。
3.5 跳过损坏的记录
- Map/Reduce functions sometimes fail for particular inputs
- Best solution is to debug & fix
- Not always possible ~ third-party source libraries
- On segmentation fault:
- Send UDP packet to master from signal handler
- Include sequence number of record being processed
- If master sees two failures for same record:
- Next worker is told to skip the record
- Best solution is to debug & fix
4. 要点和例子
4.1 Points need to be emphasized
- No reduce can begin until map is complete
- Master must communicate locations of intermediate files
- Tasks scheduled based on location of data
- If map worker fails any time before reduce finishes, task must be completely rerun
- MapReduce library does most of the hard work for us!
4.2 例子
- 分布式的Grep:Map函数输出匹配某个模式的一行,Reduce函数是一个恒等函数,即把中间数据复制到输出。
- 计算URL访问频率:Map函数处理日志中web页面请求的记录,然后输出(URL,1)。Reduce函数把相同URL的value值都累加起来,产生(URL,记录总数)结果。
- 倒转网络链接图:Map函数在源页面(source)中搜索所有的链接目标(target)并输出为(target,source)。Reduce函数把给定链接目标(target)的链接组合成一个列表,输出(target,list(source))。
- 每个主机的检索词向量:检索词向量用一个(词,频率)列表来概述出现在文档或文档集中的最重要的一些词。Map函数为每一个输入文档输出(主机名,检索词向量),其中主机名来自文档的URL。Reduce函数接收给定主机的所有文档的检索词向量,并把这些检索词向量加在一起,丢弃掉低频的检索词,输出一个最终的(主机名,检索词向量)。
- 倒排索引:Map函数分析每个文档输出一个(词,文档号)的列表,Reduce函数的输入是一个给定词的所有(词,文档号),排序所有的文档号,输出(词,list(文档号))。所有的输出集合形成一个简单的倒排索引,它以一种简单的算法跟踪词在文档中的位置。
- 分布式排序:Map函数从每个记录提取key,输出(key,record)。Reduce函数不改变任何的值。这个运算依赖分区机制(在4.1描述)和排序属性(在4.2描述)。
5. Hadoop
术语对照
|
翻译 |
Hadoop术语 |
Google术语 |
相关解释 |
|
作业 |
Job |
Job |
用户的每一个计算请求,就称为一个作业。 |
|
作业服务器 |
JobTracker |
Master |
用户提交作业的服务器,同时,它还负责各个作业任务的分配,管理所有的任务服务器。 |
|
任务服务器 |
TaskTracker |
Worker |
任劳任怨的工蜂,负责执行具体的任务。 |
|
任务 |
Task |
Task |
每一个作业,都需要拆分开了,交由多个服务器来完成,拆分出来的执行单位,就称为任务。 |
|
备份任务 |
Speculative Task |
Buckup Task |
每一个任务,都有可能执行失败或者缓慢,为了降低为此付出的代价,系统会未雨绸缪的实现在另外的任务服务器上执行同样一个任务,这就是备份任务。 |
具体可以看博文http://www.cnblogs.com/duguguiyu/archive/2009/02/28/1400278.html

