一文搞定深度优先搜索、广度优先搜索
首发公众号:
bigsai,请勿搬运
前言
你问一个人听过哪些算法,那么深度优先搜索(dfs)和宽度优先搜索(bfs)那肯定在其中,很多小老弟学会dfs和bfs就觉得好像懂算法了,无所不能,确实如此,学会dfs和bfs暴力搜索枚举确实利用计算机超强计算大部分都能求的一份解,学会dfs和bfs去暴力杯混分是一个非常不错的选择!

五大经典算法的回溯算法其实也是dfs的一种应用,是不是回忆起被折磨的八皇后问题。基础的dfs和bfs学习来思想很容易,写出来模板代码也不难,但很多时候需要在此基础上灵活变通就有不小难度了。
不过dfs 和bfs初步学习搞懂原理比较简单,但是想要精通 dfs和bfs还是很难的,因为很多问题是在此基础上进行变形优化的,比如dfs你可能考虑各种剪枝问题,bfs可能会涉及很多贪心的策略,有的还要考虑到记忆化的问题、双向bfs、bfs+dfs等等才能更好解决的问题,不过本文讲的相对基础,不同的延伸需要自己刷题去学习才行。
邻接矩阵和邻接表
dfs和bfs一般用于处理图论的问题,那么在看问题之前首先要关注图的存储问题,正常一般用邻接矩阵或者邻接表存储图(对于十字链表、压缩矩阵之类空间优化这里不进行讨论)。
邻接矩阵:
邻接矩阵就是用数组(二维)表示图,通常这种图我们会对各个节点顺序的编号,在矩阵内数值表示图的联通情况或者路径长度。
如果是无权图:那么一般用boolean数组的01表示联通性,如果是有权图那么数组的值就用来表示两者路径长度,如果为0那么就表示不通。另外如果图是无向图那么这个矩阵是对称的,如果是有向图那么大概率不是对称的。
具体可以看下面例子,这种操作方式条理更清晰并且操作方便,当然,这种情况很容易造成空间浪费,所以有人进行空间优化,或者是邻接表的方式存储图。

邻接表:
观察上面的领接矩阵,如果节点很多但是联通路径很少,那么就浪费了太多的存储空间,这种情况就更适合邻接表。
邻接表一般是数组套链表,比起邻接矩阵节省不少空间(直接存储联通信息或者路径),在存储的时候可以根据数据格式要求灵活运用容器(无权图省事一些)。
但是正常的无向图依然会重复浪费一半空间,就有十字链表,多重链接表等等出现优化(大佬们的优化是真的牛批),但在算法逻辑上稍复杂,不过一般图论算法更注重的是算法的优化这里就不介绍十字链表等,一个邻接表存储的图可以看下图:

深度优先搜索(dfs)
概念:
深度优先搜索属于图算法的一种,英文缩写为DFS即Depth First Search.其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次.
简单的说,dfs就是在一个图中按照一个规则进行搜索,一般基于递归实现,对于我们来说dfs就像一个黑魔法一样,设计好算法它就自动搜索,所以我们要注意的是算法初始化、搜索规则、结束条件。二叉树的前序遍历就是一个最简单的dfs遍历。
我们通常使用邻接表或者邻接矩阵储存图的信息,这里例子使用邻接矩阵完成!
对于dfs的流程来说,大致可以认为是这样:
(1)某个节点开始先按照一个方向一直遍历到尽头,同时标记已经走过的点。
(2)遍历到尽头后回退到上一个点,同时清除当前点的标记。往下一个方向遍历一次,然后继续重复步骤(1).
(3)一直到所有流程都走完,即回退到起点。
在遍历的过程中记得需要标记 因为不进行标记会出现死循环,标记就代表这个点被用过不能用了,而撤回标记就说明这个点又能重新使用了。
举个例子,例如一个全排列s a i 当s被枚举到就要标记这个s不能被使用(不可能ssss一直下去吧),并且遍历到s a时候a也不能使用,到s a i 时候到尽头回退 s a 依然要回退s 此时 a和i都被解但是上次指标方向为a(for 循环到的位置),那么下一次就要往下个方向i 组成s i,然后在s i a,同理回退到s i ,到s,下面两个方向都被枚举过所以还要回退到,解放了s a i 但是第一个方向s已经走过,开始从a 剩下的步骤依次类推就得到了。
不过全排列这是一维空间的dfs运用,在标记时候可以选择boolean数组对应位置true标记用过,false表示没用过。除此之外也可使用动态数组List使用过先删除对应位置元素向下递归进行搜索,然后结束后再对应位置插入也行(不是很推荐,效率比较低)。
对于上面图片中图的dfs,得到其中一个dfs搜索的序列(可能有多个)可以用代码来表示一下:
public class dfs {
static boolean isVisit[];
public static void main(String[] args) {
int map[][]=new int[7][7];
isVisit=new boolean[7];
map[0][1]=map[1][0]=1;
map[0][2]=map[2][0]=1;
map[0][3]=map[3][0]=1;
map[1][4]=map[4][1]=1;
map[1][5]=map[5][1]=1;
map[2][6]=map[6][2]=1;
map[3][6]=map[6][3]=1;
isVisit[0]=true;
dfs(0,map);//从0开始遍历
}
private static void dfs(int index,int map[][]) {
// TODO Auto-generated method stub
System.out.println("访问"+(index+1)+" ");
for(int i=0;i<map[index].length;i++)//查找联通节点
{
if(map[index][i]>0&&isVisit[i]==false)
{
isVisit[i]=true;
dfs(i,map);
}
}
System.out.println((index+1)+"访问结束 ");
}
}
大致顺序访问为

广度优先搜素(bfs)
概念:
BFS,其英文全称是Breadth First Search。 BFS并不使用经验法则算法。从算法的观点,所有因为展开节点而得到的子节点都会被加进一个先进先出的队列中。一般的实验里,其邻居节点尚未被检验过的节点会被放置在一个被称为 open 的容器中(例如队列或是链表),而被检验过的节点则被放置在被称为 closed 的容器中。(open-closed表)
简单来说,bfs就是从某个节点开始按层遍历,估计大部分人第一次接触bfs的时候是在学习数据结构的二叉树的层序遍历!借助一个队列一层一层遍历。第二次估计就是在学习图论的时候,给你一个图,让你写出一个bfs遍历的顺序,此后再无bfs...
如果从路径上走来看,dfs就是一条跑的很快的疯狗,到处乱咬,没路了就跑回来去其他地方继续,而bfs就像是一团毒气,慢慢延伸!
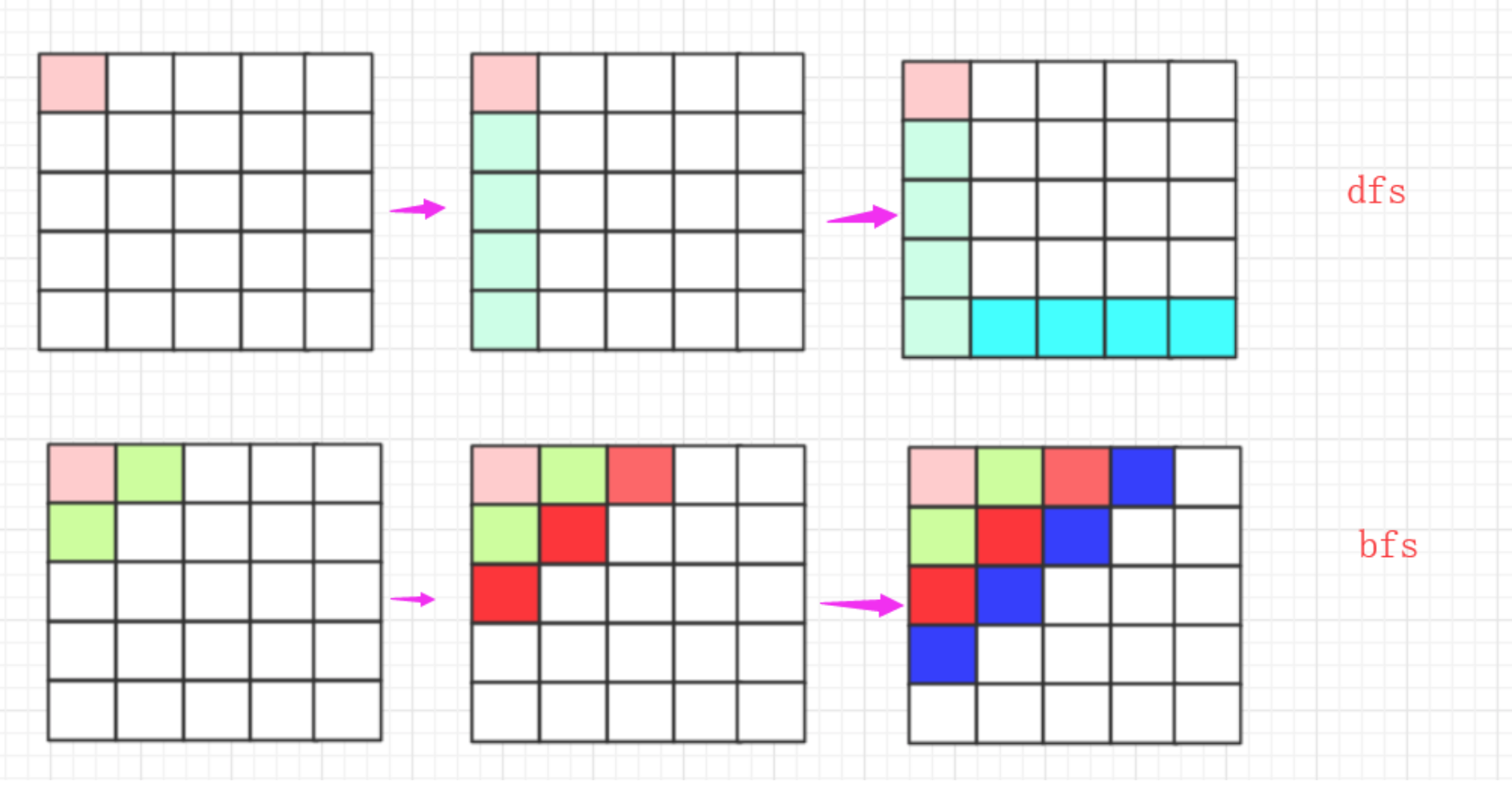
在实现上朴素的bfs就是控制一个队列,后进先出进行层序遍历,但很多时候可能有场景需求节点有权值可能就需要使用优先队列。
就拿上述的图来说,我们使用邻接表来实现一个bfs遍历。
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
public class bfs {
public static void main(String[] args) {
List<Integer> map[]=new ArrayList[7];
boolean isVisit[]=new boolean[7];
for(int i=0;i<map.length;i++)//初始化
{
map[i]=new ArrayList<Integer>();
}
map[0].add(1);map[0].add(2);map[0].add(3);
map[1].add(0);map[1].add(4);map[1].add(5);
map[2].add(0);map[2].add(6);
map[3].add(0);map[3].add(6);
map[4].add(1);
map[5].add(1);
map[6].add(2);map[6].add(3);
Queue<Integer>q1=new ArrayDeque<Integer>();
q1.add(0);isVisit[0]=true;
while (!q1.isEmpty()) {
int va=q1.poll();
System.out.println("访问"+(va+1));
for(int i=0;i<map[va].size();i++)
{
int index=map[va].get(i);
if(!isVisit[index])
{
q1.add(index);
isVisit[index]=true;
}
}
}
}
}

搜索之延伸
本文主要任务是帮助初学者认清dfs和bfs,比较偏基础,但是事实中dfs和bfs比较偏向实战。
对于dfs和bfs,有些区别也有些共性,例如在迷宫很多问题dfs能解决bfs也能解决。
对于dfs一般解决的经典问题有:
- 二叉树的搜索遍历(非层序)
- 经典全排列、组合、子集问题
- 回溯算法之八皇后问题
- 迷宫搜索问题(能否找到)
- 其他图搜索
而bfs一般解决的问题有:
- 二叉树层序搜索遍历(各种变形例如分层输出、之字形等等空间优化)
- 无权图的最短路径
- 其他迷宫搜索问题(节点带某些权值的)
- 其他问题
当然这里面罗列不全,dfs关注更多的可能是剪枝问题或者记忆化,剪枝就是剪掉没必要的搜索,记忆化就是防止太多重复操作。而bfs关注更多的可能是贪心策略选择(大部分搜索可能有一些附加的条件)可能需要使用优先队列来解决。
然而,当数据达到一定程度,我们使用简单的方法肯定会爆炸的,***。就可能需要一些特殊的巧妙方法处理,比如想不到的剪枝优化、优先队列、A、dfs套bfs,又或者利用一些非常厉害的数学方法比如康托展开(逆展开)等等。而今天在这里,我们谈谈双向bfs,体验一下算法的奥妙!
什么样的情况可以使用双向bfs来优化呢?其实双向bfs的主要思想是问题的拆分吧,比如在一个迷宫中可以往下往右行走,问你有多少种方式从左上到右下。
正常情况下,我们就是搜索遍历,如果迷宫边长为n,那么这个复杂度大概是2^n级别.
但是实际上我们可以将迷宫拆分一下,比如根据对角线(比较多),将迷宫一分为二。其实你的结果肯定必然经过对角线的这些点对吧!我们只要分别计算出各个对角线各个点的次数然后相加就可以了!
怎么算? 就是从(0,0)到中间这个点mid的总次数为n1,然后这个mid到(n,n)点的总次数为n2,然后根据排列组合总次数就是n1*n2(n1和n2正常差不多大)这样就可以通过乘法减少加法的运算次数啦!
简单的说,从数据次数来看如果直接搜索全图经过下图的那个点的次数为n1*n2次,如果分成两个部分相乘那就是n1+n2次。两者差距如果n1,n2=1000左右,那么这么一次差距是平方(根号)级别的。从搜索图形来看其实这么一次搜索是本来一个n*n大小的搜索转变成n次(每次大概是(n/2)*(n/2)大小的迷宫搜索两次)。也就是如果18*18的迷宫如果使用直接搜索,那么大概2^18次方量级,而如果采用双向bfs,那么就是2^9这个量级。

例题实战一下,就拿一道经典双向bfs问题给大家展示一下吧!
题目链接:http://oj.hzjingma.com/contest/problem?id=20&pid=8#problem-anchor

分析:对于题目的要求还是很容易理解的,就是找到所有的路径种类,再判断其中是对称路径的有几个输出即可!
对于一个普通思考是这样的,首先是进行dfs,然后动态维护一个字符串,每次跑到最后判断这个路径字符串是否满足对称要求,如果满足那么就添加到容器中进行判断。可惜很遗憾这样是超时的,仅能通过40%的样例。
接着用普通bfs进行尝试,维护一个node节点,每次走的时候路径储存起来其实这个效率跟dfs差不多依然超时。只能通过40%数据。
接下来就开始双向bfs进行分析!
(1) 既然只能右下,那么对角线的那个位置的肯定是中间的那个字符串的!它的存在不影响是否对称的(n*n的迷宫路径长度为n-1 + n为奇数).
(2) 我们判断路径是否对称,只需要判断从(1,1)到对角节点k(设为k节点)的路径有没有和从(n,n)到k相同的。如果有路径相同的那么就说明这一对构成对称路径
(3) 在具体实现上,我们对每个对角线节点可以进行两次bfs(一次左上到(1,1),一次右下到(n,n)).并且将路径放到两个hashset(set1,set2)中,跑完之后用遍历其中一个hashset中的路径,看看另一个set是否存在该路径,如果存在就说明这个是对称路径放到 总的hashset(set) 中。对角线每个位置都这样判断完最后只需要输出总的hashset(set)的集合大小即可!
ac代码如下:
import java.util.ArrayDeque;
import java.util.HashSet;
import java.util.Queue;
import java.util.Scanner;
import java.util.Set;
public class test2 {
static class node{
int x;
int y;
String path="";
public node() {}
public node(int x,int y,String team)
{
this.x=x;
this.y=y;
this.path=team;
}
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
Set<String>set=new HashSet<String>();//储存最终结果
int n=Integer.parseInt(sc.nextLine());
char map[][]=new char[n][n];
for(int i=0;i<n;i++)
{
String string=sc.nextLine();
map[i]=string.toCharArray();
}
Queue<node>q1=new ArrayDeque<node>();//左上的队列
Queue<node>q2=new ArrayDeque<node>();//右下的队列
for(int i=0;i<n;i++)
{
q1.clear();q2.clear();
Set<String>set1=new HashSet<String>();//储存zuoshang
Set<String>set2=new HashSet<String>();//储右下
q1.add(new node(i,n-1-i,""+map[i][n-1-i]));
q2.add(new node(i,n-1-i,""+map[i][n-1-i]));
while(!q1.isEmpty()&&!q2.isEmpty())
{
node team=q1.poll();
node team2=q2.poll();
if(team.x==n-1&&team.y==n-1)//到终点,将路径储存
{
//System.out.println(team2.path);
set1.add(team.path);
set2.add(team2.path);
}
else {
if(team.x<n-1)//可以向下
{
q1.add(new node(team.x+1, team.y, team.path+map[team.x+1][team.y]));
}
if(team.y<n-1)//可以向右
{
q1.add(new node(team.x, team.y+1, team.path+map[team.x][team.y+1]));
}
if(team2.x>0)//上
{
q2.add(new node(team2.x-1, team2.y, team2.path+map[team2.x-1][team2.y]));
}
if(team2.y>0)//左
{
q2.add(new node(team2.x, team2.y-1, team2.path+map[team2.x][team2.y-1]));
}
}
}
for(String va:set1)
{
if(set2.contains(va))
{
set.add(va);
}
}
}
System.out.println(set.size());
}
}

总结
dfs和bfs是图论中非常经典的搜索算法,两种算法的重要程度都非常高,这里面主要对其简单介绍,对于普通开发者,能够用dfs和bfs能够解决二叉树问题、迷宫搜索问题等基础简单的就够了(面试官不会那么骚难为你)。
如果理解比较困难,多看教程、多刷题,多刷题之后每做一题算法跑的大概流程是有个数的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号