


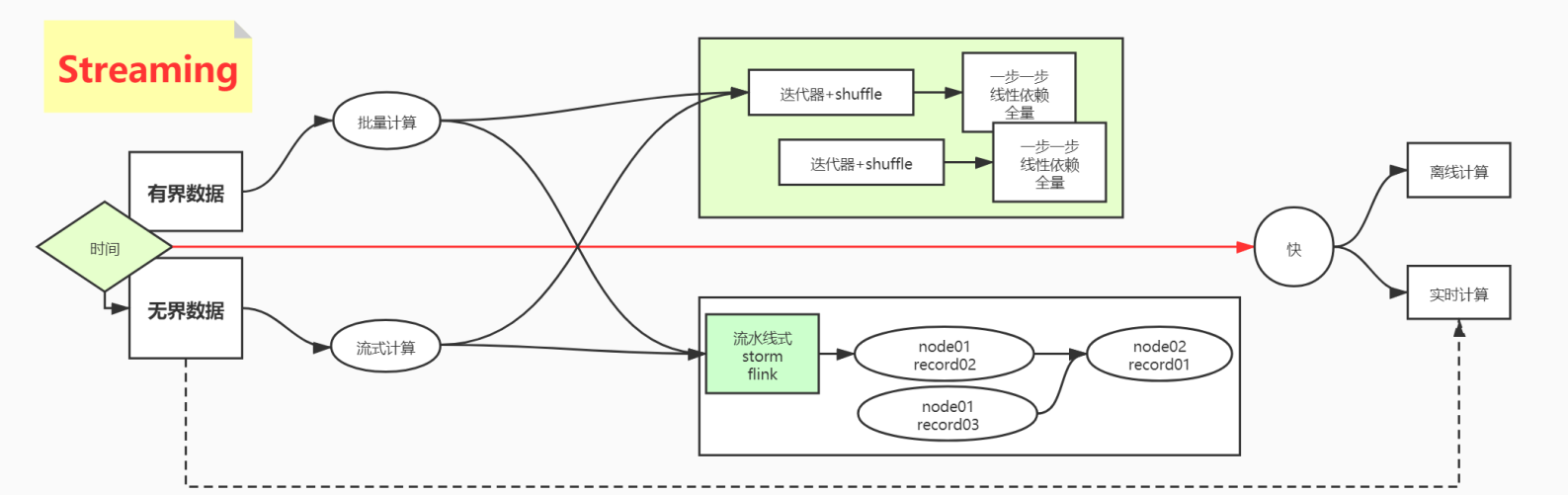
数据处理方式有两种
- 有界数据 --> 批量处理
- 无界数据 --> 流式处理
数据按照时间处理方式两种
- 离线计算
- 实时计算
spark streaming 微处理数据方式
- 获取元数据,先receiver(并短暂存储) 在进行计算
- 获取元数据,放入到队列中(存储) ,直接direct进行计算
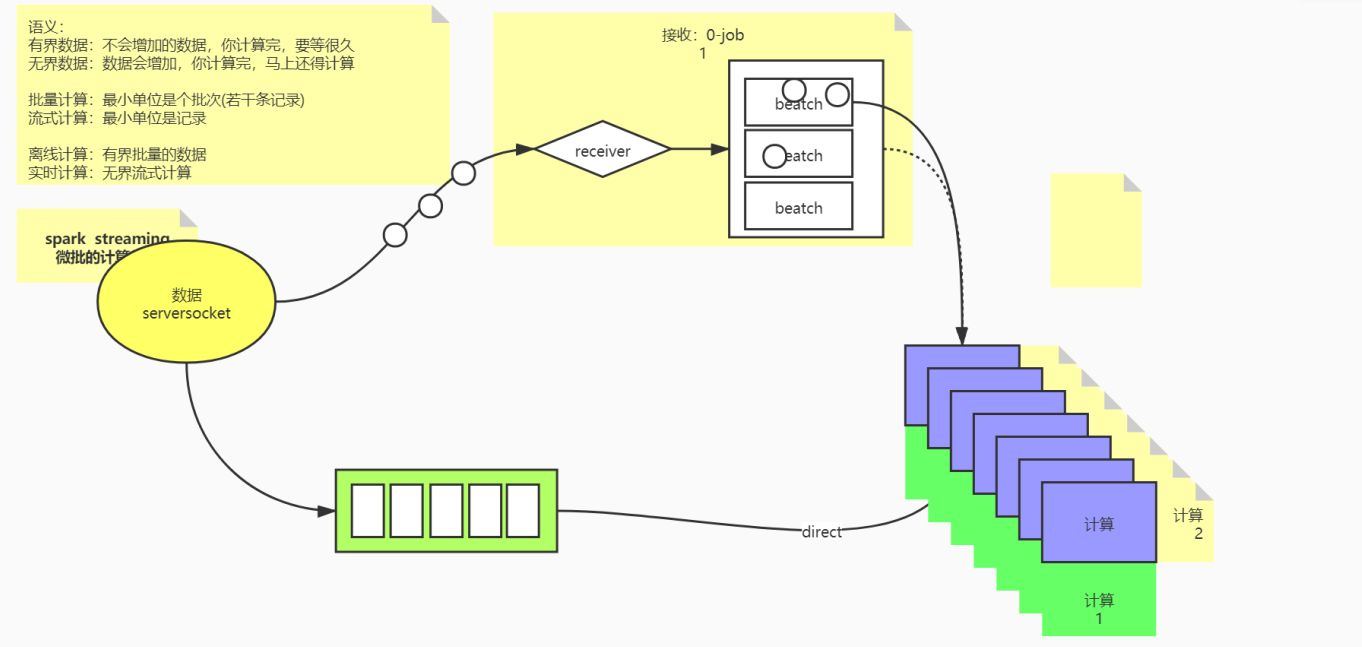
服务器方式模仿元数据
- ip: 192.168.75.91
- nc -l 8080
- 输入 spark world , hello world
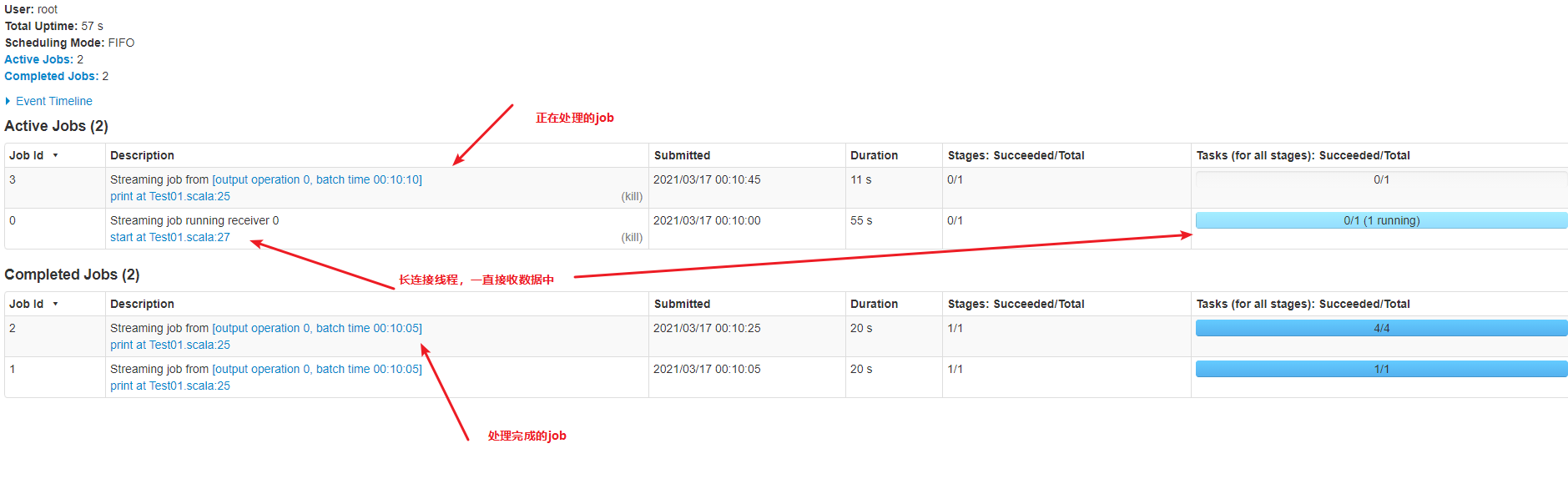
def main(args: Array[String]): Unit = { // local[5]写5是因为1个线程用来接收、一个线程用来计算 // 1个给receiverJob的task. 2.另一个给batch计算的job val conf = new SparkConf().setAppName("receiverJob").setMaster("local[5]") // 微批的流式计算,时间去定义批次,(while --> 时间间隔触发job) val streamingContext = new StreamingContext(conf, Seconds(5)) streamingContext.sparkContext.setLogLevel("ERROR") // hello world val dataDStream = streamingContext.socketTextStream("192.168.75.91", 6379) // hello // world val words = dataDStream.flatMap(_.split(" ")) //转换算子 val wordsCount = words.map((_, 1)).reduceByKey(_+_) // 转换算子 wordsCount.print() // 输出算子 streamingContext.start() //执行算子 // 主线程不退出 streamingContext.awaitTermination() }
结果:
-------------------------------------------
Time: 1615907230000 ms
-------------------------------------------
spark 1
world 2
hello 1
-------------------------------------------
Time: 1615907235000 ms
-------------------------------------------
本地模仿数据
// 线程制造数据
def main(args: Array[String]): Unit = { // 本地模仿制造数据 val listen = new ServerSocket(8889) println(" server start") while (true) { val client:Socket = listen.accept() new Thread() { override def run(): Unit = { var num = 0 if (client.isConnected) { val outputStream = client.getOutputStream val printer = new PrintStream(outputStream) while (client.isConnected) { num += 1 printer.println(s"hello ${num}") } } } }.start() } }
// streaming接收数据直接打印结果 def main(args: Array[String]): Unit = { // local[5]写5是因为1个线程用来接收、一个线程用来计算 // 1个给receiverJob的task. 2.另一个给batch计算的job val conf = new SparkConf().setAppName("receiverJob").setMaster("local[9]") // 微批的流式计算,时间去定义批次,(while --> 时间间隔触发job) val streamingContext = new StreamingContext(conf, Seconds(5)) streamingContext.sparkContext.setLogLevel("ERROR") val dataDStream = streamingContext.socketTextStream("localhost", 8889) dataDStream.print() streamingContext.start() //执行算子 // 主线程不退出 streamingContext.awaitTermination() } 结果: Time: 1615908955000 ms ------------------------------------------- hello 95668 hello 95669 hello 95670 hello 95671 hello 95672 hello 95673 hello 95674 hello 95675 hello 95676 hello 95677 ... ------------------------------------------- Time: 1615908960000 ms ------------------------------------------- hello 241620 hello 241621 hello 241622 hello 241623 hello 241624 hello 241625 hello 241626 hello 241627 hello 241628 hello 241629
// 制作数据增加线程阻塞 while (client.isConnected) { num += 1 printer.println(s"hello ${num}") Thread.sleep(1000) } 打印结果: ------------------------------------------- Time: 1615909175000 ms ------------------------------------------- hello 2 hello 3 hello 4 hello 5 hello 6 ------------------------------------------- Time: 1615909180000 ms ------------------------------------------- hello 7 hello 8 hello 9 hello 10 hello 11
阻塞接收数据为20秒
def main(args: Array[String]): Unit = { // local[5]写5是因为1个线程用来接收、一个线程用来计算 // 1个给receiverJob的task. 2.另一个给batch计算的job val conf = new SparkConf().setAppName("receiverJob").setMaster("local[9]") // 微批的流式计算,时间去定义批次,(while --> 时间间隔触发job) val streamingContext = new StreamingContext(conf, Seconds(5)) streamingContext.sparkContext.setLogLevel("ERROR") val dataDStream = streamingContext.socketTextStream("localhost", 8889) val res: DStream[(String, String)] = dataDStream.map(_.split(" ")).map(vars=>{ Thread.sleep(20000) (vars(0),vars(1)) }) res.print() streamingContext.start() //执行算子 // 主线程不退出 streamingContext.awaitTermination() }
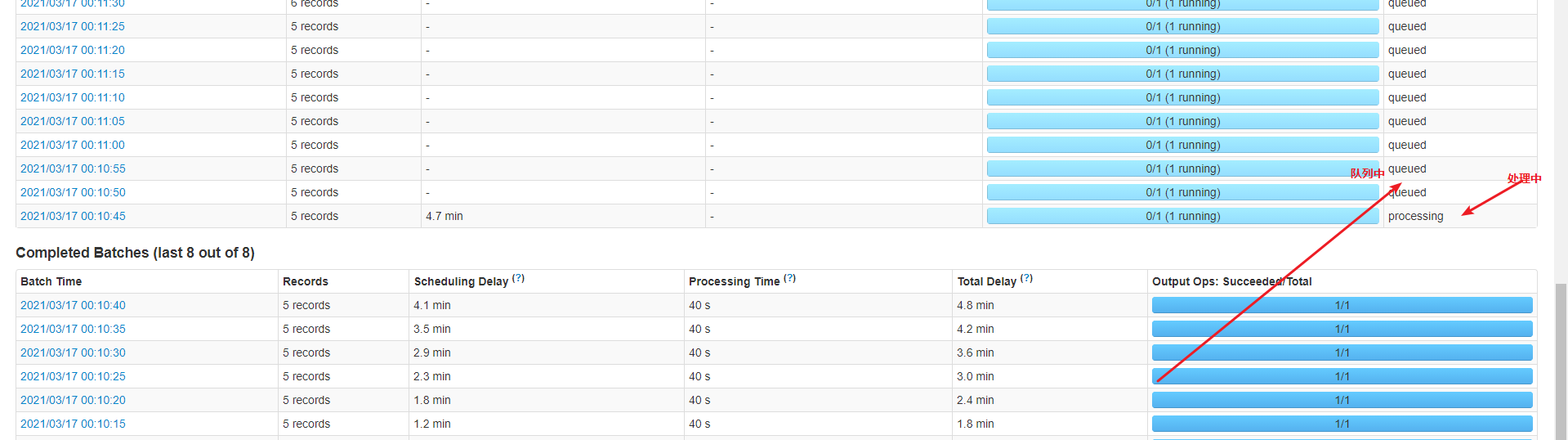
stage


straming中可以看到很多的队列,说明任务处理是阻塞模式,虽然有启动9个线程,一个接收数据,还有8个,只有其中一个在处理任务,其他排队阻塞,并没有并行处理
改进接收数据方式
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("streaming").setMaster("local[9]") val streamingContext = new StreamingContext(conf, Seconds(5)) streamingContext.sparkContext.setLogLevel("ERROR") val dstream: ReceiverInputDStream[String] = streamingContext.receiverStream(new CustormReceiver("localhost", 8889)) dstream.print() streamingContext.start() streamingContext.awaitTermination() } 创建:CustormReceiver class CustormReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.DISK_ONLY) { override def onStart(): Unit = { new Thread { override def run(): Unit = { ooxx() } }.start() } private def ooxx(): Unit = { val server = new Socket(host, port) val reader = new BufferedReader(new InputStreamReader(server.getInputStream)) var line = reader.readLine() while (!isStopped() && line != null) { store(line) line = reader.readLine() } } override def onStop(): Unit = ??? }
结果:
-------------------------------------------
Time: 1615910635000 ms
-------------------------------------------
hello 2
hello 3
hello 4
hello 5
hello 6
-------------------------------------------
Time: 1615910640000 ms
-------------------------------------------
hello 7
hello 8
hello 9
hello 10
hello 11
socketTextStream和receiverStream区别
-
socketTextStream排队执行,每次只有一个任务在处理,其他的在队列中等待
-
receiverStream 任务并列执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号