

官网
- http://spark.apache.org/
- 下载spark-2.3.4-bin-hadoop2.6.tgz
单机启动
- 进入 bin 目录 启动 ./spark-shell
- 测试:
sc.textFile("/tmp/spark/test.txt").flatMap(x => x.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
- 结果
(spark,2) (hello,3) (msb,1) (good,1) (world,1)
集群搭建
- 基础设施
- jdk 1.8
- ke01、ke02、ke03、ke04
- HDFS环境、zookeeper环境
- 四台机器免密
- 文件配置
- spark-2.3.4-bin-hadoop2.6.tgz放到 /opt/bigdata目录下
- 配置/etc/profile环境
- 文件配置
- 配置conf/slaves
1.复制slaves.template 为 slaves 2. 删除文件内localhost 配置从节点为:ke02、ke03、ke04 - 配置conf/spark-env.sh.template
1.复制spark-env.sh.template一份为spark-env.sh 2.配置spark-env.sh //export文件配置目录 export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoop // 主机地址 export SPARK_MASTER_HOST=ke01 // 主机端口号 export SPARK_MASTER_PORT=7077 // 主机WEBUI页面 export SPARK_MASTER_WEBUI_PORT=8080 // 一台机器多少内核 export SPARK_WORKER_CORES=4 // 一台机器多少内存 export SPARK_WORKER_MEMORY=4g
- 配置conf/slaves
启动集群
- 启动zk
- 启动HDFS
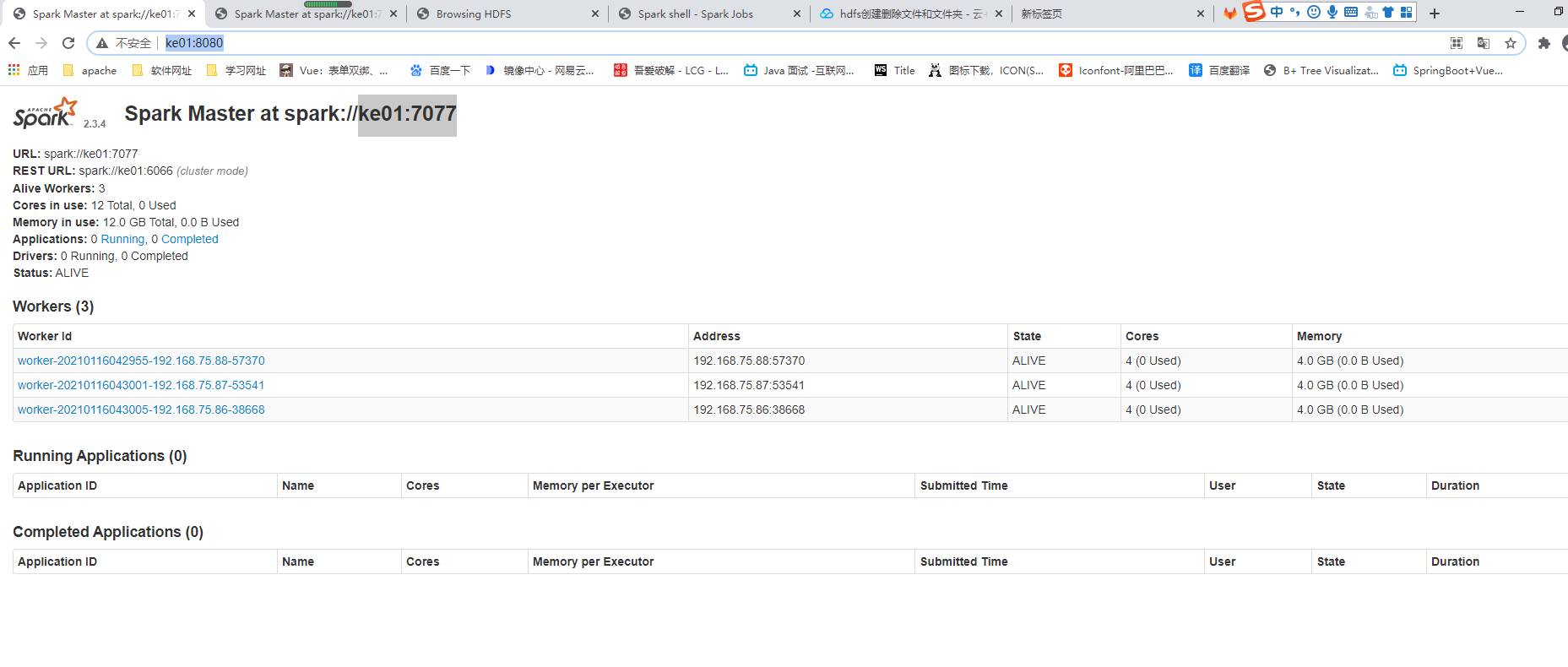
- 启动spark ./start-all.sh
启动日志:只有spark资源层跑起来了
[root@ke01 sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/bigdata/spark-2.3.4-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-ke01.out ke04: starting org.apache.spark.deploy.worker.Worker, logging to /opt/bigdata/spark-2.3.4-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ke04.out ke02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/bigdata/spark-2.3.4-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ke02.out ke03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/bigdata/spark-2.3.4-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ke03.out
访问页面:http://ke01:8080/,可以看到资源层cores、workers信息、memory,以及主机地址
启动spark-shell
- ./spark-shell --help 可以查看shell启动文档信息
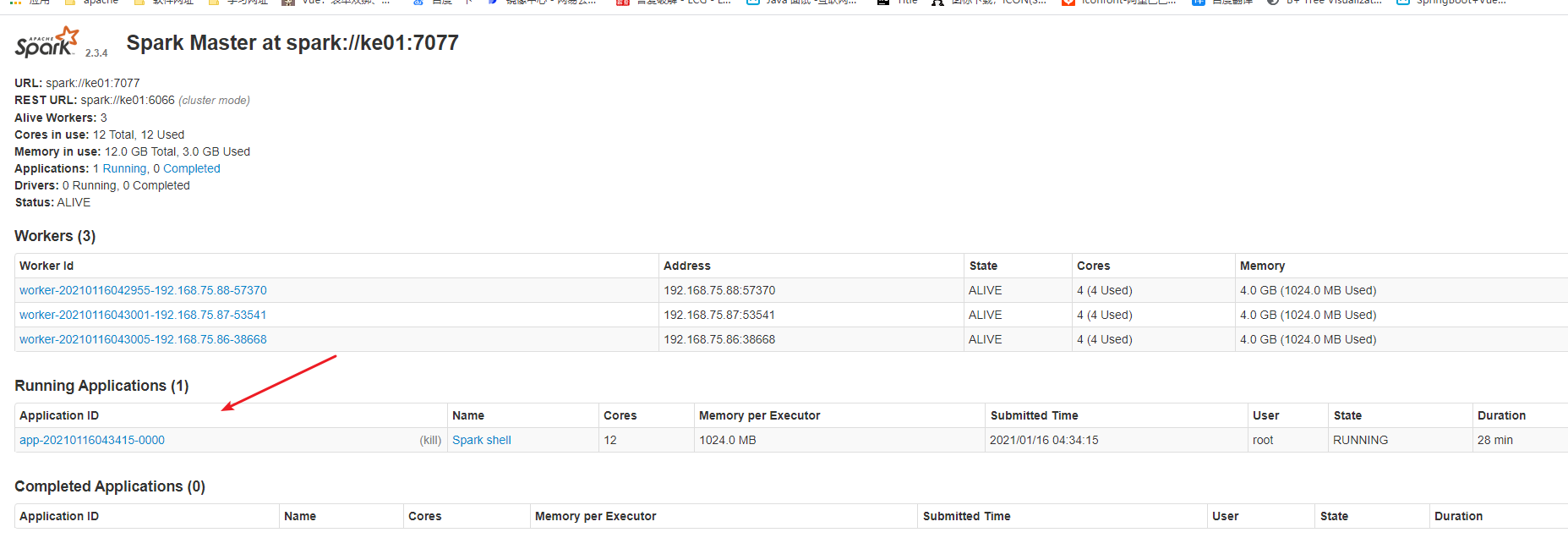
- 启动: ./spark-shell --master spark://ke01:7077
- 可以看到8080页面有了application
![]()
- 访问:http://ke01:4040/jobs/
- 可以查看到job的stages
- 运行两遍发现,用时明显减少,说明集群有缓存

集群高可用
//conf目录下 cp spark-defaults.conf.template spark-defaults.conf spark.deploy.recoveryMode ZOOKEEPER spark.deploy.zookeeper.url ke02:2181,ke03:2181,ke04:2181 spark.deploy.zookeeper.dir /kespark // 开启日志 spark.eventLog.enabled true // 日志写入的目录 spark.eventLog.dir hdfs://mycluster/spark_log // 日志读取的目录,以后重启spark可以读取以前跑的记录 从默认端口18080读取 spark.history.fs.logDirectory hdfs://mycluster/spark_log //分发其他机器 scp spark-defaults.conf ke02:`pwd` //修改ke02也为主机 目录 conf/spark-env.sh export SPARK_MASTER_HOST=ke02 启动: ke01: [root@ke01 sbin]# ./start-all.sh ke02: [root@ke02 sbin]# ./start-master.sh 测试: http://ke01:8080/ Status: STANDBY http://ke02:8080/ Status: ALIVE // 启动历史日志记录 [root@ke01 sbin]# ./start-history-server.sh 查看历史记录: http://ke01:18080/ // 登录spark [root@ke01 bin]# ./spark-shell --master spark://ke01:7077,ke02:7077 // 查看zk [zk: localhost:2181(CONNECTED) 0] ls / [zookeeper, yarn-leader-election, hadoop-ha, hbase, kespark] [zk: localhost:2181(CONNECTED) 1] ls /kespark [leader_election, master_status]
PI演练
//学习网址 http://spark.apache.org/docs/2.3.4/submitting-applications.html // 使用π案例进行演练,PI代码地址:https://github.com/apache/spark/blob/v2.3.4/examples/src/main/scala/org/apache/spark/examples/SparkPi.scala // jar包地址: /opt/bigdata/spark-2.3.4-bin-hadoop2.6/examples/jars /spark-examples_2.11-2.3.4.jar 脚本: [root@ke01 jars]# $SPARK_HOME/bin/spark/spark-submit \ > --class org.apache.spark.examples.SparkPi \ > --master spark://ke01:7077,ke02:7077 \ > ./spark-examples_2.11-2.3.4.jar \ > 10 脚本-文件方式: vi submit.sh class=org.apache.spark.examples.SparkPi jar=$SPARK_HOME/examples/jars/spark-examples_2.11-2.3.4.jar $SPARK_HOME/bin/spark-submit \ --master spark://ke01:7077,ke02:7077 \ --class $class \ $jar \ 1000 . submit.sh
调度
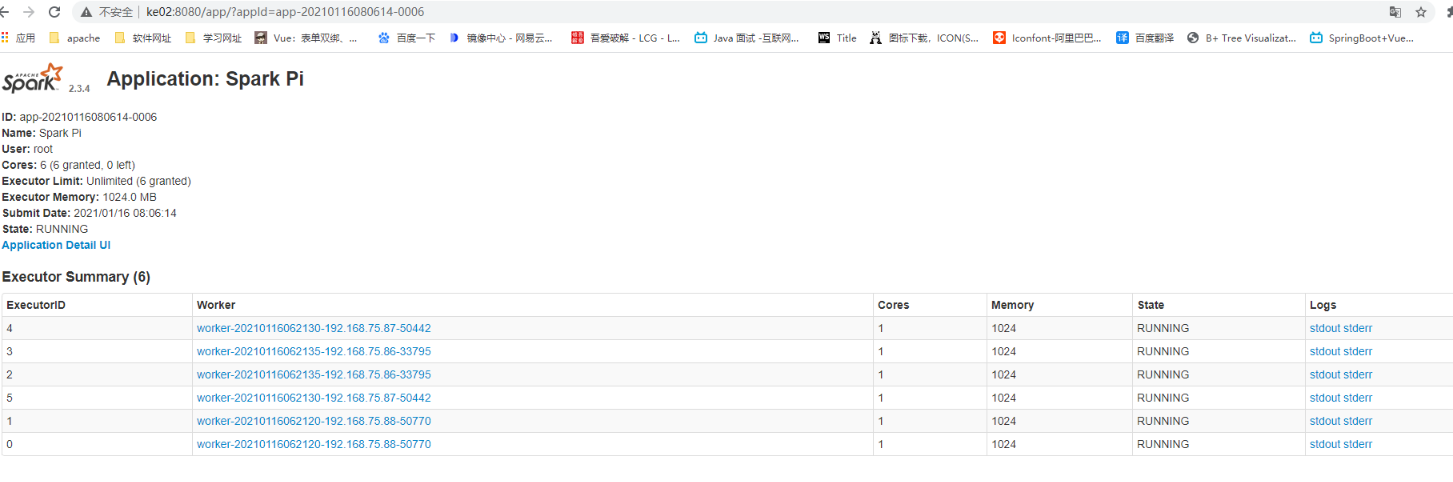
// 脚本增加--deploy-mode 8080页面可以查看Running Drivers、Completed Drivers --deploy-mode cluster /** 当--executor-cores 1 --total-executor-cores 6 executor是6 当--executor-cores 4 --total-executor-cores 6 executor是1 既先满足executor-cores 不能超过total-executor-cores */ --total-executor-cores 6 --executor-cores 1 --executor-memory 1024m

 浙公网安备 33010602011771号
浙公网安备 33010602011771号