OO第三单元总结
本博客对第三单元的三次作业进行了总结。对技术博客的5个要求,把其中的(1),(4),(5)合并分析,按照三次作业分类。最后分析了测试策略(要求(2)),容器选择的经验(要求(3))。
一、设计策略、架构维护和算法选择
规格里为了描述的简便和清晰,采用了平凡的数据结构。然而我的程序为了实现规格的要求,并不需要使用与规格相同的数据结构,而只要保证输出正确即可。也就是对于每个修改指令,我的程序应当能作出正确的反应,调整内部数据结构;对于每个查询指令,我的程序应当能输出预期结果。为了降低时空复杂度,自然可以采用更合适的数据结构。
下面分三次作业分别叙述我采用的设计策略,对于每次作业中与前一次作业相同的设计,不重复叙述。
1.第一次作业
第一次作业要求我们维护一个初级社交网络,并提供“增”,“查”的方法。可以把这个社交网络抽象为一个带权无向图,对社交网络的维护,就是对图的维护。具体实现方案如下:
| 指令 | 规格的要求 | 对图的维护 | 算法或数据结构 | 时间复杂度 |
|---|---|---|---|---|
| add_person | 添加一个人 | 添加一个点 | map | O(1) |
| add_relation | 添加两个人的关系 | 添加一条带权边 | map | O(1) |
| query_value | 查询两个人的关系 | 查询某条边的权 | map | O(1) |
| compare_name | 比较两个人的名字 | O(1) | ||
| query_name_rank | 查询姓名排序 | O(n) | ||
| query_people_sum | 查询总人数 | 查询节点总数 | O(1) | |
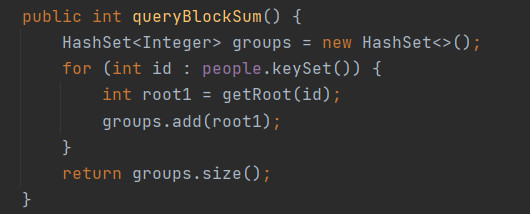
| query_circle | 查询两个人能否直接或间接相连 | 查询两个节点是否连通 | 并查集 | O(1) |
| query_block_sum | 查询不能与前面的人相连的总人数 | 查询连通块的个数 | 并查集 | O(n) |
这样,除了compare_name和query_name_rank之外的所有的指令需求,就都转化成了对图的修改或查询请求。如何实现规格的问题,就转化成了如何维护图结构的问题。
用map代替list
规格里使用列表作为数据的图,列表能够反应各个person加入到社交网络的顺序。然而在所有的查询需求中,并没有对这个顺序的查询,所以使用列表是不必要的(即使有这个需求,也未必采用列表)。map在命中时只需要常量时间复杂度。所以可以使用map来优化。
对network来说,每次加入一个人,都要利用这个人的ID查询原有的人。因此可以采用map来实现(键值对为<Integer,Person>)。这个map也存储了图的各个节点。
对于Person里的acquaintances也是如此,同样用map来实现(键值对为<Integer,Integer>,意义是<熟人ID,value>)。图随即以邻接表的形式得到了存储。
并查集
query_circle需要查询两个人是否连通,即这两个人是否位于同一个连通分量;query_block_sum需要查询本图中连通分量的个数。为了能够以更优的时间复杂度实现这两个请求,可以维护一个并查集。为了进一步优化并查集,可以采用路径压缩的办法。
每次加入一个person,就在并查集中新增一个连通块。每次加入一条边,就把相关的两个人所在的连通块合并。query_circle等价于两个id的根节点是否一样。query_block_sum等价于并查集中根节点的个数。
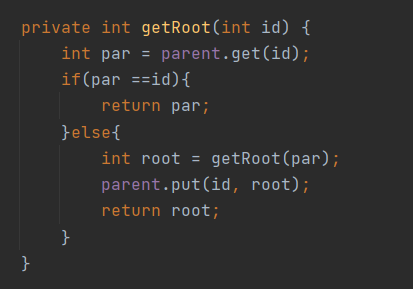
仅仅使用路径压缩的并查集,在极端的情况下,有可能导致太长的函数调用栈。这带来了爆栈的隐患。然而经过我的测试,即使是5000层的树,也不会爆栈。如果用循环代替递归,也需要自己维护一个栈,所需的空间复杂度没有降低。java虚拟机规范允许虚拟机栈的大小固定不变或者动态扩展,所以只要内存足够,往往就能避免爆栈。还有另外一种解决办法,每次把两个节点所在连通分量合并时,总是把较矮的树挂在较高的树上,这样就能把极端情况下的空间复杂度降低为log(n),然而不仅会让程序更加复杂,而且会增大平均时间开销。考虑到本次作业仅仅限制了时间,所以我最终采用了最基本的路径压缩并查集。
为什么不维护按姓名排序的列表
当前compare_name的算法是比较两个人的Name;query_name_rank是逐个比较并计数。如果维护一个按姓名排序的列表,每次加入一个人就把它插入到合适的位置,这样能在一定程度上优化compare_name和query_name_rank。然而不这样做,有两点原因:
维护这样的列表未必是对compare_name和query_name_rank的更好实现。每次加人都要把新的person插入到合适的位置,对于连续表来说,要把后面的人向后移动,需要付出O(n)的开销。而且查询时也要付出O(n)的开销。然而对于query_name_rank,即使是逐个比对,也只需要O(n)的时间,而compare_name原本只需要常量时间。
采用按姓名排序的列表的数据结构,只不过省去了每次查询时对姓名的比较,然而却付出了比较O(n)次id的开销。如果查询的方法远远多于add_person,而且person的姓名特别长,这样做是有意义的。然而当前的Person姓名长度不超过10,而且平均情况下,查询方法的次数未必远远多于修改方法,所以使用这种数据结构不合适。
2.第二次作业
与第一次作业相比,第二次作业主要有两方面的改动:①person新增社交值属性,社交系统增加group和message的概念。②引入异常处理类。设计思路为在第一次作业的图的基础上,增加子图结构。每一个group对应图的一个子图,把人加到group里就是把节点加到子图里。
| 指令 | 规格的要求 | 对图的维护 | 算法或数据结构 | 时间复杂度 |
|---|---|---|---|---|
| add_person | 添加一个人 | 添加一个点 | map | O(1) |
| add_relation | 添加两个人的关系 | 添加一条带权边 | map | O(1) |
| query_value | 查询两个人的关系 | 查询某条边的权 | map | O(1) |
| compare_name | 比较两个人的名字 | O(1) | ||
| query_name_rank | 查询姓名排序 | O(n) | ||
| query_people_sum | 查询总人数 | 查询节点总数 | O(1) | |
| query_circle | 查询两个人能否直接或间接相连 | 查询两个节点是否连通 | 并查集 | O(1) |
| query_block_sum | 查询不能与前面的人相连的总人数 | 查询连通块的个数 | 并查集 | O(n) |
| add_group | 添加一个组 | 在图上增加一个子集合 | map | O(1) |
| add_to_group | 把人加入组中 | 把节点加入到子集合 | O(n) | |
| query_group_sum | 查询总组数 | 查询子集合的个数 | O(1) | |
| query_group_people_sum | 查询某组的总人数 | 查询某个子集合的节点数 | O(1) | |
| query_group_value_sum | 查询某组的总value数 | 维护group_value_sum | O(1) | |
| query_group_age_mean | 查询某组的平均年龄 | 记忆算法 | O(n) | |
| query_group_age_var | 查询某组的方差 | 记忆算法 | O(n) | |
| del_from_group | 从某组中删除一个人 | 从子集合中删去一个人 | O(n) | |
| add_message | 添加一个信息 | O(1) | ||
| send_message | 发送一个信息 | O(1)/O(n) | ||
| query_social_value | 查询某个人的社交值 | O(1) | ||
| query_received_messages | 查询收到的信息 | 返回message的列表 | O(1) |
与第一次作业类似,network里对group的存储,以及map里对person的存储也使用map。向组中添加一个人,就是添加一个ID-Person键值对,删除一个人,就是删除一个键值对。
维护中间变量算法与记忆算法
第二次作业时空复杂度较大的查询是query_group_value_sum和query_group_age_mean以及query_group_age_var。
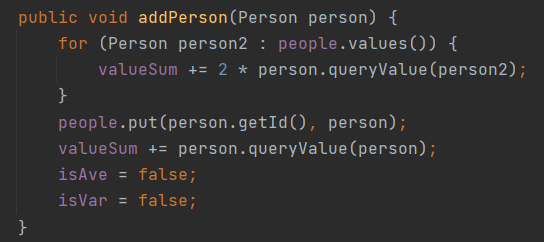
对于query_group_value_sum,如果按照规格叙述的方法来实现,就是O(n^2)复杂度,这容易导致超时。所以对于每个group,维护一个valueSum属性,当发生add_to_group或者del_from_group或者add_relation时,调整这个属性。这样,query_group_value_sum方法就只需常量时间复杂度了。
具体实现时,在network里维护一个map,记录每个人所在组。当add_relation时,如果这两个人位于同一个组,需要增加这个组的valueSum。
对于query_group_age_mean和query_group_age_var,采用记忆算法。当发生过这样的查询后,就把标记变量置位,下次再查询可以直接返回结果。
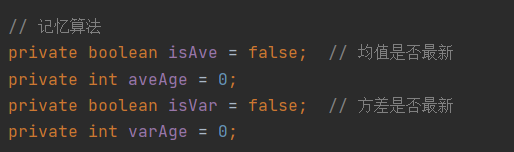
采用记忆算法而不是维护中间变量(年龄之和,年龄与均值差值的平方和)有两方面原因:
①维护age_var的代价比较大:当任何一个人发生变化(加入到组中,或者从组中删除)时,平均值也会随之变化,所以方差应当重新计算,原有的与均值的差值的平方和无法被利用。
②即使不维护age_mean和age_var,每次对它们的计算也只是O(n)的时间复杂度。
记忆算法保证了对于每一个状态,平均值和方差最多被计算一次。如果维护age_mean和age_var两个变量的值,对于平均值来说,只不过是把计算量均摊到了其他的指令中(维护年龄之和),而对方差来说,会导致大量的无用计算(平均值发生变化后,原来的差值的平方和就毫无意义)。所以综合来看,对query_group_age_mean和query_group_age_var这两个查询来说,记忆算法优于维护中间变量的做法。
然而query_group_value_sum则不同。当发生person或relation的变化时,可以在原来的valueSum的基础上做加减法得到更新后的valueSum。原来的valueSum的值可以被继续利用,这是query_group_value_sum与query_group_age_mean、query_group_age_var的根本区别。
反过来,如果对query_group_value_sum也采用记忆算法,那么当仅仅发生一个person的变化时,(下次查询valueSum)就要重新计算。然而除了这个人之外的valueSum的值已经被计算过了,再计算就会做无用功。
注意到run接口里对于query_received_messages的检测只是检测message的个数。所以在Person里无需存储他收到的各个message,只需存储收到的message的个数(最大为4)即可。当发生query_received_messages时,新建一个列表,填充相同个数的null,然后返回。
异常类的设计
这次作业引入了异常类。不同的异常类功能较为统一:按格式输出本次异常出现的次数,以及当前id引发本异常的次数。所以可以把这个功能分离出来,建立一个新的计数类Counter。
计数器有两个属性allCount和countMap。allCount记录本类异常出现的总次数,countMap记录某个id引发本类异常的次数。
Counter作为每个异常类的类变量。当引发某个异常时,就调用它的add方法。输出时调用outPut方法。这两个方法都兼容一个和两个id的情况。outPut的字符串参数是代表本类异常的字符串。这样做的原因是不同异常类都符合固定的输出格式,都是“xxx-x, id-y”或者"xxx-x, id1-y, id2-z"
3.第三次作业
与第二次作业相比,message得到了更细的划分:red_envelope_message,notice_message,emoji_message;通过send_indirect_message,对图增加了查找两点之间最短路径的请求。数据结构与第二次作业一致,仍然是图。
| 指令 | 规格的要求 | 对图的维护 | 算法或数据结构 | 时间复杂度 |
|---|---|---|---|---|
| add_person | 添加一个人 | 添加一个点 | map | O(1) |
| add_relation | 添加两个人的关系 | 添加一条带权边 | map | O(1) |
| query_value | 查询两个人的关系 | 查询某条边的权 | map | O(1) |
| compare_name | 比较两个人的名字 | O(1) | ||
| query_name_rank | 查询姓名排序 | O(n) | ||
| query_people_sum | 查询总人数 | 查询节点总数 | O(1) | |
| query_circle | 查询两个人能否直接或间接相连 | 查询两个节点是否连通 | 并查集 | O(1) |
| query_block_sum | 查询不能与前面的人相连的总人数 | 查询连通块的个数 | 并查集 | O(n) |
| add_group | 添加一个组 | 在图上增加一个子集合 | map | O(1) |
| add_to_group | 把人加入组中 | 把节点加入到子集合 | O(n) | |
| query_group_sum | 查询总组数 | 查询子集合的个数 | O(1) | |
| query_group_people_sum | 查询某组的总人数 | 查询某个子集合的节点数 | O(1) | |
| query_group_value_sum | 查询某组的总value数 | 维护group_value_sum | O(1) | |
| query_group_age_mean | 查询某组的平均年龄 | 记忆算法 | O(n) | |
| query_group_age_var | 查询某组的方差 | 记忆算法 | O(n) | |
| del_from_group | 从某组中删除一个人 | 从子集合中删去一个人 | O(n) | |
| add_message | 添加一个信息 | O(1) | ||
| send_message | 发送一个信息 | O(1)/O(n) | ||
| query_social_value | 查询某个人的社交值 | O(1) | ||
| query_received_messages | 查询收到的信息 | 返回message的列表 | O(1) | |
| add_red_envelope_message | 添加红包消息 | O(1) | ||
| add_notice_message | 添加会话消息 | O(1) | ||
| add_emoji_message | 添加表情包消息 | O(1) | ||
| store_emoji_id | 存储表情包id | O(1) | ||
| query_popularity | 查询表情包出现次数 | O(1) | ||
| delete_cold_emoji | 删除冷门表情包 | O(n) | ||
| query_money | 查询人的钱数 | O(1) | ||
| send_indirect_message | 发送间接消息 | 求两点之间的最短路径 | Dijkstra | O(nlog(n)) |
新增message子类
新增的三类message,不仅其实际意义可以看做原有message的三个细分种类,而且它们也兼容原有message的规格。所以把它们作为message的子类来实现就顺理成章了。以EmojiMessage为例,这个类只需在原有message的基础上增加一个emojiId属性。所以把这三个类实现为message的子类,不仅能很好的满足规格要求,而且比较简便。
表情包
需要记录每种表情包的热度,并提供查询和删除的方法。所以采用map实现。以<emojid_id, popularity>为键值对。当发送表情包消息时,把对应的表情包id的热度自增。删除冷门表情包时,采用迭代器的方案实现。
会话消息
保证socialValue和会话的长度相等后,这个消息与普通的message就一样了。
红包消息
发送这类消息时,要维护相关人员的钱数。注意计算方法要与规格一致,防止整除时出现差异。
最短路径
本次作业通过send_indirect_message提出查询最短路径的需求。如果采用最平凡的深度优先搜索的方法,很可能会超时,所以我采用经典的 Dijkstra方法来优化。 还可以采用Bellman-Ford等算法,但Dijkstra已经能够满足需求。注意剪枝:当已经寻找到初始节点到目标节点的最短路径后,可以直接返回,不用再继续寻找。实现Dijkstra时要用到java的类库PriorityQueue,提供下一个可以找到最短路径的节点。
我曾经想过另一种做法:在图的建立过程中,维护各个点之间的最短路径。然而实现起来比较困难,而且每次加边,任何两个顶点之间的最短路径都有可能变化,所以这种“不打自招”的做法可能反而会有更大的时空复杂度。
另外,即使是深度优先搜索(某个点v_start到v_end的最短路径,等于v_start的各个邻接点到v_end的最短路径与v_start到它的距离之和的最小值),也可以采用记忆算法大大降低时空复杂度:找到某个节点到目标节点的最短路径后,把这个路径的长度保存下来,下次到这里时不需要重新计算,这里说的“中间节点到v_end的最短路径”并不是实际上的最短路径,但不影响最终结果)。
本次作业中每条指令最多增加一个节点或一条边。所以边的数量和节点的数量都小于等于指令条数n。所以Dijkstra在本次作业中的复杂度是O(nlog(n))。实际时间则会更低。Dijkstra算法体现了动态规划的思想,而且它避免了一般的动态规划算法只能得到最终结果的不足,Dijkstra算法不仅能求出最短路径的长度,而且可以给出最短路径的细节:在v_start到任意一点的最短路径上,终点的前驱节点这个信息得到了保留。以此回溯,即可得到最短路径。
query_received_messages的优化
首先,由于需要记录各个message的顺序,所以用list作为容器。按照规格,每次需要把第新加入的message放在list的最前面,然后把其他的message后移。这样会带来不必要的开销,由于list是线性表,所以每次移动其他message要花费O(n)的时间(如果不考虑list这个容器本身的优化)。
改进方法有两种:①保证list的最大长度为4,这样,如果把不超过4个message的移动看做原子操作,那么每次加入message可以看做常量时间复杂度。②每次向list的最后加入新的message,只需要常量时间复杂度。调用query_received_messages方法时,按照从后往前的顺序,返回一个容量不超过4的新的list。
注意如果采用方法①,从安全的角度考虑,每次不应当直接返回list,而应当返回list的克隆。
方法①比方法②实现起来更麻烦,但空间复杂度更小。由于本次作业没有要求空间复杂度,所以我选择了方法②。
二、基于JML规格来设计测试的方法和策略
功能测试
完善的JML规格应当能够提供一个方法或一个类在程序运行的全部过程中遇到的不同情况的处理方法。因为程序符合JML规格等价于程序功能正确,所以对程序功能的测试就是要测试程序是否符合JML规格。
不同的程序调用流程、JML里不同的情况,形成了程序运行的一种树形结构。测试集应当能够填充这个树形结构,尤其要注意特殊情况的处理。
基本功能测试
构造三类图:随机图、完全图、稀疏图。输入ap、ar等指令后,进行各种查询,并且在构造图的过程中,也进行各种查询。
对于后两次作业,group分为①随机组成group、②所有人在一个group里、③每人一个group。发送随机信息,之后检查人员(信息发送者、信息接收者、无关者)的socialValue的变化是否正确。
对于第三次作业,除了对三类新增message的功能测试外,主要测试send_indirect_message是否正确:①两个人直接相连,最短路径是直接边。②两个人直接相连,最短路径是不是直接边。③两个人间接相连。④两个人不相连。
注意一种特殊情况:一个message被发送后,它的id能够再次被使用。
异常测试
产生各种异常,检测异常类能否正常工作。这包括:①检查每个方法是否能在应当报出异常时报出异常。②检查每个方法是否能在不应当报出异常的情况下不报出异常。③检查每个方法报出的异常种类是否正确。④报一种异常若干次,检测计数是否正确。⑤相同id报同一个异常若干次,检测计数是否正确。⑥相等id报异常,检测是否会重复计数。⑦检测异常输出时能否符合id的顺序。
性能测试
即使程序符合了JML,算法的性能也未必达标。所以要对容易超时的指令进行性能测试。
query_circle、query_block_sum 对于稠密图中相距较远的两个点,这两个指令的时空复杂度较高,所以构造近似完全图进行测试。
query_group_value_sum、query_group_age_var、query_group_age_mean 对于稠密图时间复杂度较高。构造完全图和近似完全图进行测试。
send_indirect_message 对于稠密图时间复杂度较高,构造完全图和近似完全图进行测试。
三、总结分析容器选择和使用的经验
本次作业中涉及到的容器主要是list和map。list对于按照下标的随机查找有着常量时间复杂度,然而对于按照key的查找,则必须逐个比较,时间复杂度为O(n)。map对于按照key的查找,平均时间复杂度是O(1)。除非是TreeMap,否则无法保存key的顺序。
| 需求 | 是否需要按key查找 | 是否需要顺序 | 选择的容器 |
|---|---|---|---|
| Person的acquaintance | √ | HashMap | |
| Person的messages | √ | ArrayList | |
| Group的people | √ | HashMap | |
| Network的people | √ | HashMap | |
| Network的groups | √ | HashMap | |
| Network的messages | √ | HashMap | |
| 并查集需要的父节点 | √ | HashMap | |
| Network的人-组关系 | √ | HashMap | |
| Network的表情包热度 | √ | HashMap |
另外,Dijkstra算法中需要用一个容器来存储候选边,每次需要提供最短的路径,这可以用java的PriorityQueue。向优先队列中加入元素或者从中取出第一个元素的时间复杂度都是log(n)。
总之,不同类型的容器对应不同类型的数据结构,它们有着不同的功能和复杂度。功能更强的容器,往往也有着更大的复杂度。比如TreeMap就比HashMap复杂度高。所以对于一个问题,不应当按照功能最强为标准选择容器,而应当选择最合适的容器。如果一个容器的功能与一个算法对容器的需求恰好一致,那么它往往是最合适的容器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号