
Logstash 篇之入门与运行机制
1、Logstash是一个数据收集引擎,相当于是ETL工具。截图来源慕课,尊重版本从你我做起。
Logstash分为三个阶段,第一个阶段Input是数据采集、第二个阶段是Filter数据解析和转换,第三个阶段是Output数据输出。
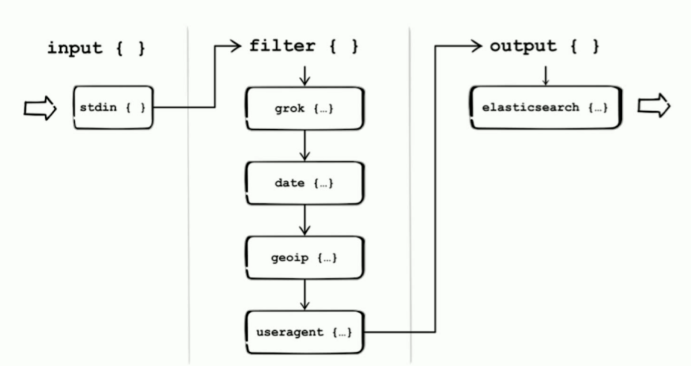
2、Logstash中的Pipeline概念。
1)、Pipeline是指Input-filter-output的三个阶段处理流程。
2)、队列管理。
3)、插件生命周期管理。
3、Logstash中的Logstash Event概念。
1)、内部流转的数据表现形式,原始数据从Input进入之后,在内部流转的时候不是原始的数据,而是Logstash Event数据。Logstash Event就是一个Java Object,对外暴漏去修改或者获取内部字段的api
2)、原始数据在input被转换为Event,在output event被转换为目标格式数据。
3)、在配置文件中可以对Event中的属性进行增删改查。
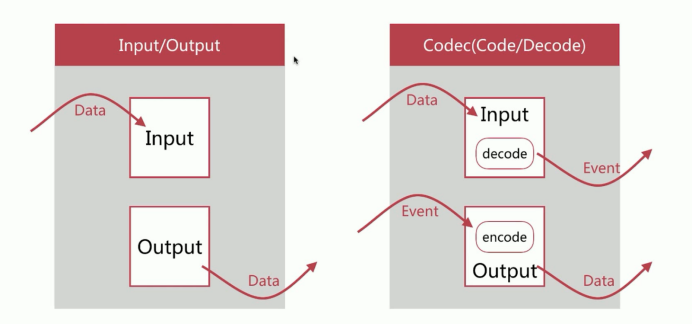
关于数据流转,数据由Input进入之后,从Output输出。Codec(Code、Decode)将原始数据Data转换为Logstash Event,当数据输出的时候,Codec将Logstash Event转换为目标数据源需要的类型Data。

4、Logstash的安装,将包上传到服务器进行解压缩即可,如下所示:
1 tar -zxvf logstash-6.7.1.tar.gz -C /usr/local/soft/
Logstash的简单案例,如下所示:
1 # 输入,stdin是标准输入,按照每一行切分数据 2 input { 3 stdin { 4 codec => line 5 } 6 } 7 8 # 过滤为空 9 filter {} 10 11 # 输出,stdout标准输出,将输出转换为json格式 12 output { 13 stdout { 14 codec => json 15 } 16 }
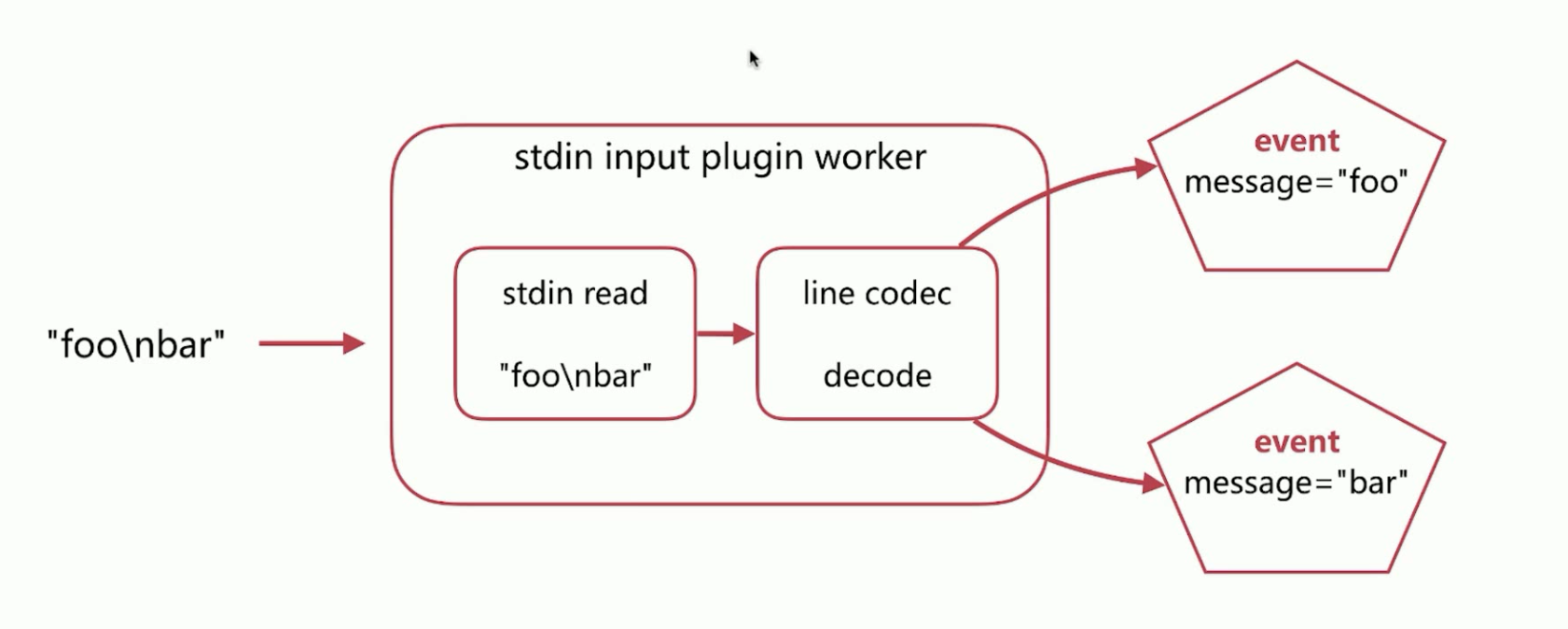
以每行进行切分数据,不过滤,然后输出为json格式的输入(Codec- Input Decoding)转换流程,如下所示:
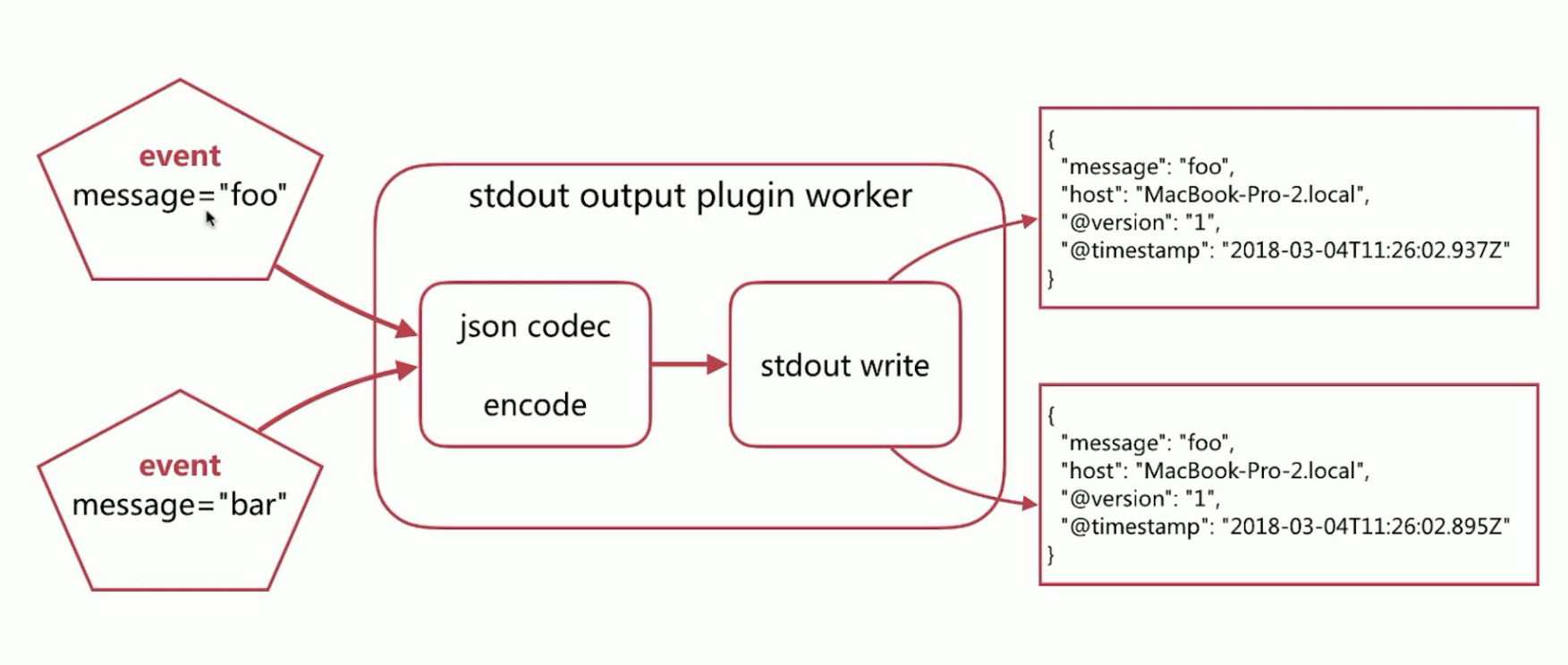
当输入之后,要进行输出(Codec- Output Encoding),如下所示:
演示效果,如下所示:
1 [elsearch@k8s-master logstash-6.7.1]$ echo "foo 2 > bar 3 > " | bin/logstash -f config/line-to-json.conf 4 Sending Logstash logs to /usr/local/soft/logstash-6.7.1/logs which is now configured via log4j2.properties 5 [2021-01-30T19:11:13,330][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/usr/local/soft/logstash-6.7.1/data/queue"} 6 [2021-01-30T19:11:13,357][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/local/soft/logstash-6.7.1/data/dead_letter_queue"} 7 [2021-01-30T19:11:14,189][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified 8 [2021-01-30T19:11:14,258][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.7.1"} 9 [2021-01-30T19:11:14,396][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"e449e4d8-b26e-49fa-b12d-3d452b50aac4", :path=>"/usr/local/soft/logstash-6.7.1/data/uuid"} 10 [2021-01-30T19:11:24,816][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50} 11 [2021-01-30T19:11:24,943][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x6185f2c6 run>"} 12 [2021-01-30T19:11:25,080][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]} 13 {"@version":"1","host":"k8s-master","message":"foo","@timestamp":"2021-01-30T11:11:25.063Z"}{"@version":"1","host":"k8s-master","message":"bar","@timestamp":"2021-01-30T11:11:25.102Z"}{"@version":"1","host":"k8s-master","message":"","@timestamp":"2021-01-30T11:11:25.102Z"}[2021-01-30T19:11:25,394][INFO ][logstash.pipeline ] Pipeline has terminated {:pipeline_id=>"main", :thread=>"#<Thread:0x6185f2c6 run>"} 14 [2021-01-30T19:11:25,516][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600} 15 [elsearch@k8s-master logstash-6.7.1]$
5、Logstash的架构简介,如下所示:
Logstash的输入可以有多个的,数据流入之后,经过Codec之后,数据流入Queue,而Queue负责将流入的数据分发到Pipeline(是指Input-filter-output的三个阶段处理流程)中,而Batcher的作用是批量的从Queue中取数据,而Batcher有时间和数据量两种触发条件。
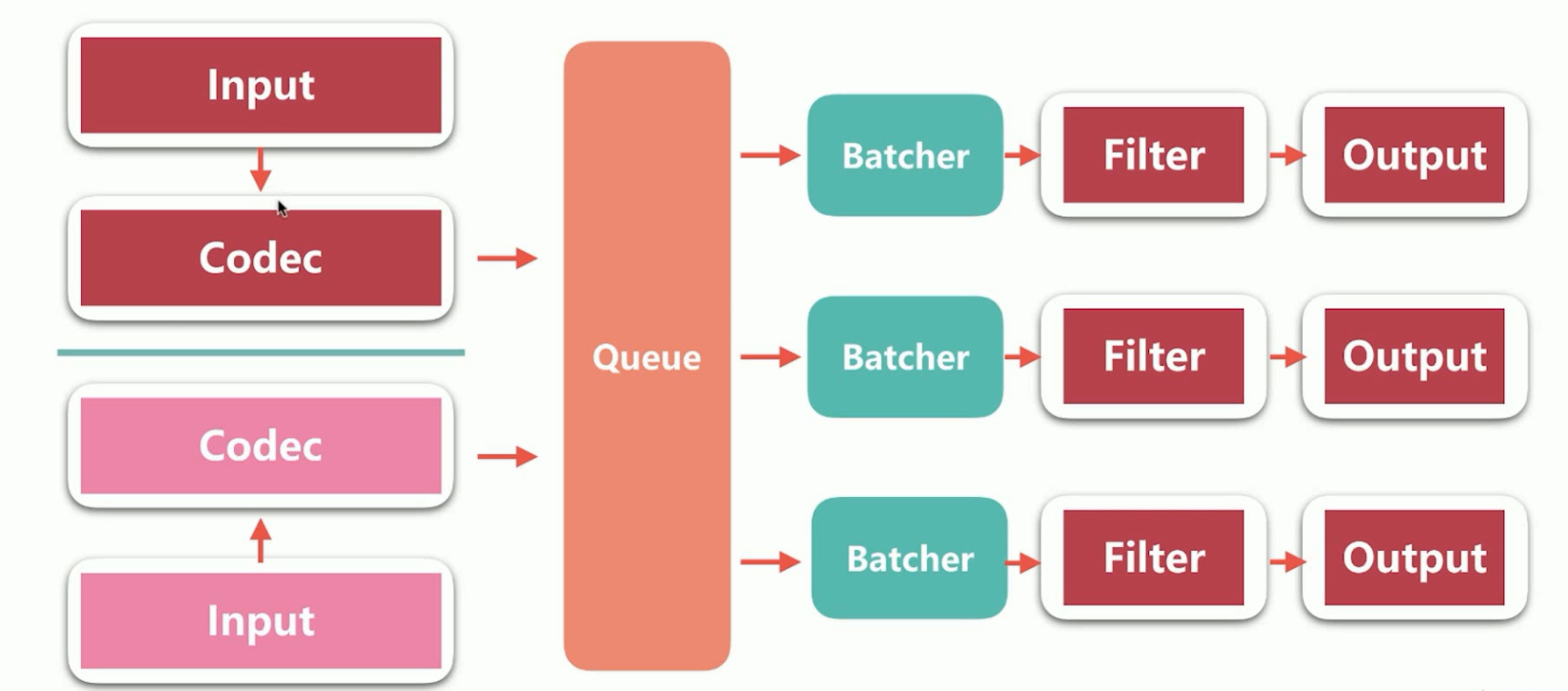
6、Logstash中Queue的分类。
1)、In Memory,无法处理进程Crash,机器宕机等情况,会导致数据丢失。
2)、Persistent Queue In Disk,可处理进程Crash等情况,保证数据不丢失。保证数据至少消费一次。充当缓冲区,可以替代Kafka等消息队列的作用。
3)、Persistent Queue的基本配置,第一个参数queue.type:persisted,但是这个参数默认是memory。第二个参数是queue.max_bytes:4gb,队列存储最大数据量,默认是1gb。
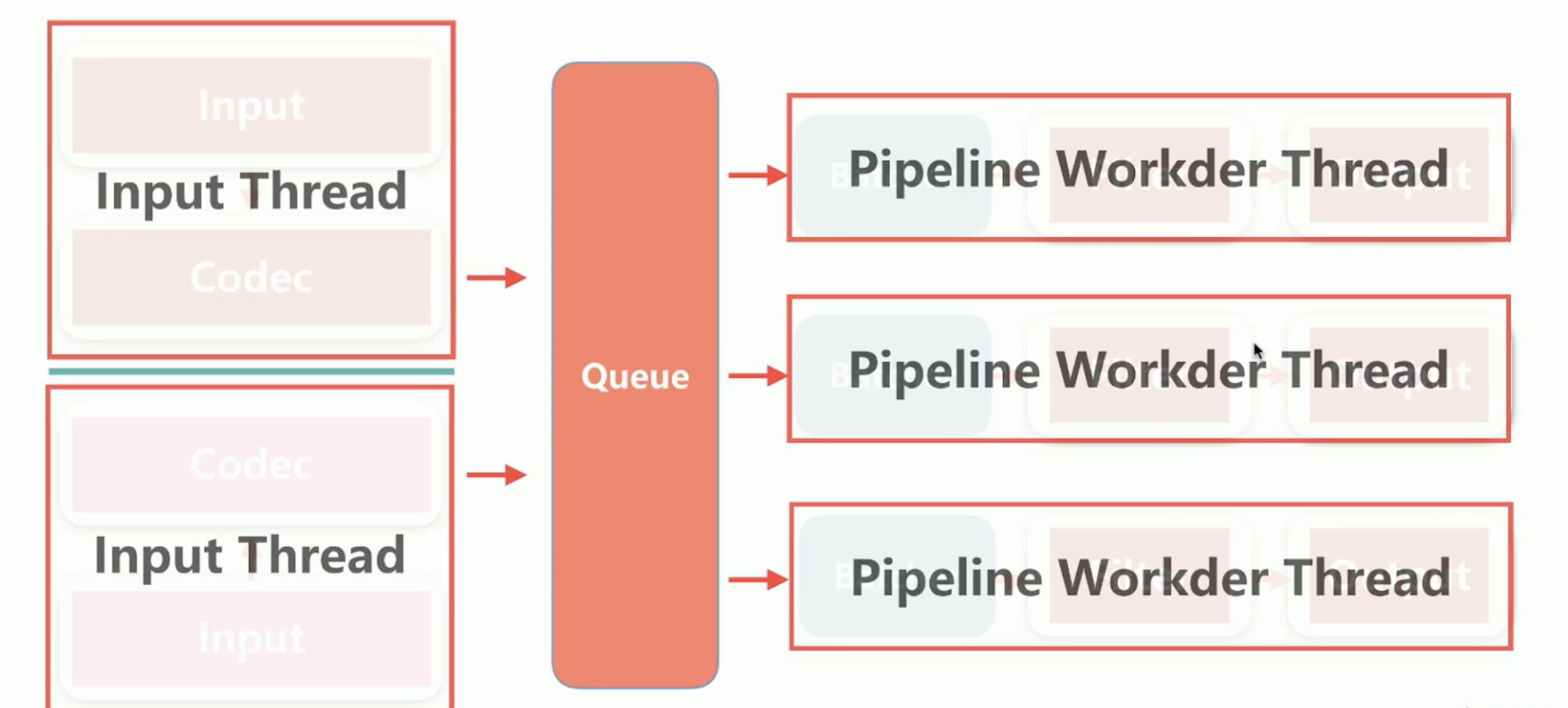
7、Logstash中的线程,包含Input Thread输入线程,Pipeline Workder Thread,每个Pipeline会在自己独立的线程中的,对Logtash线程调优,一般调整的就是Pipeline的线程个数。
1)、pipeline.workers | -w,pipeline线程数,即filter_output的处理线程数,默认是cpu核数。
2)、pipeline.batch.size | -b,Batcher一次批量获取的待处理文档数,默认是125,可以根据输出进行调整,越大会占用越多的heap空间,可以通过jvm.options调整。
3)、pipeline.batch.delay | -u,Batch等待的时长,单位为ms。
8、logstash的配置文件。
1)、logstash设置相关的配置文件,在config文件夹中。
a、logstash.yml,这个是logstash相关的配置,比如node.name(节点名称)、path.data(持久化存储数据的文件夹,默认是logstash home目录下的data)、pipeline.works(设定pipeline的线程数,优化的常用项)、pipeline.batch.size/delay(设定批量处理数据的数目和延迟)、queue.type(设定队列类型,默认是memory)、queue.max_bytes(设定队列总容量,默认是1GB)、path.log(设定pipeline日志文件的目录)、path.config(设定pipeline配置文件的目录)等等,这其中的配置可以被命令行参数中的相关参数覆盖。
b、jvm.options修改jvm的相关参数,比如修改heap size等等。
2)、pipeline配置文件,定义数据处理流程的文件,以.conf结尾。
9、logstash命令行配置项。
1)、--node.name,指定节点名称。
2)、-f --path.config,pipeline路径,可以是文件或者文件夹。
3)、--path.settings,logstash配置文件夹路径,其中要包含logstash.yml。
4)、-e --config.string,指明pipeline内容,多用于测试使用。
5)、-w --pipeline.workers,设定pipeline的线程数,优化的常用项。
6)、-b --pipeline.batch.szie,设定批量处理数据的数目和延迟。
7)、--path.data,指定logstash的数据目录。
8)、--debug,打开调试日志。
9)、-t config.test_and_exit,打开测试,检查Logstash加载进来的pipeline是否有错,有错就报错。
10、logstash配置方式建议。
1)、线上环境推荐采用配置文件的方式来设定Logstash的相关配置,这样可以减少犯错的机会,而且文件便于进行版本化管理。
2)、命令行形式多用来进行快速的配置测试、验证、检查等。
11、logstash多实例运行方式,在一台机器运行多个logstash的实例。
1 bin/logstash --path.settings instance1 2 bin/logstash --path.settings instance2
不同的instance实例中修改logstash.yml,自定义path.path,确保其不相同即可。
12、pipeline的配置,用于配置input、filter、output的插件,框架是input{}、filter{}、output{}。pipeline配置语法,主要有如下的数据类型,如下所示:
1 a、布尔类型Boolean,例如isFailed => true。 2 b、数值类型Number,例如port => 33。 3 c、字符串类型String,例如name => "hello world"。 4 d、数组Array或者List,例如,users => [{id => 1,name => bob},{id => 2, name => jane}]。 5 e、哈希类型hash,match => { 6 "field1" => "value1" 7 "field2" => "value2" 8 } 9 f、注释,使用井号#。
在配置中可以引用Logstash Event的属性字段,主要有如下两种方式。
1)、第一种,是直接引用字段值Field Reference,使用[]中括号即可,嵌套字段写多层[]中括号即可。
2)、第二种,是在字符串以sprintf方式引用,使用%{}来实现。
3)、支持条件判断语法,从而扩展了配置的多样性,语法格式if 表达式 else if 表达式。
1 表达式主要包含如下的操作符。 2 1)、比较运算符,==、!=、<、>、<=、>=。 3 2)、正则是否匹配,=~、!~。 4 3)、包含字符串或者数据,in、not in。 5 4)、布尔操作符,and、or、nand、xor、!。 6 5)、分组操作符,()。
13、Input Plugin插件,input插件指定数据输入源,一个pipeline可以有多个Input插件,这里主要使用这三个input插件,stdin、file、kafka。
1)、Input插件stdin,是最简单的输入,从标准输入读取数据,没有特殊配置,都是使用的通用配置,这些通用配置在所有的input输入插件都可以使用,通用配置为。
a、codec类型为codec。Codec(Code、Decode)将原始数据Data转换为Logstash Event,当数据输出的时候,Codec将Logstash Event转换为目标数据源需要的类型Data。
b、type类型为string,自定义事件的类型,可用于后续判断。
c、tags类型为array,自定义该事件的tag,可用于后续判断。
d、add_field类型为hash,为该事件添加字段。
案例,如下所示:
1 [elsearch@master logstash-6.7.0]$ cat config/input-stdin.conf 2 # 输入, 3 input { 4 stdin { 5 codec => "plain" 6 tags => ["input stdin"] 7 type => "stdin" 8 add_field => {"key" => "value"} 9 } 10 } 11 12 # 过滤为空 13 filter {} 14 15 # 输出,stdout标准输出,将输出转换为json格式 16 output { 17 stdout { 18 codec => "rubydebug" 19 } 20 } 21 [elsearch@master logstash-6.7.0]$
运行效果,如下所示:
1 [elsearch@master logstash-6.7.0]$ echo "test" | ./bin/logstash -f config/input-stdin.conf 2 Sending Logstash logs to /usr/local/soft/logstash-6.7.0/logs which is now configured via log4j2.properties 3 [2021-02-07T22:52:14,813][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified 4 [2021-02-07T22:52:14,842][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.7.0"} 5 [2021-02-07T22:52:25,039][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50} 6 [2021-02-07T22:52:25,192][INFO ][logstash.inputs.stdin ] Automatically switching from plain to line codec {:plugin=>"stdin"} 7 [2021-02-07T22:52:25,277][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x4755c349 run>"} 8 [2021-02-07T22:52:25,391][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]} 9 /usr/local/soft/logstash-6.7.0/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated 10 { 11 "key" => "value", 12 "message" => "test", 13 "host" => "master", 14 "@timestamp" => 2021-02-07T14:52:25.350Z, 15 "@version" => "1", 16 "tags" => [ 17 [0] "input stdin" 18 ], 19 "type" => "stdin" 20 } 21 [2021-02-07T22:52:26,262][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600} 22 [2021-02-07T22:52:26,275][INFO ][logstash.pipeline ] Pipeline has terminated {:pipeline_id=>"main", :thread=>"#<Thread:0x4755c349 run>"} 23 [elsearch@master logstash-6.7.0]$
14、Input Plugin输入插件file,从文件读取数据,如常见的日志文件。文件读取通常要解决几个问题。
1)、文件内容如何只被读取一次,即重启logstash的时候,从上次读取的位置继续。解决方法是使用sincedb方案解决这个问题。
2)、如何即时读取到文件的新内容。解决方法是定时检查文件是否有更新。
3)、如何发现新文件并进行读取?解决方法是可以定时检查新文件。
4)、如果文档发生了归档操作,是否影响当前的内容读取?答案是不影响,被归档的文件内容可以继续被读取。
5)、基于Filewatch的ruby库实现的。
15、Input Plugin输入插件file,读取文件规则的关键配置。
1)、path类型为数组,指明读取的文件路径,基于glob匹配语法。例如ppath => ["/var/log/**/*.log","var/log/message"]。
2)、exclue类型为数组排除不想监听的文件规则,基于glob匹配语法。例如exclude => "*.gz"。
3)、sincedb_path类型为字符串,记录sincedb文件路径。
4)、start_position类型为字符串,beginning or end,是否从头读取文件。
5)、stat_interval类型为数值,单位秒,定时检查文件是否有更新,默认是1秒。
6)、discver_interval类型为数值,单位秒,定时检查是否有新文件待读取,默认15秒。
7)、ignore_older类型为数值,单位秒,扫描文件列表时候,如果该文件上次更改时间超过设定的时长,则不做处理,但依然会监控是否有新内容,默认是关闭。
8)、close_ollder类型为数值,单位秒,如果监听的文件在超过该设定时间内没有新内容,会被关闭文件句柄,释放资源,但依然会控制是否有新内容,默认3600秒,即一个小时。
16、Input Plugin输入插件的glob匹配语法,主要包含如下几种匹配符。
1)、*代表匹配任意字符,但是不匹配以.点开头的隐藏文件,匹配这类文件的时候要使用.*来进行匹配。例如,"/var/log/*.log",代表匹配/var/log目录下以.log结尾的文件。
2)、**代表递归匹配子目录。例如,"/var/log/**/*.log",代表匹配/var/log所有子目录下以.log结尾的文件。
3)、?代表匹配单一字符。
4)、[]代表匹配多个字符,比如[a-z]、[^a-z]。
5)、{}匹配多个单词,比如{foo,bar,hello}。例如,"/var/log/{app1,app2,app3}/*.log",代表了匹配/var/log目录下app1、app2、app3目录中以.log结尾的文件。
6)、\转义符号。
17、Input Plugin组件的Kafka,kafa是最流行的消息队列,也是Elasticsearch架构中常用的,使用相对简单。
1 input { 2 kafka { 3 zk_connect => "kafka:2181" 4 group_id => "logstash_group" 5 topic_id => "apache_logs_topic" 6 consumer_threads => 16 7 } 8 }
18、Codec Plugin插件,Codec Plugin作用于input和output plugin,负责将数据在原始与Logstash Event之间进行转换,常见的codec有,如下所示:
1)、plain读取原始内容。
2)、dots将内容简化为点进行输出。
3)、rubydebug将logstahs Events按照ruby格式输出,方便调试。
4)、line处理带有换行符的内容。
5)、json处理json格式的内容。
6)、multiline处理多行数据的内容。当一个Event的message由多行组成的时候,需要使用该codec,常见的情况是堆栈日志信息的处理。主要设置参数如下:
a、pattern设置行匹配的正则表达式,可以使用grok。
b、what previous|next,如果匹配成功,那么匹配行是归属上一个事件还是下一个事件。
c、negate true or flase是否对pattern的结果取反,默认是false。
1 [elsearch@master logstash-6.7.0]$ ./bin/logstash -e "input{stdin{codec => line}} output{stdout{codec => rubydebug}}" 2 [elsearch@master logstash-6.7.0]$ ./bin/logstash -e "input{stdin{codec => line}} output{stdout{codec => dots}}" 3 [elsearch@master logstash-6.7.0]$ ./bin/logstash -e "input{stdin{codec => json}} output{stdout{codec => rubydebug}}"
19、Filter Plugin组件,Filter是Logstash功能强大的主要原因,它可以对Logstash Event进行丰富的处理,比如数据解析,删除字段,类型转换等等,常见的有如下几个:
1)、date日期解析。将日期字符串解析为日期类型,然后替换@timestamp字段或者指定的其他字段。
a、match,类型为数组,用于指定日期匹配的格式,可以一次指定多种日期格式,例如match => ["logdate", "MMM dd yyyy HH:mm:ss", "MMM d yyyy HH:mm:ss", "ISO8601"]。
b、target,类型为字符串,用于指定赋值的字段名称,默认是@timestamp。
c、timezone,类型为字符串,用于指定时区。
2)、grok正则匹配解析。Grok语法如下所示:
a、%{SYNTAX : SEMANTIC},其中SYNTAX为grok pattern的名称,SEMANTIC为赋值字段名称。
b、%{NUMBER : duration}可以匹配数值类型,但是grok匹配出的内容都是字符串类型,可以通过在最后指定为int或者float来强制转换类型,%{NUMBER : duration : float}等等。
c、Filter Plugin组件的grok调试建议,如果是正则表达式可以使用https://www.debuggex.com/、https://regexr.com/。
d、如果是grok调试,可以使用http://grokdebug.herokuapp.com/,进行调试操作。
3)、dissect分割符解析。Filter Plugin组件之dissect,基于分割符原理解析数据,解决grok解析的时候消耗过多cpu资源的问题。
a、dissect的应用有一定的局限性,主要适用于每行格式相似且分割符明确简单的场景。
b、dissect语法比较简单,有一系列字段field和分割符delimiter组成,%{}中括号之间是字段、%{}和%{}之间是分割符。
c、dissect可以自动处理空的匹配值。
d、dissect分割后的字段值都是字符串,可以使用convert_datatype属性进行类型转换。
e、语法规则,如果不写名称,即%{},表明忽略该值。+加号,代表该匹配值追加到ts字段下。/斜线后面的数字代表了拼接的次序。%{?}代表了忽略匹配值,但是赋予字段名,用于后续匹配用、%{&}代表了匹配值赋予key1的匹配值。
4)、mutate对字段作处理,比如重命名、删除、替换等等。Filter Plugin组件之mutate,使用最频繁的操作,可以对字段进行各种操作,比如重命名,删除,替换,更新等操作,主要操作如下:
a、convert类型转换。实现字段类型的转换,类型为hash,仅支持转换为integer、float、string和boolean。
b、gsub字符串替换。对字段内容进行替换,类型为数组,每3项为一个替换配置。
c、split/join/merge字符串切割、数组合并为字符串、数组合并为数组。split可以将字符串切割为数组,join将数组拼接为字符串,merge是将两个数组合并为一个数组,字符串会被转为1个元素的数组进行操作。
d、rename字段重命名。
e、update/replace字段内容更新或者替换。更新字段内容,区别在于Update只在字段存在的时候生效,而replace在字段不存在的时候会执行新增字段的操作。
f、remove_field删除字段。
5)、json按照json解析字段内容到指定字段中。Filter Plugin组件之json,将字段内容为json格式的数据进行解析。其中source指定要解析的字段名,target指定解析后的存储字段,默认和message同级别。
6)、geoip增强地理位置数据。Filter Plugin组件之geoip,常用的插件,根据ip地址提供对应的地域信息,比如经纬度、城市名等等,方便进行地理数据分析。
7)、ruby利用ruby代码来动态修改logstash Event。Filter Plugin组件之ruby最灵活的插件,可以以ruby语言来随心所欲的修改Logstash Event对象。
20、Filter Plugin组件之Output,负责将Logstash Event输出,常见的插件如下,stdout、file、elasticsearch。
1)、输出到标准输出,多用于调试。
1 output{ 2 stdout { 3 codec => rubydebug 4 } 5 }
2)、输出到文件,实现将分散在多地的文件统一到一处的需求,比如将所有web机器的web日志收集到1个文件中,从而方便查阅信息。默认输出json格式的数据,通过format可以输出原始格式。
1 output{ 2 file { 3 path => "/var/log/web.log" 4 codec => line { format => "%{message}"} 5 } 6 }
3)、输出到elasticsearch,是最常用的插件,基于http协议实现。
1 output{ 2 elasticsearch{ 3 hosts => ["192.168.110.133:9200"],只写data和client node地址。 4 index => "nginx-%{+YYYY.MM.dd}",注意,索引可以按照时间写入。 5 template => "./nginx_template.json" 6 template_name => "nginx_template" 7 template_overwrite => true 8 } 9 }
21、Logstash的监控运维的api,logstash提供了丰富的api来查看logstash的当前状态,如下所示:
1)、http://localhost:9600
2)、http://localhost:9600/_node
3)、http://localhost:9600/_node/stats
4)、http://localhost:9600/_node/hot_threads

 浙公网安备 33010602011771号
浙公网安备 33010602011771号