
Prometheus告警常用配置
引言:
Prometheus是一个按功能划分的凭条,指标的收集和存储与警报是分开的。警报管理功能是由Alertmanager的工具提供,该工具是监控体系中的独立组件。
在Prometheus上定义警报规则后,这些规则可以出发事件,然后传播到Alertmanager,Alertmanager会决定如何处理相应的警报。Alertmanager对警报进行去重、分组,然后路由到不同的接收器,如电子邮件、短信或SaaS服务(PagerDuty等)。我们将在Prometheus服务器上编写警报规则 [2] ,这些规则将使用我们收集的指标并在指定的阈值或标准上触发警报。我们还将看到如何为警报添加一些上下文。当指标达到阈值或标准时,会生成一个警报并将其推送到Alertmanager。与Prometheus一样,Alertmanager配置也是基于YAML的配置文件。
一、Alertmanager安装使用
下载地址:
https://prometheus.io/download/#alertmanager
解压并将以下两个文件复制到指定目录,如下
[root@bogon alertmanager]# cp alertmanager /usr/local/bin/ [root@bogon alertmanager]# cp amtool /usr/local/bin/ [root@bogon ~]# alternatives --version #查看版本 alternatives version 1.7.2 [root@bogon alertmanager]# ./alertmanager #启动Alertmanager
浏览器访问ip:9093即可查看到Alertmanager图形页面
二、Prometheus配置Alertmanager
修改prometheus.yml文件,添加lerting块。具体内容如下:(其中最后一行的alertmanager为ip地址,或可以解析到对应的Alertmanager的IP)
[root@bogon prometheus]# cat prometheus.yml |grep -A 5 alerting|grep -v ^# alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093 [root@bogon prometheus]#
配置监控好Alertmanager后,告警内容会发送给Alertmanager
三、Alertmanager服务发现
暂时没明白什么意思,后续清楚了再进行补充
四、监控Alertmanager
配置prometheus.yml文件
- job_name: 'alertmanager' static_configs: - targets: ['localhost:9093']
添加报警规则
在prometheus.yml的同级目录中,创建rules目录,在该新建目录下创建node_alerts.yml文件,内容如下:
rule_files: - "rules/*_rules.yml" - "rules/*_alerts.yml"
添加第一条警报规则,如果process_max_fds(点击Prometheus界面的targets里对应的Alertmanager查看metrics,随便挑一个值)大于80,则会触发警报
[root@bogon rules]# cat node_alerts.yml groups: - name: node_alerts rules: - alert: HighNodeCPU expr: process_max_fds >80 for: 60m labels: serverity: warning annotations: summary: High Node CPU for 1 hour console: You might want to check the Node Dashboard
解释:指定组名为nod_alerts,警报名称为HighNodeCPU(每个警报组中,警报名称必须唯一),触发警报的测试表达式在expr中,检查条件为该指标是否大于80(或者说是80%使用率),for为测试表达式必须为true的时间长度。其中annotations里的summary的标签用来描述警报,console用注释提供上下文,方便快速排错。
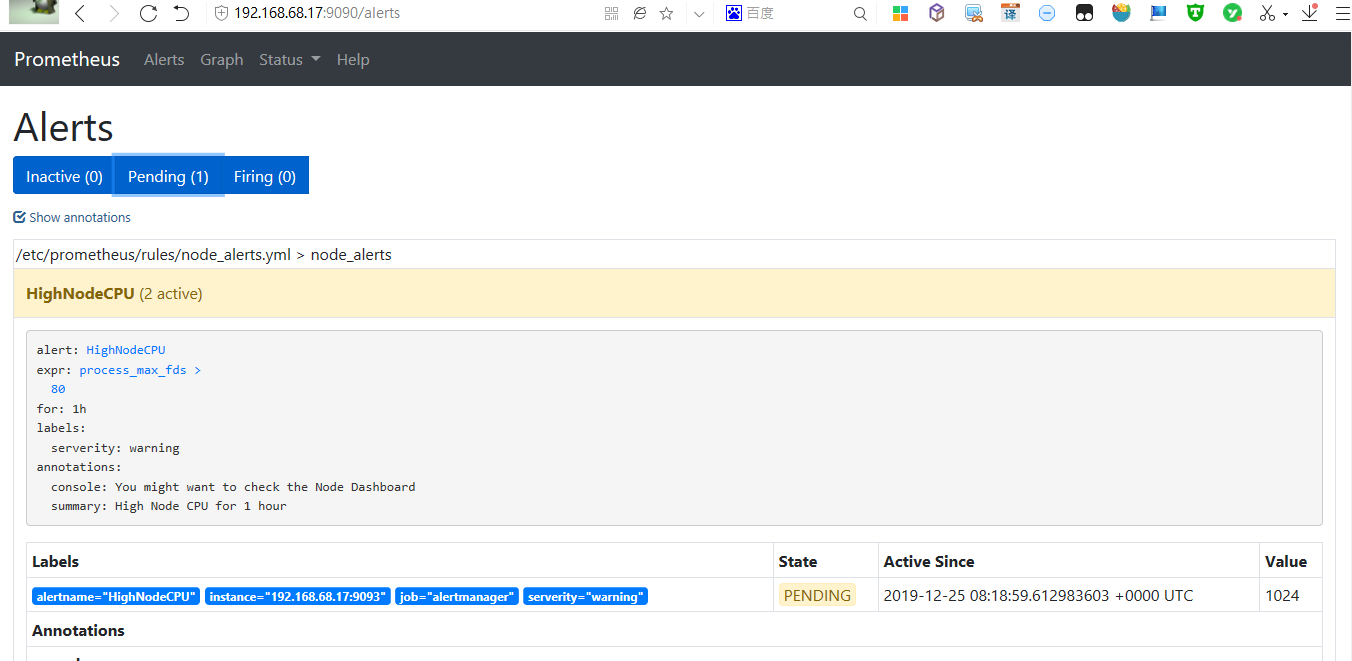
需要重启Prometheus,配置生效,可以在Prometheus里的alerts里看到。刚开始的时候应该是inactive状态,监测到满足大于80的条件后就立刻转为pending状态了,当大于80的状态满足持续1小时的时间后就会触发告警,发送邮件(邮件部分还需要做额外配置)
五、警报触发
Prometheus以一个固定时间间隔来评估所有规则,这个时间由evaluate_interval定义,我们将其设置为15秒。
警报有三中状态:Inactive 警报未激活。Pending:警报已满足测试表达式条件,但未达到for指定的持续时间。Firing:警报满足测试表达式条件,且持续时间达到了for指定的持续时间。
六、配置邮件告警
我是使用Outlook邮箱(微软邮箱)进行测试的,QQ邮箱没测试成功。后续我再进行改进,确定各部分代码的用途,具体代码如下:
[root@bogon alertmanager]# cat alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'smtp.office365.com:587' smtp_from: '请输入你的邮箱账号' smtp_auth_username: '请输入你的outlook邮箱账号' smtp_auth_password: '请输入你的密码' smtp_hello: 'office365.com' smtp_require_tls: true route: group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 5m receiver: default routes: - receiver: email group_wait: 10s receivers: - name: 'default' email_configs: - to: '请输入你的邮箱账号' send_resolved: true - name: 'email' email_configs: - to: '请输入你的邮箱账号' send_resolved: true
我重启了Prometheus和Alertmanager就收到邮件了。注意,需要满足触发邮件才会发送对应的告警邮件。邮件如下:
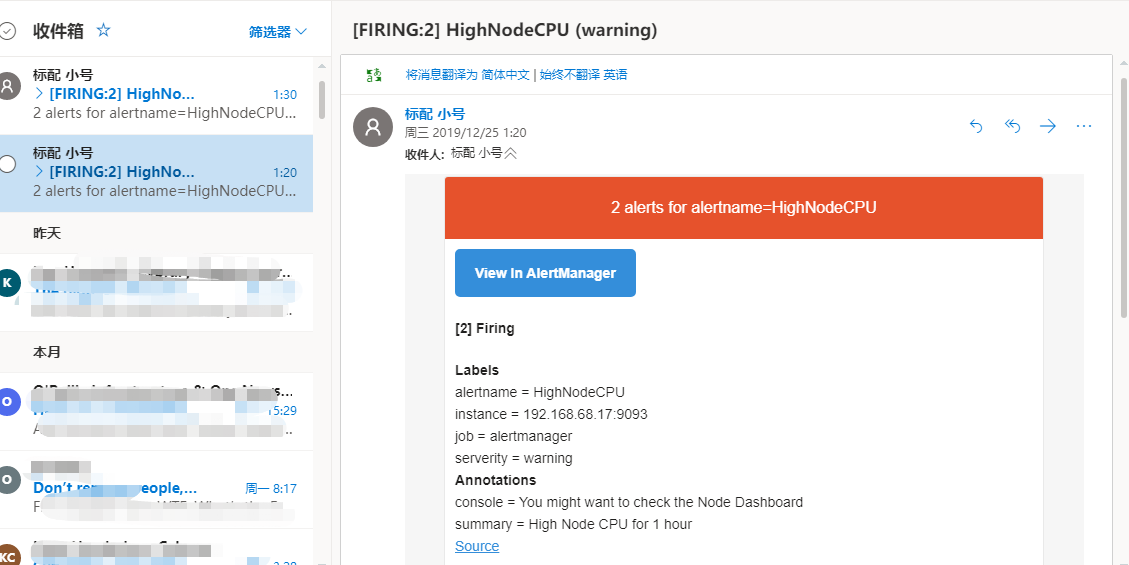
七、使用模板
使用模板的意思,简单一点来说,就相当于在规则里使用变量。这样做的好处在于,避免针对每一个监控对象重复编写内容类似的告警内容。
例如,我们可以在node_alerts.yml中,将annotations中的summary改为
Host {{$labels.instance}} of {{ $labels.job}} ,which process_max_fds is too many!
可以看到,我们在上面这条语句中使用了变量。
八、路由配置
告警进行路由,匹配对应的告警类型,发送告警给指定用户。
配置alertmanager.yml文件
route: group_bp: ['instance'] #进行告警汇总分类 group_wait: 30s group_interval: 5m repeat_interval: 3h receiver: email routes: #匹配告警等级,将告警发送给指定用户。当serverity为critical时发送给pager - match: serverity: critical receiver:pager - match_re: servity: ^(waring|critical)$ receiver: suppport_team receivers: - name: 'email' email_configs: - to: 'alerts@example.com' - name : 'support_team' email_configs: - to: 'support@example.com' -name: 'pager' email_configs - to: 'alert-pager@example.com'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号