
序列
1.内置序列类型概览
容器序列:list、tuple和collections.deque
序列:有序的排列,dict和set是容器但非序列(因为它们无序)
容器序列存放的是它们所包含的任意类型的对象的引用,能存放不同类型的数据(可嵌套使用)
扁平序列:str、bytes、bytearray(字节数组)、array.array
扁平序列存放的是值而不是引用,只能容纳一种类型,其实是一段连续的内存空间(不能嵌套使用)
可变序列:list、bytearray、array.array、collections.deque
不可变序列:tuple、str和bytes
2.列表推导和生成器表达式
Python会忽略代码里 [ ]、{ }和( )中的换行,因此如果有多行的列表、列表推导、生成器表达式、字典这一类的,可以忽略不太好看的续行符 \
列表推导是你推导多少给多少,一下子计算全部出来;生成器是你需要时再计算,需要多少给多少
生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,语法跟列表推导差不多,只不过把方括号换成圆括号而已。
3.元组不仅仅是不可变的列表
3.1元组拆包
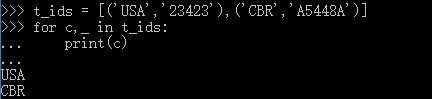
for循环可以分别提取元组中的元素,也叫做拆包,因为不想要元组中第二个元素,所以它赋值给“_”占位符
元组拆包可以应用到任何可迭代对象上,但要求被可迭代对象中的元素数量必须跟接受这些元素的元组的空档数一致,除非用*来表示忽略多余的元素

另一个用法是让一个函数用元组的形式返回多个值
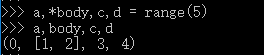
在Python中,函数用*args来获取不确定数量的参数算是一种经典写法了,这个概念被扩展到了平行赋值中:可以出现在赋值表达式的任意位置
3.2具名元组
collections.namedtuple是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类------这个带名字的类对调试程序有很大帮助
1 from collections import namedtuple 2 3 Student = namedtuple('Student','name id age')#学生有名字 id 班级 4 zhangSan = Student('zhangSan',2016112233,12) 5 print(zhangSan)

两个参数:一个是类名,另一个是类的各个字段的名字,后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串4
4.切片
L[start:end:step] step取负意味着反向取值
4.1为什么切片和区间会忽略最后一个元素:
(1)当只有最后一个位置信息时,可快速看出有几个元素,如range(3)和my_list[:3]都返回3个元素
(2)当起止位置信息都可见时,可快速计算出切片和区间的长度,(end-start)即可
(3)可用一个下标来把序列分割成不重叠的两部分,如l[:2]和l[2:]
4.2多维切片
要用a[m:n,k:l]的方式来得到二维切片,对象的特殊方法__getitem__和__setitem__需要以元组的形式来接收a[i,j]中的索引
Python内置的序列类型都是一维的,因此它们只支持单一的索引,成对的索引是没用的
4.3给切片赋值
如果把切片放在赋值语句的左边,或把它作为del操作的对象,就可以对序列进行嫁接、切除或就地修改操作,不需要重新组建序列
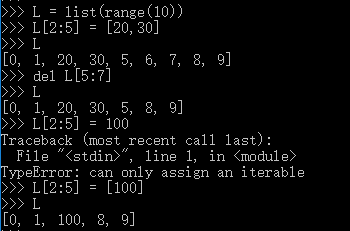
如果赋值的对象是一个切片,那么赋值语句的右侧必须时个可迭代对象。即便只有单独一个值,也要把它转换成可迭代的序列(如list)
5.对序列使用+和*
都不会修改原有的操作对象,而是构建一个全新的序列

6.序列的增量赋值(+=、*=)
+=背后的特殊方法是__iadd__(就地加法),但如果一个类没有实现这个方法的话,Python会退一步调用__add__
总体来讲,可变序列一般都实现了__iadd__方法,而不可变序列根本就不支持这个操作,会变成a=a+b,首先计算a+b得到一个新的对象,然后赋给a。

对不可变序列进行重复拼接操作效率会很低
7.用bisect(二等分)来管理已排序的序列
排序很耗时,因此在得到一个有序序列之后,我们最好能保持它的有序,bisect模块bisect和insort两个函数都利用二分查找算法来在有序序列中查找或插入元素
用bisect.bisect(haystack,needle)来搜索:在序列haystack里搜索needle的位置,该位置满足把needle插入这个位置之后,haystack还能保持升序

用bisect.insort(seq,item)插入新元素:把变量item插入到序列seq中,并能保持seq的升序顺序

8.当列表不是首选时
虽然列表即灵活又简单,但面对各类需求时,我们可能会有更好的选择
(1)数组
如果需要一个只包含数字的列表,那么array.array比list更高效。数组支持所有跟可变序列有关的操作,包括pop、insert、extend(extend函数用于在列表末尾一次性追加另一个序列中的多个值,用新列表扩展原来的列表)。另外数组还提供从文件读取和存入文件的更快的方法,如.frombytes和.tofile
创建数组需要一个类型码,表示应该存放怎样的数据类型
一个浮点型数组的创建,存入文件和从文件读取的过程:

数组排序:a = array.array(a.typecode,sorted(a))
(2)NumPy和SciPy
凭借NumPy和SciPy提供的高阶数组和矩阵操作,Python成为科学计算应用的主流语言。
NumPy实现了多维同质数组和矩阵,这些数据结构不但能处理数字,还能存放其他用户自定义的记录,NumPy能高效处理这些数据
SciPy是基于NumPy的另一个库,它提供了很多跟科学计算有关的算法,专为线性代数、数值积分和统计学而设计
对numpy.ndarray的行和列进行基本操作:numpy并不是Python标准库的一部分,需要自行安装(pip install numpy)

(3)双向队列和其他形式的队列
利用.append和.pop方法,可以把列表当作栈或者队列来用。但删除列表的第一个元素(抑或是在第一个元素之前添加一个元素)之类的操作是很耗时的,因为这些操作会牵扯到移动列表里的所有元素
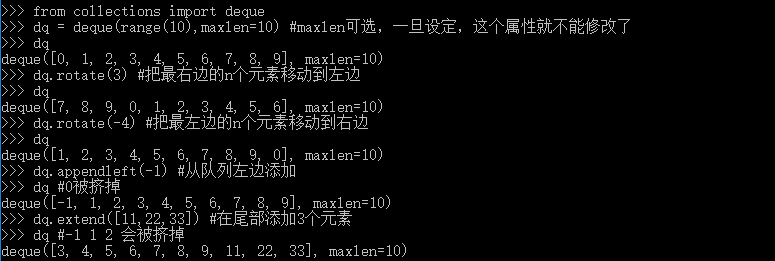
collections.deque类(双向队列)是一个线程安全,可以快速从两端添加或者删除元素的数据类型。如果想要有一种数据类型来存放“最近用到的几个元素”,deque也是一个很好的选择。因为指定队列大小后,队列满员可以从反向端删除过期的元素,然后在尾端添加新的元素
9.小结
要想写出准确、高效和地道的Python代码,对标准库里的序列类型的掌握是不可或缺的
Python序列类型分为扁平序列和容器序列时,前者的体积更小、速度更快而且用起来更简单,但是它只能保持一些原子性的数据,比如数字、字符和字节。容器序列则比较灵活
元组在Python里扮演了两个角色,它既可以用作无名称的字段的记录,又可以看作不可变的列表。当元组被当作记录来用时,拆包是最安全可靠地从元组里提取不同字段信息的方式。新引入的*句法让元组拆包的便利性更上一层楼,它可以选择性忽略不需要的字段
用户自定义的序列类型可以选择支持NumPy中的多为切片和省略。另外,对切片赋值是一个修改可变序列的捷径。
如果在插入X新元素的同时还想保持有序序列的顺序,需用到bisect.insort,bisect.bisect用作快速查找

 浙公网安备 33010602011771号
浙公网安备 33010602011771号