
20214304《Python程序设计》实验四 Python综合实践实验报告
20214304《Python程序设计》实验四 Python综合实践实验报告
课程: 《Python程序设计》
班级: 2143
姓名: 悦润柏
学号: 20214304
实验教师: 王志强
实验日期: 2022年5月21日
必修/选修: 公选课
一、实验内容
1.灵感来源:
读高中时期的一位语文老师,有一个收集摘录报纸内容的爱好,特别是人民日报。但从报纸上手写摘录报纸的工作太过于繁杂,而且随时代进步,用电子设备办公教学也逐渐普及,于是便想到了用一个简单的小爬虫程序来解决这个问题。
2.主要内容:
人民日报每天都会出版一份报纸,每份报纸中有若干个版面,每个版面有若干篇文章。目标是将这些文章全部爬取下来,按时间顺序分类并存储在本地。

二、实验过程及结果
1.前期资料准备
直接在浏览器中输入“爬取人民日报”等关键字。
找到如下文章进行学习:《Python 网络爬虫实战:爬取人民日报新闻文章》。链接如下:
2.实验过程
(1)爬取策略
第一遍,先爬取版面目录,将每一个版面的链接保存下来;
第二遍,依次访问每一个版面的链接,将该版面的文章链接保存下来;
第三遍,依次访问每一个文章链接,将文章的标。
(2)分析过程
a.URL组成结构
人民日报网站的URL的结构还是比较直观的,基本上什么重要的参数,比如日期,版面号,文章编号什么的,都在URL中有所体现,构成的规则也很简单,像这样:
版面目录
http://paper.people.com.cn/rmrb/html/2019-05/06/nbs.D110000renmrb_01.htm
文章内容
http://paper.people.com.cn/rmrb/html/2019-05/06/nw.D110000renmrb_20190506_5-01.htm
在版面目录的链接中,“/2019-05/06/” 表示日期,后面的“_01”表示这是第一版面的链接。
在文章内容的链接中,“/2019-05/06/” 表示日期,后面的“_20190506_5_01”表示这是2019年5月6日报纸的第1版第5篇文章
值得注意的是,在日期的“月”和“日”以及“版面号”的数字,若小于10,需在前面补“0”,而文章的篇号则不必。
了解到这个之后,我们可以按照这个规则,构造出任意一天报纸中人一个版面的链接,以及任意一篇文章的链接。
如:2018年6月5日第4版的目录链接为:
http://paper.people.com.cn/rmrb/html/2019-05/06/nbs.D110000renmrb_01.htm
2018年6月1日第2版第3篇文章的链接为:
http://paper.people.com.cn/rmrb/html/2018-06/01/nw.D110000renmrb_20180601_3-02.htm
b.分析网页HTML结构
在URL分析中,我们也发现了,网站的页面跳转是通过URL的改变完成的。也就是说,它的所有数据是一开始就加载好的,我们只需要去html中提取相应得数据即可。
按F12召唤出开发者工具。
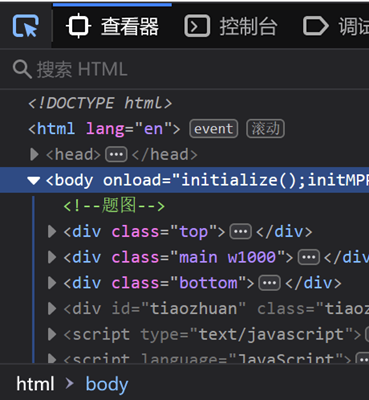
使用快捷工具。
(3)实验过程
a.代码
1 import requests 2 import bs4 3 import os 4 import datetime 5 6 # 其中,requests 库主要用来发起网络请求,并接收服务器返回的数据;bs4 库主要用来解析 html 内容,是一个非常简单好用的库;os 库主要用于将数据输出存储到本地文件中。 7 8 def fetchUrl(url): 9 ''' 10 功能:访问 url 的网页,获取网页内容并返回 11 参数:目标网页的 url 12 返回:目标网页的 html 内容 13 ''' 14 15 headers = { 16 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 17 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0', 18 } 19 20 r = requests.get(url, headers=headers) 21 r.raise_for_status() 22 r.encoding = r.apparent_encoding 23 return r.text 24 25 # fetchUrl 函数用于发起网络请求,它可以访问目标 url ,获取目标网页的 html 内容并返回。 26 # 这里其实是应该做异常捕获的(我为了简单就省掉了,吐舌头)。因为网络情况比较复杂,可能会因为各种各样的原因而访问失败, r.raise_for_status() 这句代码其实就是在判断是否访问成功的,如果访问失败,返回的状态码不是 200 ,执行到这里时会直接抛出相应的异常。 27 28 def getPageList(year, month, day): 29 ''' 30 功能:获取当天报纸的各版面的链接列表 31 参数:年,月,日 32 ''' 33 url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/nbs.D110000renmrb_01.htm' 34 html = fetchUrl(url) 35 bsobj = bs4.BeautifulSoup(html, 'html.parser') 36 temp = bsobj.find('div', attrs={'id': 'pageList'}) 37 if temp: 38 pageList = temp.ul.find_all('div', attrs={'class': 'right_title-name'}) 39 else: 40 pageList = bsobj.find('div', attrs={'class': 'swiper-container'}).find_all('div', 41 attrs={'class': 'swiper-slide'}) 42 linkList = [] 43 44 for page in pageList: 45 link = page.a["href"] 46 url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link 47 linkList.append(url) 48 49 return linkList 50 51 # getPageList 函数,用于爬取当天报纸的各版面的链接,将其保存为一个数组,并返回。 52 53 def getTitleList(year, month, day, pageUrl): 54 ''' 55 功能:获取报纸某一版面的文章链接列表 56 参数:年,月,日,该版面的链接 57 ''' 58 html = fetchUrl(pageUrl) 59 bsobj = bs4.BeautifulSoup(html, 'html.parser') 60 temp = bsobj.find('div', attrs={'id': 'titleList'}) 61 if temp: 62 titleList = temp.ul.find_all('li') 63 else: 64 titleList = bsobj.find('ul', attrs={'class': 'news-list'}).find_all('li') 65 linkList = [] 66 67 for title in titleList: 68 tempList = title.find_all('a') 69 for temp in tempList: 70 link = temp["href"] 71 if 'nw.D110000renmrb' in link: 72 url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link 73 linkList.append(url) 74 75 return linkList 76 77 # getPageList 函数,用于爬取当天报纸的某一版面的所有文章的链接,将其保存为一个数组,并返回。 78 79 def getContent(html): 80 ''' 81 功能:解析 HTML 网页,获取新闻的文章内容 82 参数:html 网页内容 83 ''' 84 bsobj = bs4.BeautifulSoup(html, 'html.parser') 85 86 # 获取文章 标题 87 title = bsobj.h3.text + '\n' + bsobj.h1.text + '\n' + bsobj.h2.text + '\n' 88 # print(title) 89 90 # 获取文章 内容 91 pList = bsobj.find('div', attrs={'id': 'ozoom'}).find_all('p') 92 content = '' 93 for p in pList: 94 content += p.text + '\n' 95 # print(content) 96 97 # 返回结果 标题+内容 98 resp = title + content 99 return resp 100 101 # getContent 函数,用于访问文章内容页,爬取文章的标题和正文,并返回。 102 103 def saveFile(content, path, filename): 104 ''' 105 功能:将文章内容 content 保存到本地文件中 106 参数:要保存的内容,路径,文件名 107 ''' 108 # 如果没有该文件夹,则自动生成 109 if not os.path.exists(path): 110 os.makedirs(path) 111 112 # 保存文件 113 with open(path + filename, 'w', encoding='utf-8') as f: 114 f.write(content) 115 116 # saveFile 函数用于将文章内容保存到本地的指定文件夹中。 117 118 def download_rmrb(year, month, day, destdir): 119 ''' 120 功能:爬取《人民日报》网站 某年 某月 某日 的新闻内容,并保存在 指定目录下 121 参数:年,月,日,文件保存的根目录 122 ''' 123 pageList = getPageList(year, month, day) 124 for page in pageList: 125 titleList = getTitleList(year, month, day, page) 126 for url in titleList: 127 # 获取新闻文章内容 128 html = fetchUrl(url) 129 content = getContent(html) 130 131 # 生成保存的文件路径及文件名 132 temp = url.split('_')[2].split('.')[0].split('-') 133 pageNo = temp[1] 134 titleNo = temp[0] if int(temp[0]) >= 10 else '0' + temp[0] 135 path = destdir + '/' + year + month + day + '/' 136 fileName = year + month + day + '-' + pageNo + '-' + titleNo + '.txt' 137 138 # 保存文件 139 saveFile(content, path, fileName) 140 141 142 def gen_dates(b_date, days): 143 day = datetime.timedelta(days=1) 144 for i in range(days): 145 yield b_date + day * i 146 147 148 def get_date_list(beginDate, endDate): 149 """ 150 获取日期列表 151 :param start: 开始日期 152 :param end: 结束日期 153 :return: 开始日期和结束日期之间的日期列表 154 """ 155 156 start = datetime.datetime.strptime(beginDate, "%Y%m%d") 157 end = datetime.datetime.strptime(endDate, "%Y%m%d") 158 159 data = [] 160 for d in gen_dates(start, (end - start).days): 161 data.append(d) 162 163 return data 164 165 166 if __name__ == '__main__': 167 ''' 168 主函数:程序入口 169 ''' 170 # 输入起止日期,爬取之间的新闻 171 beginDate = input('请输入开始日期:') 172 endDate = input('请输入结束日期:') 173 data = get_date_list(beginDate, endDate) 174 175 for d in data: 176 year = str(d.year) 177 month = str(d.month) if d.month >= 10 else '0' + str(d.month) 178 day = str(d.day) if d.day >= 10 else '0' + str(d.day) 179 download_rmrb(year, month, day, 'data') 180 print("爬取完成:" + year + month + day)
b.解释
requests库主要用来发起网络请求,并接收服务器返回的数据;bs4库主要用来解析 html 内容,是一个非常简单好用的库;os 库主要用于将数据输出存储到本地文件中。
def fetchUrl(url):
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
fetchUrl 函数用于发起网络请求,它可以访问目标 url ,获取目标网页的 html 内容并返回。
def getPageList(year, month, day):
功能:获取当天报纸的各版面的链接列表
参数:年,月,日
getPageList 函数,用于爬取当天报纸的各版面的链接,将其保存为一个数组,并返回。
def getTitleList(year, month, day, pageUrl):
功能:获取报纸某一版面的文章链接列表
参数:年,月,日,该版面的链接
getPageList 函数,用于爬取当天报纸的某一版面的所有文章的链接,将其保存为一个数组,并返回。
def getContent(html):
功能:解析 HTML 网页,获取新闻的文章内容
参数:html 网页内容
getContent 函数,用于访问文章内容页,爬取文章的标题和正文,并返回。
其中:
bsobj = bs4.BeautifulSoup(html, 'html.parser')
获取文章 标题
title = bsobj.h3.text + '\n' + bsobj.h1.text + '\n' + bsobj.h2.text + '\n'
获取文章 内容
pList = bsobj.find('div', attrs={'id': 'ozoom'}).find_all('p')
content = ''
for p in pList:
content += p.text + '\n'
返回结果 标题+内容
def saveFile(content, path, filename):
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
saveFile 函数用于将文章内容保存到本地的指定文件夹中。
其中:
如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
def download_rmrb(year, month, day, destdir):
功能:爬取《人民日报》网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
其中:
获取新闻文章内容
html = fetchUrl(url)
content = getContent(html)
生成保存的文件路径及文件名
temp = url.split('_')[2].split('.')[0].split('-')
pageNo = temp[1]
titleNo = temp[0] if int(temp[0]) >= 10 else '0' + temp[0]
path = destdir + '/' + year + month + day + '/'
fileName = year + month + day + '-' + pageNo + '-' + titleNo + '.txt'
保存文件
saveFile(content, path, fileName)
def get_date_list(beginDate, endDate):
获取日期列表
param start: 开始日期
param end: 结束日期
return: 开始日期和结束日期之间的日期列表
if __name__ == '__main__':
主函数:程序入口
输入起止日期,爬取之间的新闻
beginDate = input('请输入开始日期:')
endDate = input('请输入结束日期:')
data = get_date_list(beginDate, endDate)
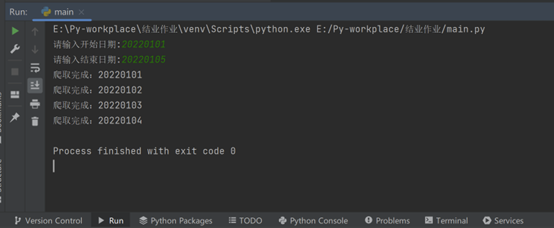
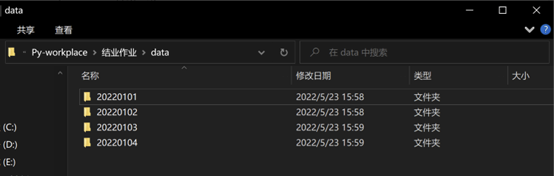
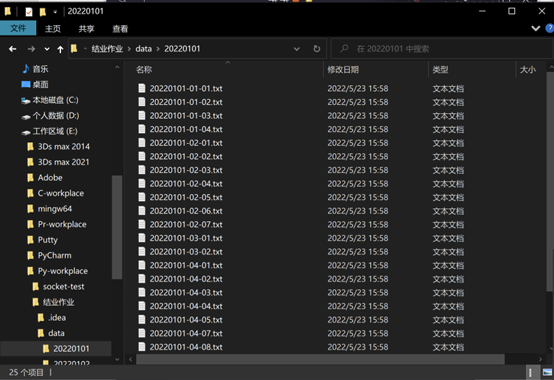
c.本地运行

d.在ECS服务器运行

首先要改掉保存地址

然后登陆PUTTY
上传代码文件
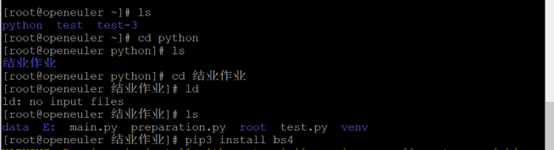
输入命令
安装bs4
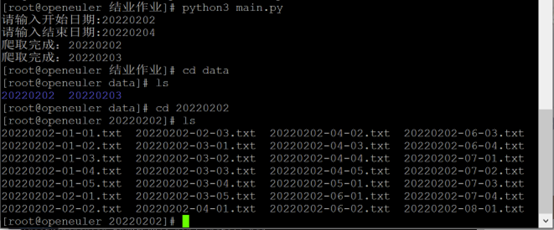
成功运行
四、遇到的问题和解决办法
1.无法获取正确的网址
在原文章中找到了新的代码解决该问题,通过定义的第一组代码来实现
2.无法将网址装入数组
没有正确调用requests库,并且忘记修改为'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0'
3.无法在ESC云服务器上用python3来运行程序
参考《Python(01):Python简介与Python安装》https://blog.51cto.com/u_15080014/4712399
4.无法正确下载bs4库
代码pip3 install bs4
误写作pip install bs4
5.上传代码后忘记修改保存地址
五、实验感悟
首先由衷感谢老师这一学期的教导,真的学到很多东西。
最初对python感兴趣,是在高中毕业的暑假,看到周围的同学都在学习编程,我便也在b站等地搜索了一些关于编程的资料。从这些资料中了解到,python是目前比较流行前卫的一种。于是就在www.python.org下载了python开始网上学习。可惜的是,暑假的繁杂事项较多,再加上没有学习编程的经验和方法,之了解到一些简单的浅层的理论知识。开学以后,我惊喜地发现在选修课列表中有该门课程,于是毫不犹豫的进行抢课,因此有幸和老师结识。报课之初,其实抱着水课的心态,但没有想到老师并未着重讲各种令人感到枯燥的理论知识,而是很快就进入了对各种python应用方面的讲述,例如正则表达式搜索,socket建立聊天功能,还有爬虫模块等都是很令人感兴趣的方面。
经过了短暂的不到一个学期的学习,虽然没有将老师所讲解的知识全部理解,但也有不小的收获。现在,这门课就要结束了,我很开心有这样一段经历,希望老师以后有机会可以继续指导,也希望自己能保持学习python这门编程语言的热情和兴趣。
参考资料:
[2]:《Python(01):Python简介与Python安装》https://blog.51cto.com/u_15080014/4712399

 浙公网安备 33010602011771号
浙公网安备 33010602011771号